A Random Walk Down Recsys - Part 6
Welcome back to the sixth installment of A Random Walk Down Recsys. This batch is smaller than the last — four papers — but two of them line up neatly enough that they deserve a side-by-side read:
- Industrial distillation pipelines — ByteDance’s Rec-Distill and Meta’s LoopFM are both attacking the same problem (transferring knowledge from an expensive teacher / foundation model into the production-serving vertical model), but they put the transfer interface in very different places.
- LLMs as auxiliary supervisors — Pinterest’s Fine-Tuned LLM as a Complementary Predictor and DoorDash’s Joint Optimization of Relevance and Engagement both use LLMs not to replace the ranker, but as a side channel — one as a retrieval-stage filter and an extra ranking signal, the other as a scalable annotator that feeds a multi-task ranker.
Neither of the two LLM papers breaks particularly new ground, but together with the two distillation papers they paint a coherent picture of where industrial recsys is investing right now: less new architecture, more plumbing to get bigger / smarter models to actually pay off at serving time.
Two Roads to Industrial Knowledge Distillation
Distillation in industrial recsys has converged on a fairly standard recipe — train a large teacher on rich data, expose its outputs as a soft label, and let the small online student consume those labels alongside ground truth. Meta’s earlier ExFM work codified a lot of this. The two papers below sit on top of that baseline and ask different follow-up questions:
- Rec-Distill (ByteDance) asks: if all the teacher gives us is a soft label, how do we make that pipeline robust and unbiased at industrial scale?
