Recsys 2025 Paper Summary
In this post, I would like to summary the paper from Recsys 2025 and share some of my learnings. We would cover several topics such as sequence modeling, cross domain learning as well as LLM integration with recommendation system. Here is a full list of papers in this post:
- Beyond Immediate Click: Engagement-Aware and MoE-Enhanced Transformers for Sequential Movie Recommendation
- LEAF: Lightweight, Efficient, Adaptive and Flexible Embedding for Large-Scale Recommendation Models
- You Say Search, I Say Recs: A Scalable Agentic Approach to Query Understanding and Exploratory Search at Spotify
- Lasso: Large Language Model-based User Simulator for Cross-Domain Recommendation
- Streaming Trends: A Low-Latency Platform for Dynamic Video Grouping and Trending Corpora Building
- Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
- Kamae: Bridging Spark and Keras for Seamless ML Preprocessing
- Generalized User Representations for Large-Scale Recommendations and Downstream Tasks
- User Long-Term Multi-Interest Retrieval Model for Recommendation
- Balancing Fine-tuning and RAG: A Hybrid Strategy for Dynamic LLM Recommendation Updates
- Closing the Online-Offline Gap: A Scalable Framework for Composed Model Evaluation
- Zero-shot Cross-domain Knowledge Distillation: A Case study on YouTube Music
- Exploring Scaling Laws of CTR Model for Online Performance Improvement
- GenSAR: Unifying Balanced Search and Recommendation with Generative Retrieval
- PinFM: Foundation Model for User Activity Sequences at a Billion-scale Visual Discovery Platform
Sequence Modeling
PinFM: Foundation Model for User Activity Sequences at a Billion-scale Visual Discovery Platform
One paper from Pinterest introducing their foundation model work. Different from the pervious TransAct series on user sequence modeling, in this work, they also adopted next token prediction as the training objective.
- The input sequence construction is similar to TransAct, including timestamp, action, surface and item id. These sparse feature is converted to dense embeddings and then sum together. They also applied one MLP to transform these inputs before feeding into the transformer blocks.
- The training objective is primarily next token prediction:
- To mitigate the large vocab size, they adopted InfoNCE loss
- The loss is computed when there is a future positively engaged item
- Adopt multi token prediction to look all positive actions over a future time window
- The foundation model is integrated as a preprocessor for the downstream model.
- In this work, they also verified that unidirectional attention is better than bidirectional attention, which callback to pervious Xiaohongshu’s finding.
- One serving optimization is to leverage KV cache to precompute the context part, which is essentially the user’s past history; and then the cached context is retrieved and broadcast to each candidate for cross attention. They mentioned that they implemented some high performance kernel on this using Triton.
- To deal with the super large embedding tables, they adopted TorchRec. During training, the embedding lookup table is distributed to multiple GPU; and during serving, the embedding is compressed via quantization to fit into a disaggregated CPU (similar to parameter server architecture)
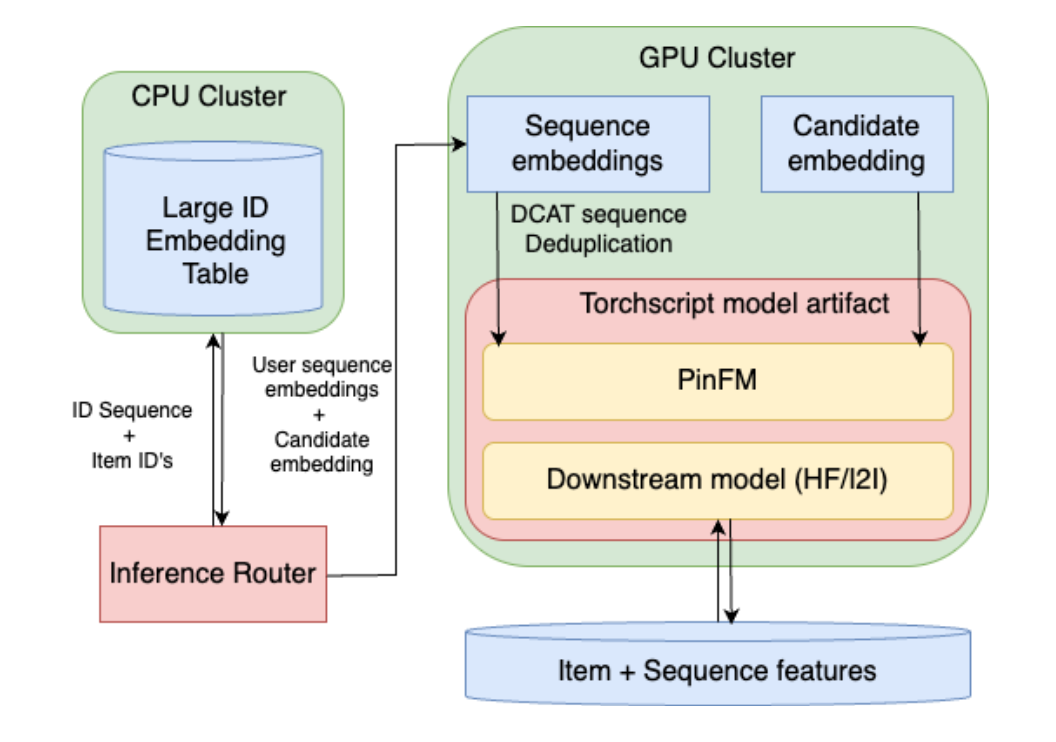
In my opinion, this paper is the best paper among all papers I have read from Recsys 25. This paper provides lots of details regarding the infrastructure work how the model is trained and served, which would be a great source of reference.
