A Random Walk Down Recsys - Part 5
Welcome back to the fifth installment of A Random Walk Down Recsys. This batch of papers reflects how quickly the generative recommendation playbook is being adapted to new verticals and tightened for production. Six papers, four themes:
- Generative Recommendation for Ads — two concurrent works, one from Kuaishou and one from Tencent, both attacking the same gap: today’s GR systems are heavily user-side optimized, and commercial-value signals (bid, eCPM, advertiser objectives) need first-class treatment.
- Generative Recommendation for Search — Kuaishou’s OneSearch-V2 layers reasoning-augmented query understanding and a structure-aware GRPO on top of their generative retrieval stack.
- On-Device Recommendation — Taobao’s RecGPT-Mobile sketches a hybrid edge/cloud architecture with an on-device intent agent that triggers only when user intent shifts meaningfully.
- Serving and Expressiveness — “One Pool, Two Caches” rethinks HBM allocation between the embedding cache and the KV cache, and a Snap paper highlights a structural limit of autoregressive SID decoding and patches it with a latent personalization token.
The six papers covered are: Generative Recommendation for Large-Scale Advertising (Kuaishou), Unified Value Alignment for GR in Industrial Advertising (Tencent), OneSearch-V2 (Kuaishou), RecGPT-Mobile (Taobao), One Pool, Two Caches, and Expressiveness Limits of Autoregressive SID Generation (Snap).
Generative Recommendation Meets Ads
The first two papers are interesting to read side-by-side. Both come from large industrial ads platforms (Kuaishou and Tencent), both target the same blind spot — current GR systems mainly optimize the user-side relevance objective, while the commercial value half of the marketplace (advertiser bid, eCPM, monetization) is largely an afterthought — and both arrive at remarkably similar high-level designs: compress commercial signals into SID-adjacent tokens, add a value-aware learning objective on top of NTP, and use RL to align with business KPIs. The implementation details, however, diverge in interesting ways.
Generative Recommendation for Large-Scale Advertising (Kuaishou)
This paper extends Kuaishou’s OneRec-style stack into the ads domain. The SID generation itself is fairly standard — MLLM finetuning with collaborative signal injection via in-batch negatives + InfoNCE — but several touches are worth highlighting.
Variable-Length Codebook with eCPM Token
The codebook design uses a variable-length RQ structure, and to keep the last codebook well-balanced they bypass learning entirely and use a hash of the raw item ID as the final SID slot. The most interesting addition is an eCPM token appended to the SID sequence — the model is asked to learn to decode this commercial-value token alongside the regular semantic tokens, giving the generation process direct visibility into the monetization objective.
MTP-Inspired Prefill / Autoregressive Split
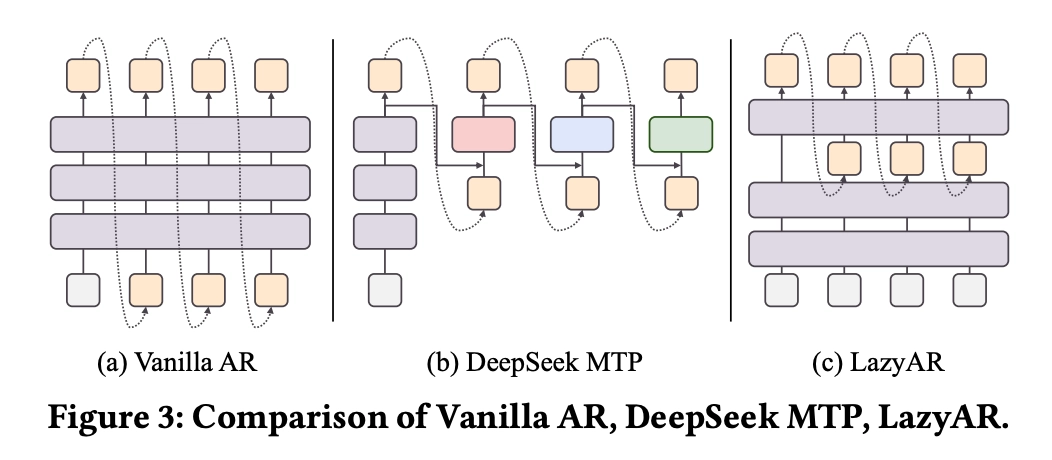
The backbone follows OneRec v2, but borrows the spirit of Multi-Token Prediction (MTP) without introducing a separate MTP block. In the decoder, the front $K$ layers takes the output of prefill, and only the back $L - K$ layers run autoregressive decoding. The justification is twofold:
- The structural prior of SID — earlier tokens carry coarser, more decisive semantics, so they deserve more shared compute.