- LoopFM (Meta) asks: why limit ourselves to the final logits — can we hand the student the teacher’s intermediate activations as well?
Rec-Distill: Hardening the Soft-Label Pipeline (ByteDance)
Rec-Distill is, by the authors’ own framing, not architecturally radical — it’s close in spirit to Meta’s ExFM. What’s worth reading it for is the detail work around making a teacher–student pipeline run reliably in a streaming production environment.
Model Architecture
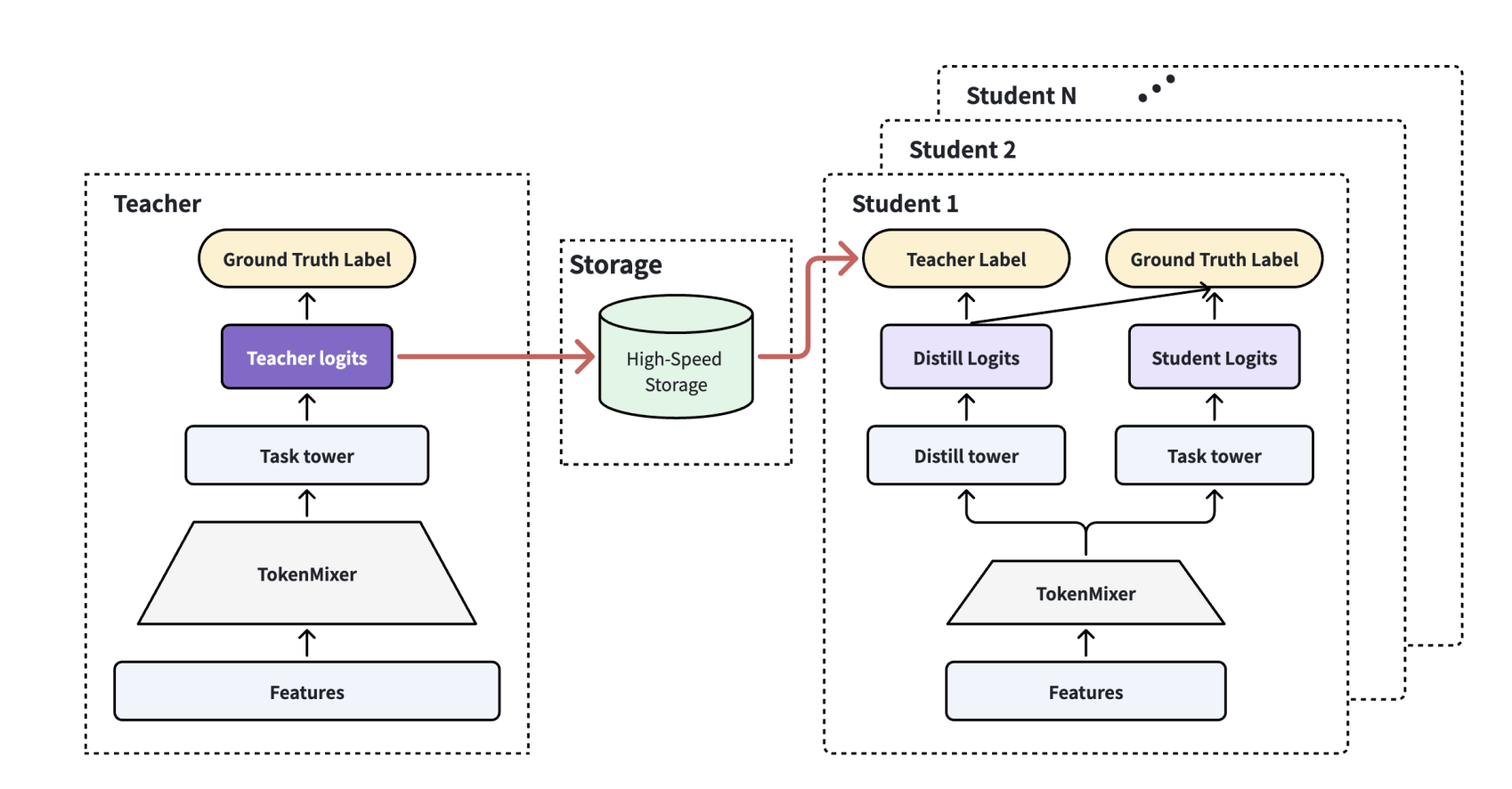
- The teacher is scaled using ByteDance’s prior TokenMixer stack, and its final prediction logits are exposed as the soft label.
- A naive
train-then-predictmode (train the teacher, then re-score the training set) introduces a leakage risk, so the authors instead record logits during the forward pass of teacher training itself. - The student uses a two-tower design: one tower learns the main task from ground-truth labels, the other tower is dedicated to distillation and trains on both the soft label and the ground truth. The paper claims this separation is more robust than mixing the two signals in a single tower.
- Crucially, teacher and student are fully decoupled, which is what makes independent iteration on either side practical at all.
Debiasing the Teacher Logits
The most interesting algorithmic detail is logit debiasing. The teacher’s training distribution typically differs from the student’s serving distribution (different sampling, different windows, different domains), and naively distilling on raw teacher logits propagates that mismatch into the student.
