Recsys Paper Summary 2025 Q1
In this post, I would like to provide a simple summary on the papers I have read in the first quarter of 2025 and discuss some of my thoughts on recent trend regarding recommendation system. Here is the full list of papers in this summary, which are all available on Arxiv:
- Full-Stack Optimized Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
- NoteLLM-2: Multimodal Large Representation Models for Recommendation
- Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
- Bridging Textual-Collaborative Gap through Semantic Codes for Sequential Recommendation
- Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation
- Diffusion Model for Interest Refinement in Multi-Interest Recommendation
- External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
- LLM-Alignment Live-Streaming Recommendation
Recently, there is a trend that tries to integrate diffusion process into user sequential behavior modeling which is a new idea to me. Besides that, I’m also seeing an increased trends on utilizing semantic ids (if you are not familiar with this concept, please refer this section from my pervious post) to improve the training or serving efficiency. How to better utilize both the semantic embeddings (from LLM or VLM) and id embeddings (from collaborative signals) continuous to be a hot area. And distillation has been drawing eyeballs not only in small LLM, but also in industry to help reduce the inference pressure incurred from larger models.
Diffusion
Probably everyone today is already familiar with stable diffusion. It is a popular technique used for image generation in recent years and powers website such as Midjourney. Due to there strong abilities to model data distribution and generate high-quality items, diffusion models have also been adopted for sequential recommendation.
Distinguished Quantized Guidance for Diffusion-based Sequence Recommendation
In this work from Kuaishou, a famous Chinese company in short video/live recommendation track, the author proposed some augmentation to how diffusion model is being applied to sequential modeling. Traditionally, noise is added to the next item and user’s interaction sequence is used to progressively denoise it. But user’s interaction sequence usually contains some noisy items due to stochastic user behaviors, or the sequence could be pretty sparse (a.k.a short) to provide meaning information to the denoise process, which would hind this denoise process. One solution proposed in this work is to use vector-quantization to encode and augment the original user sequence.
Given a user behavior sequence $s = [x_{1}, x_{2}, \dots, x_{L-1}] \in R^{(L-1) \times D}$, which we have already converted the item id to the item embedding; we would match against to a semantic codebook which is defined as $C = \{ c_m \}$, and $c_m \in R^{(L-1) \times D}$. To find $m^*$ that best matches the to the original input, sampling from predicted vector distribution approach is used. In this approach, $s$ is feed into a MLP to generate logits of size $M$ (corresponding to the dimension of cookbook) and then Gumbel-Softmax technique (pretty similar to softmax with temperature, to resolve the in-differential problem of argmin) is used to find $m^*$. Then the quantized sequence is defined as $s_{q} = c_{m}$ and combined with origin input sequence $s$ with a controllable rate. The codebook is also trained via expectation-maximization approach, which is a commonly used optimization algorithm for such clustering-alike process. During the training process, we would update $c_i$ using the average of all $s$ that is assigned with $i$-th codebook. The picture below highlights the overall process of this vector-quantization. Through this process, we reduce the noise in the original sequence by dragging it towards a more common representation across the entire user space (similar to a cluster centric, all user that assigned to the same codebook belongs to certain pattern); as well as using this common representation to augment for the sequence that is sparse.
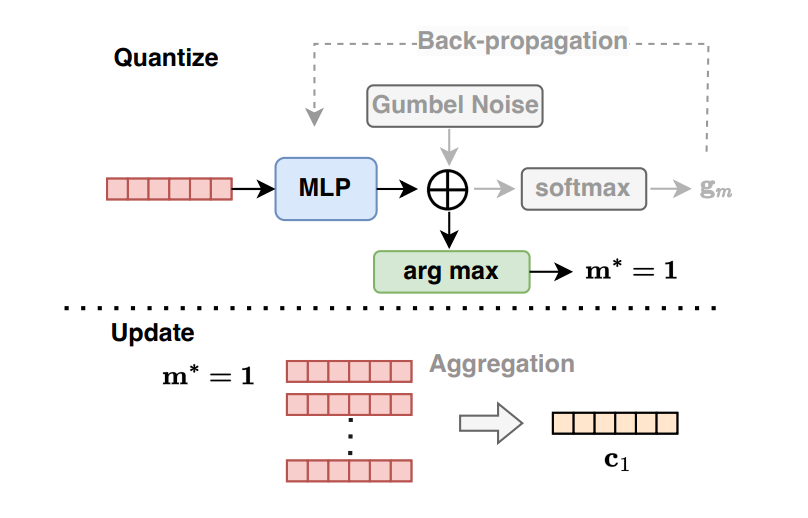
Another technique proposed in this work is to add one additional contrastive loss in the original reconstruction loss so that we could enforce the diffusion process to be less bias to popular items in the data and yield more personalized interests for each user.