- During beam search, the number of active beam paths grows over decoding steps, so concentrating autoregressive compute in the back layers naturally allocates more compute where it is actually needed.
Value-Supervised Training and Lambda-NDCG RL
Training combines three losses:
- The traditional NTP loss on SID tokens.
- An eCPM prediction loss as an additional decode step.
- An auxiliary MTP loss, conceptually similar to the one in DeepSeek’s MTP design.
The RL stage breaks from the typical pointwise reward formulation and instead computes reward at the list level using NDCG, with a Lambda-style assignment of pairwise gradients. This matches how ads slates are actually evaluated in production.
Beam-Shared KV Cache
On the serving side, two efficiency tricks stand out:
- Dynamic Beam Width to balance compute across requests.
- Beam-Shared KV Caching: beams are organized along the sequence dimension so that multiple beams share a single encoder KV cache. This eliminates redundant memory accesses and reduces per-step KV read complexity from $O(B \cdot L)$ to $O(L)$.
Unified Value Alignment for GR in Industrial Advertising (Tencent)
Tencent’s paper frames the same problem — commercial value as a first-class GR objective — but takes a different architectural and training route.
Commercial Special Token in the SID
SID generation uses RQ-KMeans for the semantic part, and then appends a commercial special token that compresses attribute, industry category, and bid information into a single token:
- For attribute / industry, data mining is used to reduce the overall category cardinality before tokenization.
- For bid, the authors construct compositional keys from the attributes and aggregate the resulting bid distribution per key.
This is a more principled counterpart to Kuaishou’s eCPM token: instead of just predicting the monetization signal, Tencent encodes the commercial state of the ad directly into the input vocabulary.
MoR Backbone and Dual-Head Decoding
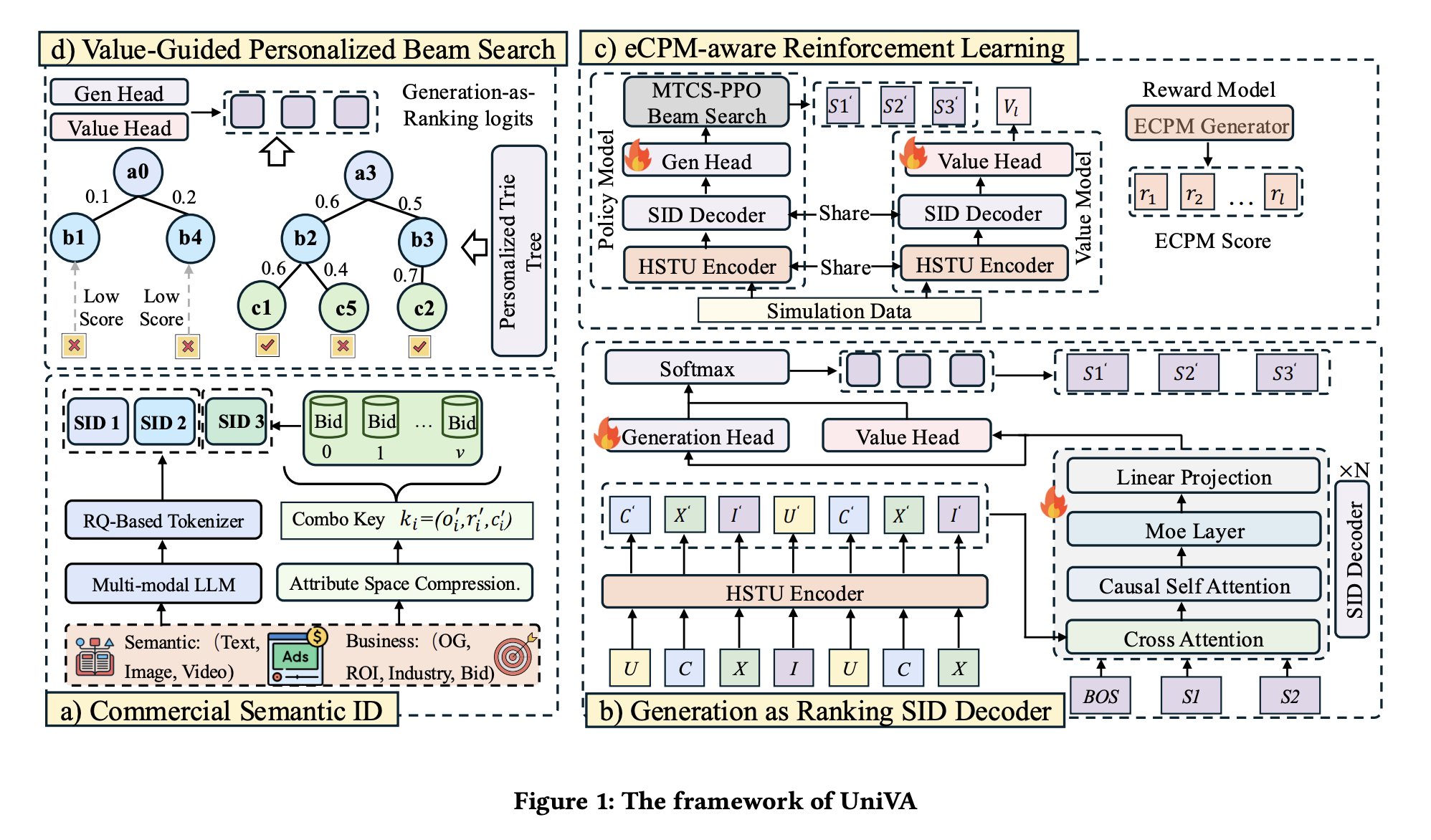
Two architectural choices stand out:
- Mixture-of-Recursions (MoR): the same middle layer block is applied multiple times, in the spirit of a loop transformer. This deepens effective compute without proportional parameter growth.
- Dual Head: two output heads sit on top of the backbone — a generation head producing vocab logits, and a value head producing per-token value scores. The two scores are summed before the final softmax, so value information directly biases token selection rather than being a downstream re-ranker.
SL + RL Co-Training with Simulated Rollouts
Training combines supervised generation-head training with an RL loop driven by simulation:
- The current generation head acts as the reference policy.