The fix uses domain-specific positive / negative sampling rates to rescale the teacher logits before they are consumed by the student, so the distilled signal is calibrated against the student’s actual operating distribution.
Systems: Streaming Joins and the Quiet Operational Risks
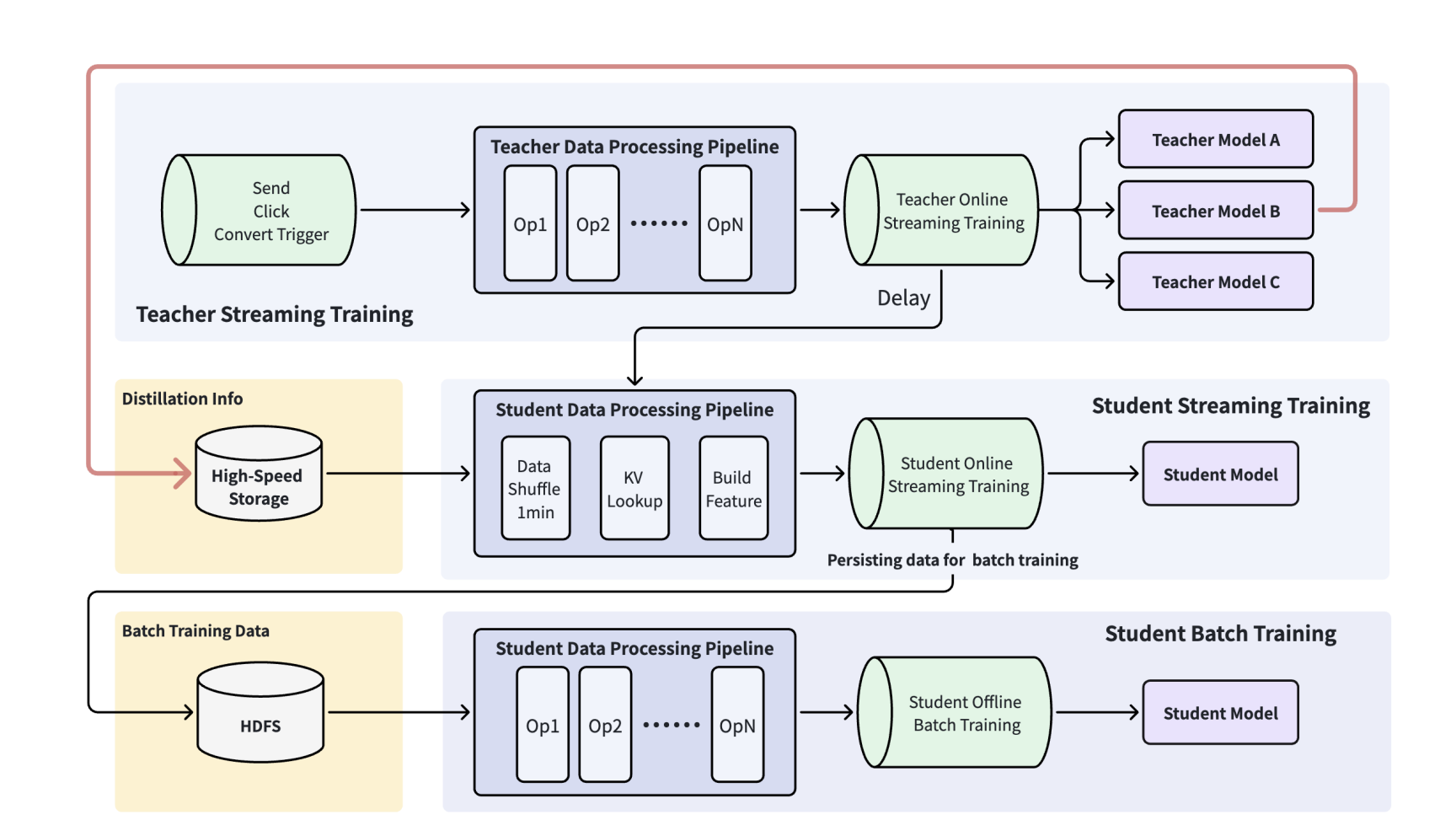
The serving / training infrastructure is a streaming pipeline that joins teacher online samples with teacher soft labels on the fly to form student streaming training data, with periodic snapshots to offline storage as a restart point for batch training. Nothing exotic on the surface.
But this is exactly the part of the paper that isn’t spelled out and that deserves more attention in practice:
- What happens when the teacher produces a bad snapshot? Do you need a cascading rollback on the student side, and how do you decide which student checkpoints to invalidate?
- If the upstream streaming pipeline goes down, how do you backfill the student? Naively resuming the distillation tower’s training after a long gap risks pulling the student’s distribution into a stale region of label space.
- How do you clean up partially-joined samples without biasing the resulting training set?
The paper doesn’t engage with these failure modes — but anyone trying to actually run this in production is going to spend most of their time there, not on the distillation loss itself.
LoopFM: Distilling Activations, Not Just Logits (Meta)
LoopFM takes a fundamentally different position on what “transfer” should mean. Instead of restricting the teacher–student interface to the final logits, LoopFM hands the intermediate activations of the foundation model (FM) directly to the vertical model (VM) as additional input features.