The original paper contains lots of mathematic, which might be a little bit intimidate to read if you are not familiar with the original stable diffusion work. I would recommend this blog to learn the basics.
Diffusion Model for Interest Refinement in Multi-Interest Recommendation
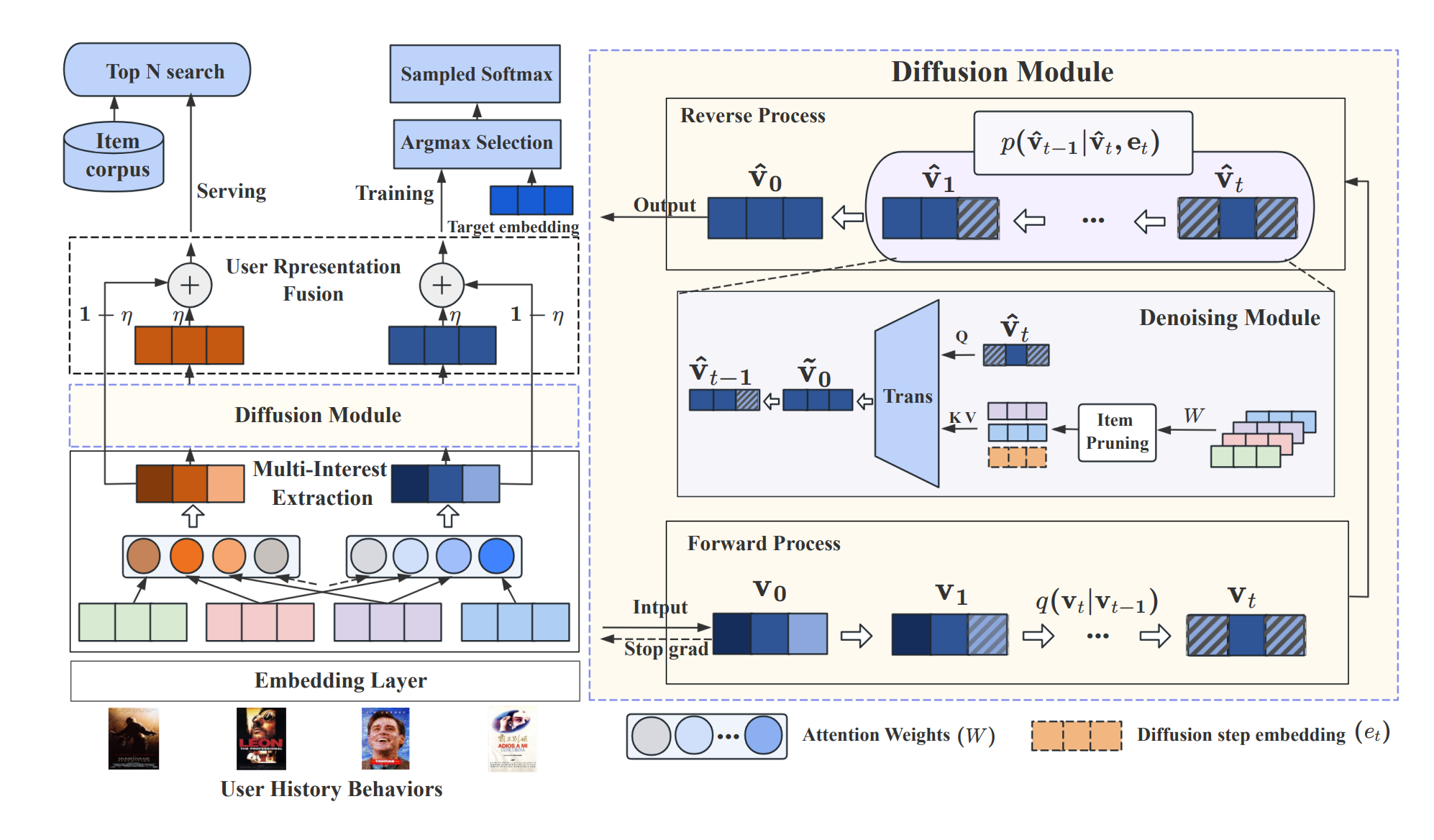
This work is from Xiaohongshu, which is a famous Chinese company similar to Pinterest. In this work, the diffusion process to improve the multi-interest embeddings extracted from user sequence, which is called Diffusion Multi-Interest Model, to make each individual interest embedding is more clear and contains less noise polluted from users’ multi-interest convoluted interest.