- Rollouts are produced jointly via beam search and MCTS-PPO.
- The value head plays the role of the critic, with its target estimated via GAE and trained with an MSE loss.
- The final RL objective is a weighted combination of the PPO loss and the critic loss, jointly optimized with the SL signal.
Personalized Trie at Serving
At inference time, instead of a single global trie, Tencent builds a personalized trie per request — though the personalization here is largely heuristic:
For an incoming request, serving constraints such as targeting, availability, and creative rules are applied to derive a personalized subtree.
In practice this means business rules carve out a request-specific decoding subtree before constrained beam search runs over it.
Side-by-Side: Two Roads to Value-Aligned GR
It’s worth pausing on the parallels and contrasts:
| Dimension | Kuaishou (GR for Large-Scale Ads) | Tencent (Unified Value Alignment) |
|---|---|---|
| Commercial signal | eCPM token appended to SID, predicted as an additional decode step | Commercial special token encoding attribute/industry/bid, baked into the SID itself |
| Architecture | OneRec v2 backbone with MTP-style prefill / AR layer split | MoR (loop-transformer style) backbone with dual head (generation + value) |
| Value learning | Auxiliary MTP loss + eCPM prediction loss | Value head trained as a critic via GAE + MSE |
| RL formulation | List-level Lambda-NDCG reward | PPO + critic with simulated beam-search / MCTS-PPO rollouts |
| Serving | Beam-shared KV cache + dynamic beam width | Personalized trie per request driven by business rules |
The two papers converge on the same diagnosis (GR needs explicit commercial-value treatment) but disagree productively on where to inject it — Kuaishou pushes it into the decode objective and serving stack, Tencent pushes it into the vocabulary and the head architecture. Both are likely to be useful reference points for anyone building a GR-based ads system in the next year.
OneSearch-V2: Reasoning-Enhanced Generative Search
OneSearch-V2 is Kuaishou’s follow-up to OneSearch, and the headline updates are:
- A reasoning-enhanced query understanding module.
- Reasoning-enhanced self-distillation to keep latency in check at serving time.
- An improved GRPO that exploits the structural information inside SID itself.
Quantization Comparison and Reasoning-Enhanced QU
The paper first benchmarks three flavors of RQ-OPQ-derived SID:
- Unimodal, multimodal, and keyword-hierarchy quantization.
The somewhat counterintuitive finding is that multimodal performs the worst, while keyword-hierarchy (folding item-keyword embeddings into the quantization process) performs the best. This is a useful empirical data point — and one we are also planning to try.