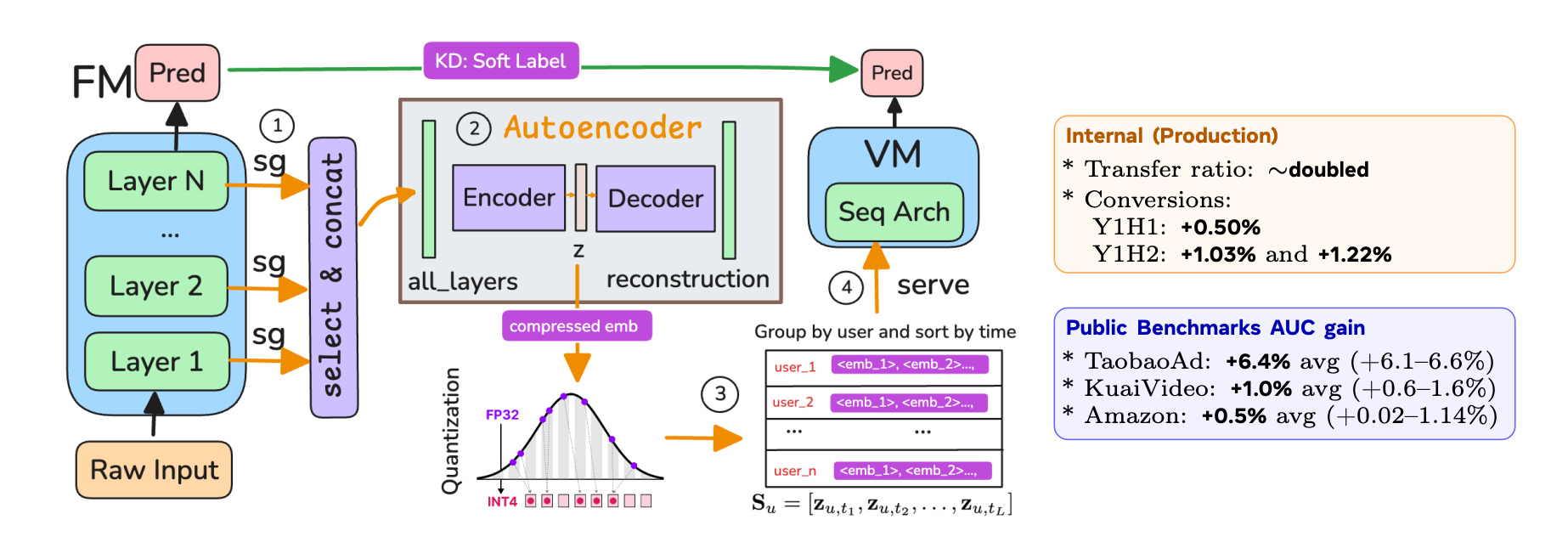
The mechanics are clean:
- A small number of FM layer activations are selected and concatenated.
- The concatenated activation is compressed by an autoencoder and then quantized to a code, which is what’s actually stored and shipped. To make the same code usable by VMs that want different embedding dimensions, the paper uses Matryoshka-style (“套娃”) embeddings so the code can be truncated cleanly at multiple widths.
- Activations are grouped by a key (e.g., a user / context identifier), and at serving time the VM just looks up the activation by key — no inline FM inference required.
What this gives you is a kind of activation cache as a feature store: the FM’s intermediate state becomes a precomputed, compressed, lookup-friendly signal that any vertical model can consume the same way it would consume an embedding feature.
Side-by-Side: Logits vs. Activations as the Transfer Interface
It’s useful to put the two papers next to each other:
| Dimension | Rec-Distill (ByteDance) | LoopFM (Meta) |
|---|---|---|
| Transfer interface | Final logits as soft label | Intermediate activations as extra input features |
| Student consumption | A dedicated distillation tower trained on soft labels + GT | Standard VM with activation lookups as additional features |
| Coupling between teacher and student | Decoupled (independent iteration) | Decoupled at serving (precomputed cache), tighter at training (VM must consume the FM’s representation) |
| Key engineering concern | Logit debiasing across teacher/student distributions, plus streaming join robustness | Compression + quantization + Matryoshka to make activations cheap to store and serve |
| Failure modes the paper addresses | None of the streaming failure modes explicitly | Storage / dimension flexibility |
| Failure modes likely to matter in production | Bad teacher snapshots, streaming gaps, backfill of distillation tower | Stale activations when the FM is retrained, schema drift in the activation key |
The two papers converge on the same diagnosis — small online models leave a lot of value on the table without help from a much bigger model — and disagree on what bandwidth of help to give the student:
- Rec-Distill gives the student a single scalar per example (the logit) and invests its energy in making that scalar trustworthy across distributions and pipeline failures.
- LoopFM gives the student a dense vector per example and invests its energy in making that vector cheap to store, ship, and serve.
If you can afford the storage and you trust your FM’s representations to be stable across retrains, LoopFM’s interface is strictly richer. If you can’t — or your teacher is updated more aggressively than the VM is — Rec-Distill’s logit-only interface is more forgiving, but you’ll spend the saved storage budget on debiasing and on plumbing for streaming failure modes that the paper doesn’t address.