The work starts with apply self-attention on the user history sequence $H \in R^{T \times d}$ by using learnable parameters to compute the attention scores $A \in R^{K \times T} $ as
\[A = softmax(W_2 tanh(W_1H^T))\]where $K$ stands for the number of interests. Then the interest vector could be obtained as $V = AH$. Once interest vector is obtained, the next step is to leverage the diffusion step to denoise it. The logic here is a little bit complicated and has lots of mathematics, but the overall flow could be described as follow:
- For a given item, find the interest vector that is most close to it (out of total of $K$) as $v_0$
- Compute $v_t$ based on $v_0$ and sampled step $t$, this is the forward step
- Reconstruct $\hat{v_0}$ via the denoising module. This module uses the cross-attention with the original user history sequence embedding and an item-pruning strategy
- The reconstructed $\hat{v_0}$ and the original interest vector is combined together as the final user representation
- This final user representation is used for loss computation against the item during training, or used as query vector during inference
I still have some questions regarding how a transformer architecture is used in the reverse process. I will share more details later once I found more resources.
Multi Modal
NoteLLM-2: Multimodal Large Representation Models for Recommendation
For multi-modal scenarios, such as the post in Xiaohongshu platform which contains both image and text, a traditional approach to model the information from the post is to have encoder to encode the image and text data separately and then use mechanism such as cross attention or weighted fusion to learn. However, this might not be the best option due to the isolation of encoding process and sometimes the vision information might not learnt well in the post hidden state.
This paper from Xiaohongshu proposed a new prompt based approach to better learn the vision information and established a new type of multi-modal large language model. First, a special format of prompt is used, which is as follow
Note content: {'image': <IMG>}, Compress this note into one word: "<IMG_EMB>".
Note content: {'title': t_i, 'topic': tp_i, 'content': ct_i}, Compress this note into one word:
where the <IMG> token is a special token, which is going to be replaced with the output of a vision encoder after the tokenization step, and <IMG_EMB> is another special token, which is used to extracted the LLM processed vision embeddings. The embedding of the last token of the prompt is also extracted which is used at the note multi-modal embedding. This step lets LLM leverage its internal knowledge to aggregate the vision and text information. Secondly, to make sure the vision information is preserved, a late fusion approach is adopted to combine the original vision embedding and LLM processed vision embedding, where a gate mechanism is used to fuse them in a learnt way. Finally, contrastive learning is used on both the fused vision embedding and note multi-modal embedding to learn from the data.
The model is deployed offline to process the embedding for the new posts published and store the embeddings into an embedding table. This embedding table is used to extract embedding queries based on user history sequence as well as for building ANN index.

LLM Embedding & ID Embedding
Full-Stack Optimized Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
One novel idea in this paper is how they combined the LLM embedding and id embedding from traditional recsys model:
- Train a traditional recsys model to learn the collaborative signal from the dataset and get the id embedding, for item $i$ we have $c_i$
- Use LLM to encode the text associated with the item into LLM embedding, which is $E_i = [v_1, v_2, v_3, \dots, v_L]$
- Train a projector (e.g. MLP) to project the id embedding into LLM embedding space and append it to the last via soft-prompt $\hat{E_i} = [v_1, v_2, v_3, \dots, v_L, MLP(c_i)]$, the soft-prompt here is just use a special token in the prompt and replace it with the id embedding
In this approach, we could merge the collaborative signal and the semantic signal together and let’s LLM to learn from the augmented input.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
In this paper from Tecent, the researchers proposed a new way to find positive samples for contrastive learning, especially for the case of recommendation system scenarios where data sparsity is common.