For query understanding, the authors use an LLM to generate a CoT reasoning trace, then compress that trace down to keyword form. A new CoT task is added to SFT Stage 1 (Semantic Alignment), and the resulting reasoning keywords are used as additional training signal:
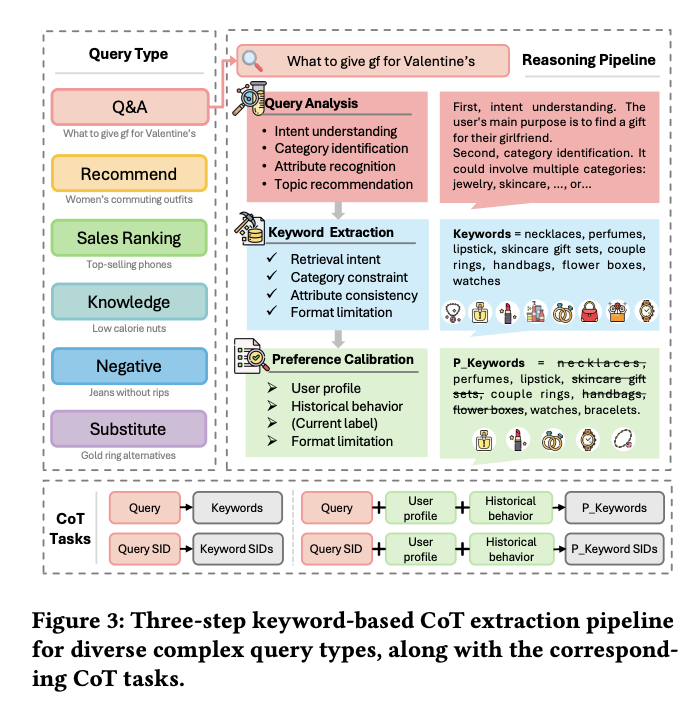
Training Paradigm Refinement. The resulting ⟨query, keywords⟩ tuples from Step 2 and ⟨query, user, keywords⟩ tuples from Step 3 collectively constitute the training corpus. We then incorporate four CoT tasks (shown above) into the SFT Stage 1 (Semantic Alignment Procedure) of OneSearch-V1.
Self-Distillation to Cut Reasoning Latency
If serving had to first emit the CoT keywords and then the SID, latency would be unacceptable. The fix is self-distillation with parameter sharing: teacher and student share weights, but only the teacher sees the CoT keyword inputs. The student is then distilled against the teacher’s logits on the target SID.
The challenge is that without keywords, the student is prone to collapse during distillation under random perturbations. The paper layers in additional regularizers to stabilize training:
- R-Drop.
- Adversarial Perturbation.
The exact recipe is fairly involved and I’ll defer to the paper for the full details.
Structure-Aware GRPO
The final RL stage drops the previous reward-model approach (which suffers from selection bias inherited from the reward model’s own training data) and instead designs reward directly from user signals:
- Relevance Reward.
- Posterior Conversion Reward.
- Click and Order Score.
The bigger conceptual change is to GRPO itself. In standard GRPO, every token in a generated sequence gets the same advantage. But SID is structurally hierarchical — earlier SID tokens are more decisive, since they cut off entire subtrees of the catalog. So OneSearch-V2 reweights advantages by SID level, and adds a prefix gate: if the very first token is wrong, downstream tokens receive zero learning signal because their reward is essentially noise.
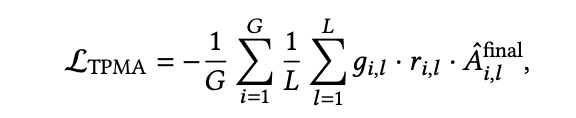
Here $g$ is the prefix gate, $r$ is the importance ratio, and the final advantage $A$ is a weighted combination of an item-level advantage and an SID-token-level advantage.