A reasonable production stance is probably to combine the two: ship the FM’s activation as a feature and use the FM’s logit as a calibrated soft label, picking the per-vertical mix based on which interface is more stable for that vertical.
Fine-Tuned LLM as a Complementary Predictor (Pinterest)
This paper lands in the “useful as a reference architecture, not as a research contribution” bucket. The headline idea is to use an open-source LLM’s world knowledge to generate candidate advertisers a user is likely to interact with, then use that LLM output in two places:
- As a filter / conditional in the retrieval stage.
- As an additional signal fed into the downstream conversion model.
Most of the components are standard industrial moves:
- User selection is applied upstream to cap daily inference load — the LLM isn’t being run for every user, every request.
- The inference stack is vLLM + Ray, which is a natural fit for Pinterest’s existing Ray-based infrastructure.
- Prompts are hard-coded templates — no learned prompting.
- The SID integration is essentially the same recipe as OneSearch (and is the same approach I used when building Jobs GR at LinkedIn): borrow the tokenization and integration pattern from OneSearch and adapt it to the vertical.
The only piece worth lingering on is the GRPO reward design, which is reasonable but not surprising. There is nothing here that meaningfully changes how you’d design a retrieval-side LLM augmentation today, but it is a clean writeup of what a production team’s first-cut version of this system looks like, and it’s useful as a sanity check for anyone building something similar.
Joint Optimization of Relevance and Engagement (DoorDash)
DoorDash’s paper attacks a real but well-trodden problem: in search ranking, engagement signals are abundant but relevance signals are scarce, and human labeling doesn’t scale. Their proposed answer — fine-tune an LLM to act as a scalable relevance annotator and feed its labels into a multi-task ranker — is the now-standard playbook.
The setup has two notable pieces:
- Multi-task ranker: in addition to engagement heads, the model has a dedicated relevance head. Relevance is bucketed into three levels (0 = irrelevant, 1 = relevant, 2 = highly relevant), and the head outputs $P(k \geq 1)$ and $P(k \geq 2)$ as two ordinal predictions.
- Annotation pipeline: start from a human-annotated dataset, compare its labels against actual user engagement signals, and when the two conflict, use an LLM via prompting to resolve the disagreement. The resulting cleaned dataset is used to fine-tune GPT-4o-mini, which is then run over ~100M samples to produce the relevance labels that train the ranker.
The resolve-conflicts-with-an-LLM step is the only piece I’d flag as worth borrowing — it’s a pragmatic way to get a higher-quality training set for the annotator without paying for another full round of human labeling. Everything else here is straight off the shelf.
Key Takeaways
Distillation pipelines are converging — but on different interfaces. The teacher–student question in industrial recsys is no longer “should we distill?” but “what should we transfer?” Logits are cheap, robust, and easy to calibrate across distributions (Rec-Distill). Activations are richer but require a real compression / serving story (LoopFM). The interesting design space is combining the two: a logit soft label for calibration and an activation cache for feature richness, mixed per vertical.
Most of the production risk in distillation is in the streaming pipeline, not the loss. Rec-Distill describes the happy path of a streaming teacher → student join, but says little about bad teacher snapshots, upstream outages, backfill behavior of the distillation tower, or cleanup of partially-joined data. In practice this is where most of the on-call time goes, and it deserves more attention in published industrial pipelines.
LLMs are quietly settling into “side channel” roles in recsys. Neither the Pinterest nor the DoorDash paper uses an LLM to replace any core component — they use it as a retrieval-stage augmenter or a scalable annotator that feeds a conventional ranker. This is probably the right shape for most production teams right now: keep the online ranker boring and cheap, and let LLMs upgrade the inputs (features, candidates, labels) that flow into it.
“Resolve conflicts with an LLM” is becoming a default labeling pattern. DoorDash’s setup — use human labels and engagement signals together, route disagreements through an LLM, fine-tune a smaller LLM on the cleaned-up corpus, then annotate at scale — is a useful template. The novelty is mild but the engineering pattern is clean enough that it’s worth copying when you need to bootstrap an annotator without ballooning the human labeling budget.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.