Traditionally, clustering approach is used for cross-sequence CL and masking is used for intra-sequence CL. However, both methods would be affected by the data sparsity issue. In this paper, semantic embedding obtained from LLM plays a critical role to ensemble positive samples, which depends on the natural text information and is not affected by the sparsity issue.
The idea is relative straight forward. First, user’s sequence is hard prompted into text and then use merchant LLM to summarize; the summarized text is feed into LLM and convert to a semantic embedding. Then the similar users could be identified via this semantic embedding and for each user, we could generate a candidate set. However, this set is generated purely via the semantic information and the actual collaborative signal is missing. Thus additional processing is required so that we could weight each candidate in the set correctly based on the training data we have. The author used a simple attention mechanism and softmax to compute the weight. And the final user positive sample embedding is represented as
\[h_{u}^{+} = \sum_{u^\prime \in N_{u}} p_{u, u^\prime}h_{u^\prime}\]Similar approach is used on item side as well, but the positive samples are directly sampled from the candidate set instead of using a learnable approach to merge them together.
Bridging Textual-Collaborative Gap through Semantic Codes for Sequential Recommendation
This paper from Renmin University proposed a new approach to fuse the text embedding and id embedding, to achieve a better trade off between the semantic information and collaborative information. In this method, the semantic code, which is generated via product quantization or residual quantization is used to merge with the text embedding:
- For each item, convert each attribute’s raw text into text embedding via certain encoder model, $Z^t = [z_1^t, z_2^t, \dots, z_m^t]$
- Based on the attribution embedding, use PQ/RQ to quantize and obtain the semantic embedding $Z^c = [z_1^c, z_2^c, \dots, z_n^c]$
- For semantic embedding, first apply multi-head attention, and then use attribution embedding as KV to perform cross-attention, which eventually generate $H \in R^{n \times d}$, use a pooling module to convert the hidden state into a single embedding vector, also combine the pooling of semantic embedding to enforce the learning of collaborative signal in those embeddings
I think this is the most interesting part: for the semantic coding part, similar item would be enforced to share similar codex and thus the collaborative signal would be shared among these items, achieving shareability; the self-attention and cross-attention provide a more sufficient compute capability for model to learn across different attribute of the item and enforcing the model to learn semantic embedding well instead of solely relay on text embeddings.
For the learning part, the work adopted idea from masked language model, that some semantic code and item in the sequence would be masked and ask the model learn to reconstruct.
Distillation
External Large Foundation Model: How to Efficiently Serve Trillions of Parameters for Online Ads Recommendation