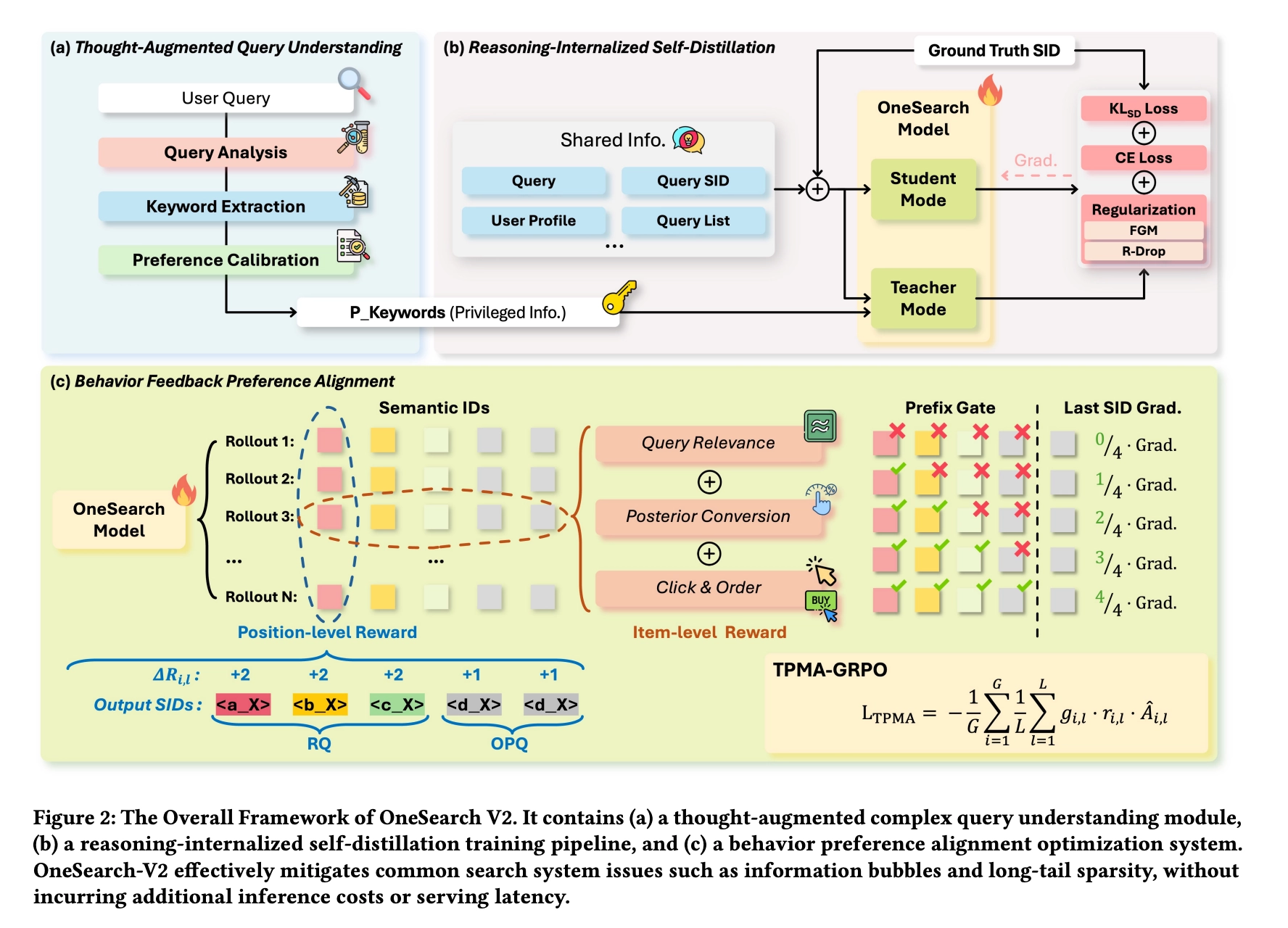
The combination of structure-aware advantage shaping and a hard prefix gate is a clean way to bake the SID prior into RL, and feels like an idea that could transfer to other generative retrieval / recommendation stacks.
RecGPT-Mobile: On-Device Recommendation with an Intent Agent
RecGPT-Mobile from Taobao is an interesting design point that I’ve personally been thinking about for a while. As edge compute keeps growing and small models keep improving, I expect this kind of hybrid edge/cloud architecture to become mainstream for recommendation, not just for chat.