Distillation is a technique used to transfer knowledge from large model into smaller model to achieve a trade off between accuracy and efficiency. For example, in LLM area it is a hot topic to transfer the knowledge in lager language model into smaller language model which is targeted to run on device. In short, the model with larger capacity could learn and memory more patterns from the data which model with small capacity is hard to learn well; thus the output from the larger model (which we also usually called teacher model) could be used as a type of soft label which is easier for the smaller model (which we also called student model) to learn.
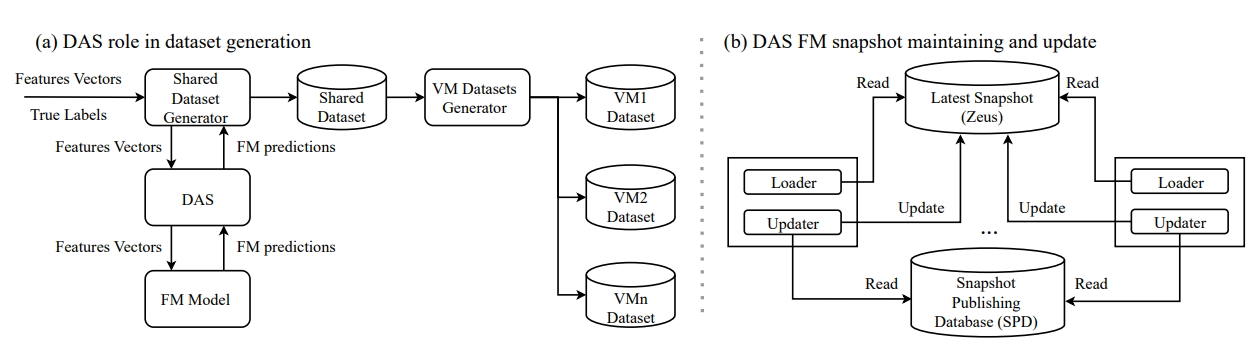
In recommendation system, there is also such trend. This paper from Meta pushed this direction to the extreme: they trained a foundation model (FM) billions of parameters, compute intensive architectures and 15x ~ 100x volume of training data and covers all verticals/domains compared to the vertical model (VM) that is serving online. In the paper, they shared the system architecture of their online distillation system, which is called Data Augmentation Service (DAS):
- The training data is generated in streaming approach, which is for online training
- Once the streaming training data is generated, one additional model inference call is sent to offline FM inference to obtain the soft label; once label is get, it is joined with the streaming data again as teacher supervision (my guess here is that they are reusing the same online joining framework)
- The data is stored in shared dataset, which could be filtered by VM based on their traffic/sector
- To make sure the FM could obtain the latest production traffic, it needs to be regular refreshed with the shared dataset; new snapshot would be published regularly and DAS is responsible for identifying and loading the latest snapshot for offline inference
Recsys Modeling
LLM-Alignment Live-Streaming Recommendation
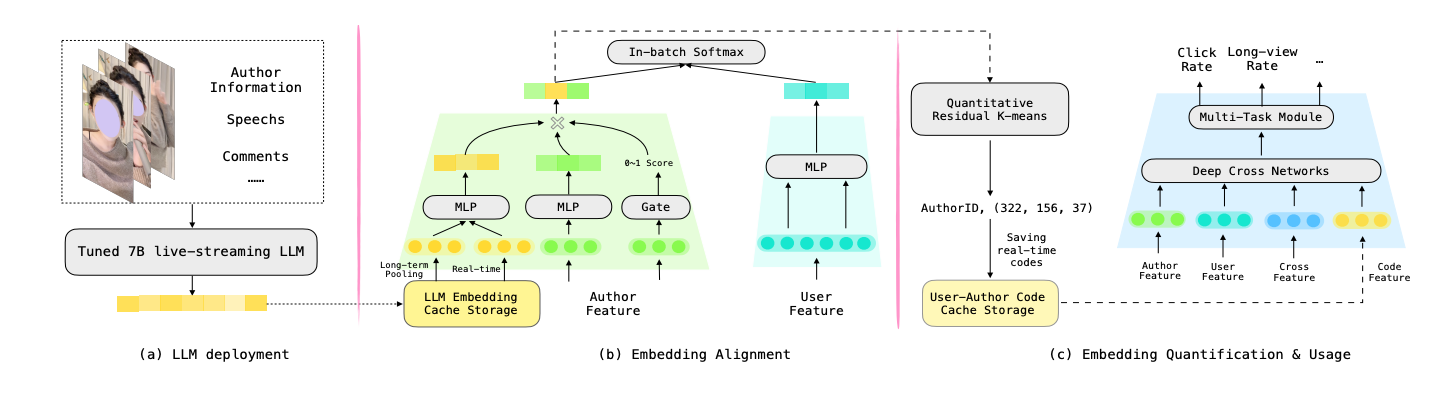
This paper from Kuaishou introduces some challenges in live streaming recommendation, which is some problem that I haven’t encountered. For example, the live streaming is realtime, which means that pre-generating embeddings is not an option and the embeddings has to be generated on the fly when it is alive; also audience might join live at different timestamp and see different screens of the live, which makes it harder to modeling users’ behavior. The author introduced some technique they have been successfully deployed online, which worth to learn about, especially if you are also working in live recommendation:
- A 7B VLM model is used to generate embedding for live streaming every 30s; the 7B model is fine tuned use the data that is annotated by a powerful 100B in offline
- A gating mechanism (similar to the NoteLLM-2 in the above section) is used to fuse the semantic embedding generated from VLM and the author id embedding (for collaborative signal)
- To make the online serving efficient, the fused embedding is further quantized and only the codex id to save the online serving storage. The codebook here is generated via a hierarchy K-means approach where a group of author embedding is first clustered into 512 categories, and then the residual part is clustered into 256 categories, and so on. A total of 3 layers of codebook is used. The codex id is used as feature into the deep cross network, which is also used for attention computation.
I’m pretty enjoy reading this paper as there not much fancy and complex mathematic involved. Everything is relative straight forward to explain and understand. Highly recommend for a read (and I will also try these tricks in my side project ![]() )
)
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.