Architecture
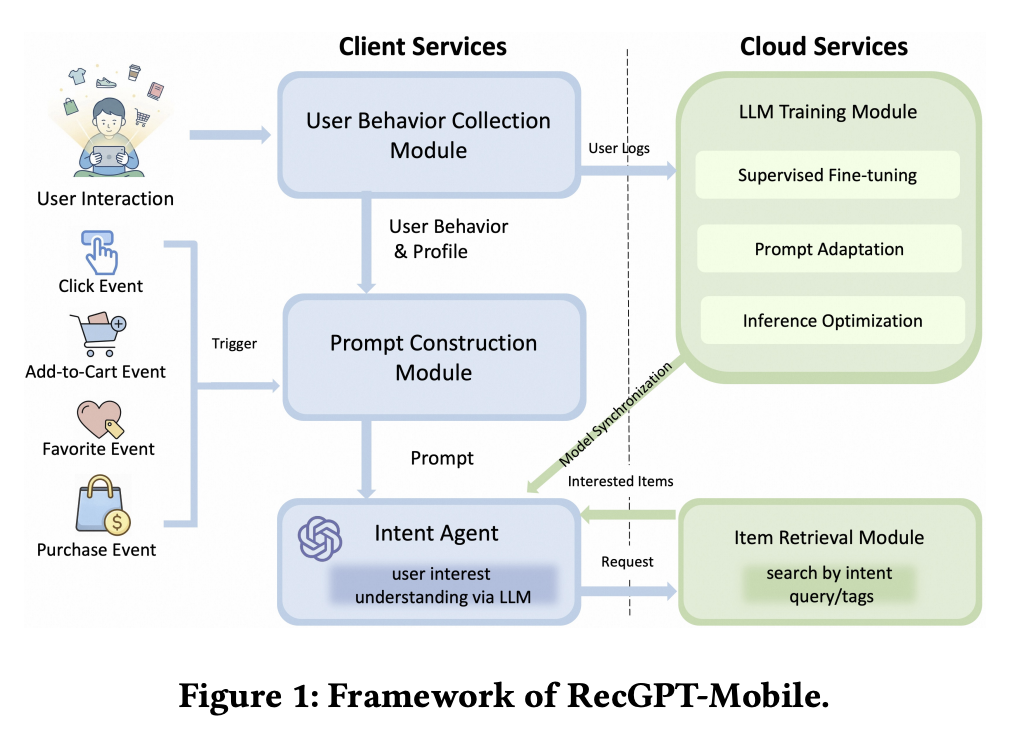
The split is: behavior signals are collected on the device, prompt construction happens on the device, an on-device intent agent turns those into a query, and the actual item retrieval and ranking happen in the cloud. Training also stays in the cloud, with model parameters synced down to the device.
This keeps the heavy lifting (large indices, ranking models, training) on the server while giving the user experience the immediacy of locally available context.
Prompt Construction
This is arguably the most novel part of the paper. Rather than using a single fixed prompt, RecGPT-Mobile builds the prompt from a library of templates, ranks candidate templates against the current user signals, and incrementally refines the prompt under the device’s resource budget:
Candidate structural components are evaluated according to their marginal utility gain, and only those that contribute positively while satisfying the on-device budget constraints are incorporated into the prompt.
A constrained validation pass is then run before the chosen template is instantiated and handed to the on-device LLM.
Intent Agent: Triggering Only When It Matters
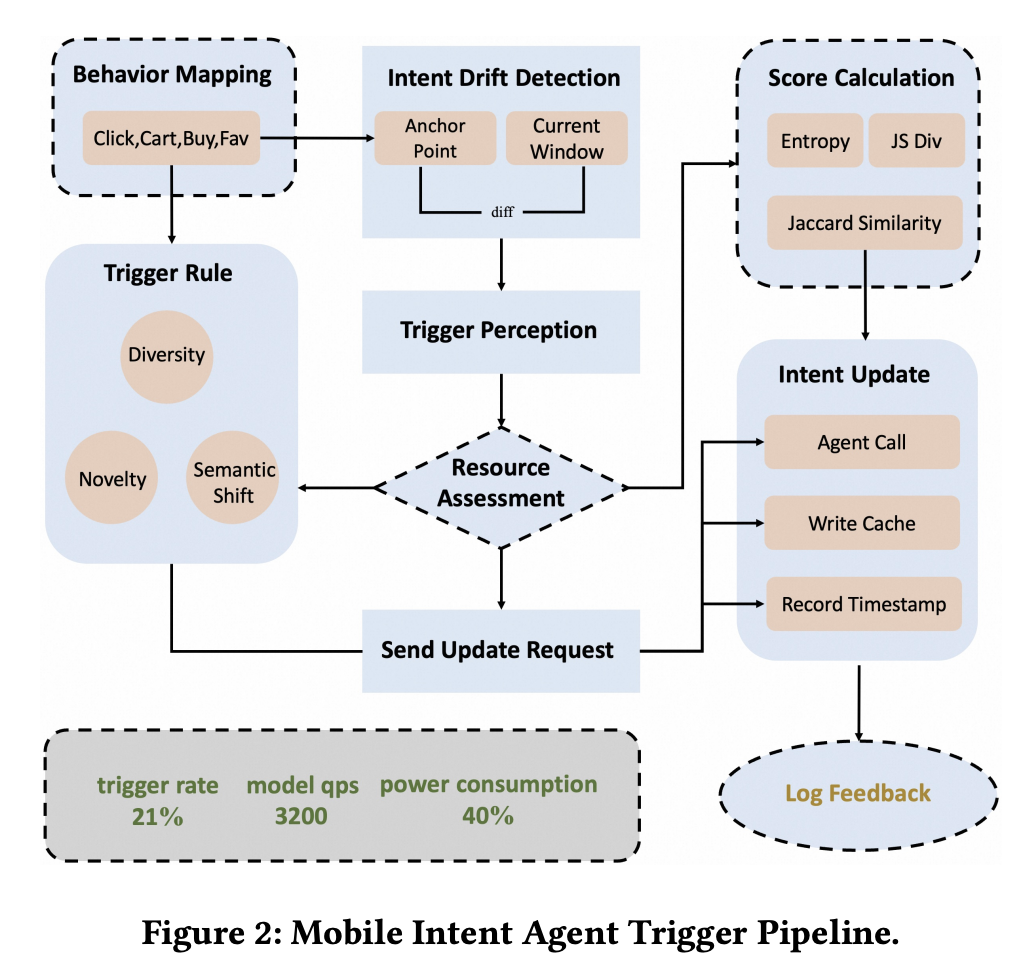
The intent agent is essentially an on-device user-understanding component. To balance quality against battery and compute, it only invokes the LLM when the user’s intent has changed materially. The detection pipeline:
- The user’s behavior sequence is mapped onto a tag distribution.
- Statistical features are computed over that distribution and tracked across time — the paper uses entropy, Jaccard similarity, and Jensen-Shannon divergence as detectors.
- Only when those metrics cross a threshold does the LLM actually run.
The combination of statistical change detection with an LLM-based agent is a pragmatic blueprint that I think generalizes well beyond e-commerce.
One Pool, Two Caches: Dynamic HBM Allocation for GR Inference
This paper zooms in on a serving-side problem in generative recommendation: GPU HBM is a single resource pool, but two large consumers compete for it.
Using HSTU as the running example, the two consumers are:
- Embedding lookup tables — too large to live entirely on HBM, so they are sharded onto host RAM with a hot-ID cache on HBM.
- KV cache — used to reuse computed key/value states across user requests.
The paper argues that the conventional approach of statically partitioning HBM between these two caches is suboptimal, and proposes a dynamic allocation strategy. That immediately raises three sub-problems.
Deciding the Split with RL
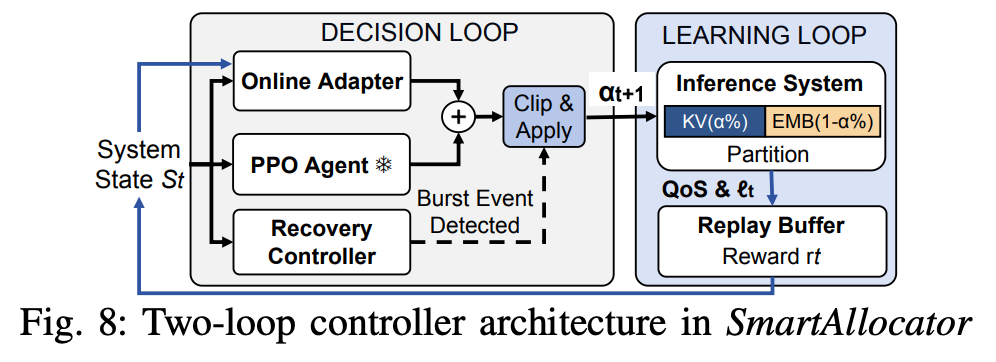
The first question is: how do we decide how much HBM to give each cache, and when to rebalance? The paper trains an RL policy whose state is built from server-node telemetry — hot-user ratio, KV hit rate, and friends — and whose action space is a small set of discrete shift sizes. The reward combines SLO satisfaction with a p99-latency penalty, so the policy learns to push for higher cache hit rates without blowing tail latency.
Realizing the New Allocation Without Disturbing Inference
Once the policy decides on a new split, you have to actually move the boundary on a live server. The paper takes two careful steps to avoid corrupting in-flight requests:
- Only the embedding cache boundary is moved. The KV cache is managed via a paged KV cache (so its memory is naturally chunked and reusable), while the embedding cache is managed as LRU. When the embedding share grows, it pulls free pages from the KV-cache pool; when it shrinks, it evicts and
free_pages back. - Cache refill runs on a dedicated high-priority CUDA stream rather than the default compute stream, so reshaping the cache doesn’t stall actual inference kernels.
Heterogeneity-Aware Scheduling
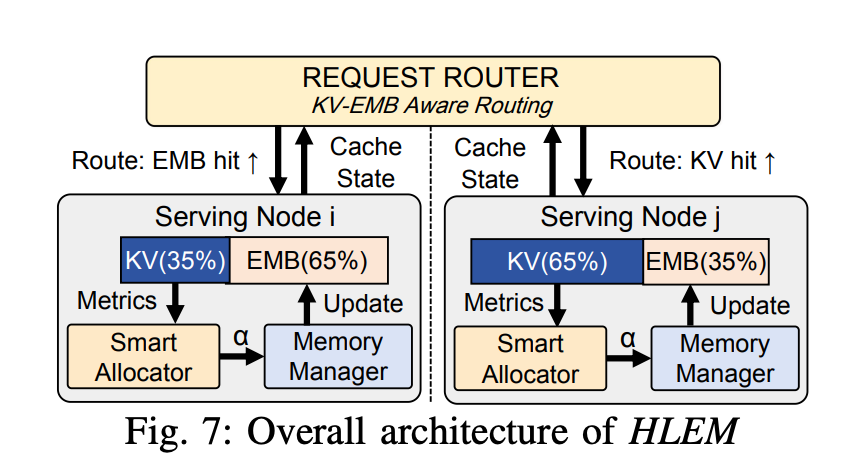
Once different servers are running with different cache splits, the fleet is no longer homogeneous — the same request will be served at different speeds depending on which cache split happens to be a better fit. The scheduler is therefore updated to be aware of per-server cache configuration, so requests are routed to the host most likely to keep them within SLO.
The whole package is a nice reminder that GR serving optimization is increasingly a systems problem, not just a model-architecture one.
Expressiveness Limits of Autoregressive SID Generation (Snap)
This short paper from Snap puts a finger on a structural limitation of autoregressive SID decoding in generative recommendation: because SID lives on a tree, the probability of reaching a particular leaf is dominated by the leaf’s depth and prefix, not by per-user personalization signals.
The paper has a fair amount of math to formalize this; I’ll skip past the proof and focus on the proposed fix.
Fix: Prepend a Latent Personalization Token
The remedy is simple and elegant:
- Maintain a small latent token vocabulary.
- During training, randomly sample a latent token and prepend it to the SID sequence.
- During inference, let the model freely generate the latent token at the front of the sequence with no constraints.
In effect this gives the decoder a free “soft bucket” at position zero that it can use to inject personalization before committing to a coarse semantic prefix. Conceptually this is very close to the geo-filter / user-bucket prepend ideas that are floating around in industry — a simple categorical conditioning hook that turns out to do real work in fixing the leaf-distribution skew of tree-structured decoding.
Key Takeaways
GR is rapidly expanding into ads and search. The two ads papers from Kuaishou and Tencent are early but consistent signals: generative recommendation is moving past organic-feed retrieval and being adapted to verticals where the non-user-side objective (advertiser value, monetization) needs first-class treatment. Both inject commercial signals into SID-adjacent tokens, but they diverge in where the value learning lives — Kuaishou puts it in the decode objective and serving stack, Tencent puts it in the vocabulary and head architecture.
Structure-aware learning is becoming a recurring motif. OneSearch-V2’s GRPO upgrade — token-level advantage shaping by SID level plus a prefix gate — is a clean instance of a broader pattern: SID has a hierarchy, and training objectives that ignore that hierarchy waste signal. Expect to see more architectures and losses that explicitly encode the SID prefix structure.
Inference economics are catching up to model architecture. Beam-shared KV cache, dynamic HBM allocation between embedding and KV caches with RL-based control, dedicated CUDA streams for cache refill, heterogeneity-aware scheduling — these are systems-level wins that often deliver more headline impact than another point of NDCG. GR serving is squarely in the territory where ML and systems engineering need to be co-designed.
Edge-side recommendation is a real architectural option. RecGPT-Mobile’s hybrid design, with on-device prompt construction and an intent agent that fires only on meaningful intent shifts, is a practical sketch of where mobile-first recommendation is heading. The combination of statistical change detection + small on-device LLM + cloud retrieval is likely to generalize well beyond e-commerce.
Personalization injection can be lightweight. Snap’s latent-token fix for SID expressiveness is a good reminder that not every personalization gain requires a new backbone or a new training paradigm — sometimes a single learnable bucket prepended to the sequence is enough to recover signal that the tree structure was suppressing.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.