User Long-Term Multi-Interest Retrieval Model for Recommendation
Due to the volume of candidate in the retrieval stage, it is usually relative challenging to add to much complex interactions into the retrieval model, such as transformer block & user long sequence data. This work from Taobao proposed a solution to integrate user long term sequence into retrieval by exploring structured information, which is similar to Meta’s Hierarchial Structured Neural Network.
- User sequence data is split into multiple subsequence based on the item category information.
- The training objective is changed to predict the click probability within each interest cluster instead of over the entire candidate pool. The positive sample strictly matches the category of the corresponding subsequence, and the negative sample are randomly draw from teh same category subspace.
- The short term sequence is processed via self-attention module. Besides, the short term sequence is also pooled together as query and perform cross attention with each interest cluster. During training, only one subsequence is activated while during inference multiple subsequences are activated.
- During serving, user’s long & short term sequence is used as input to generate two distributions over the interest clusters. Then the top k category is selected, the item embedding form these categories are pooled together and used as query for ANN.

Exploring Scaling Laws of CTR Model for Online Performance Improvement
This work from Meituan proposed a new building block called unified attention block for sequence modeling, which unifies the attention computation between sequential (e.g. item id) and non-sequential (e.g. user profile) features. Similar to Wukong’s work, they stack multiple UAB for scaling and demonstrate great online and offline result. They also open sourced their code.
The design of the UAB includes two key components
- Item sequence cross attention with sequential and non-sequential features. Once features are converted to dense vectors. The sequence feature first do self-attention and get the hidden state (note that candidate is append as the last item in the sequence). Then, this self-attention state is used as query, and non-sequential feature’s dense embeddings are used and key and value. And a cross attention hidden state is computed.
- Alignment through gating strategy. The cross attention hidden state is pooled over the sequence dimension and then use different up/down project to covert to gating weights. These weights are then product with the self-attention and cross-attention state and fuse them together as final attention state.
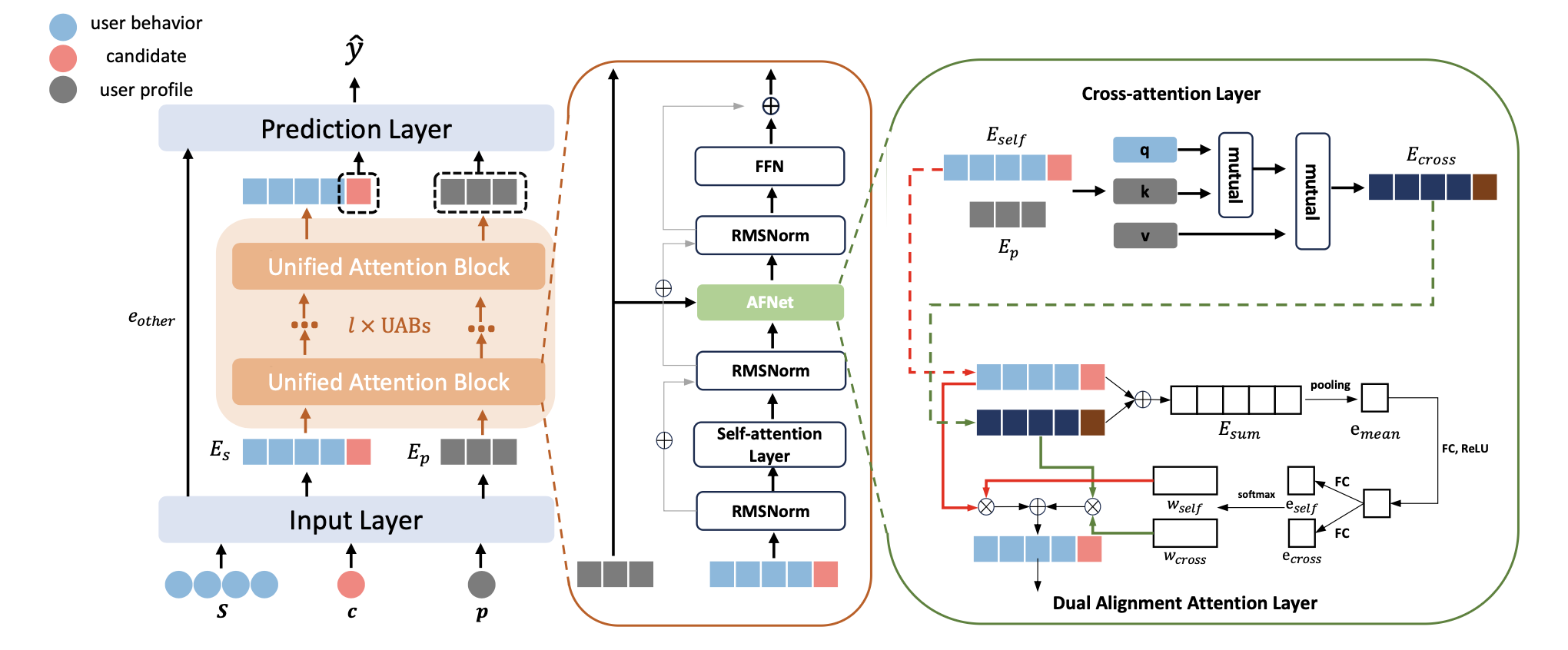
During the inference, sparse attention is adopted as one optimization (sliding widow and dilated self attention). The candidate inference also used a special masking to inference in parallel for multiple items.
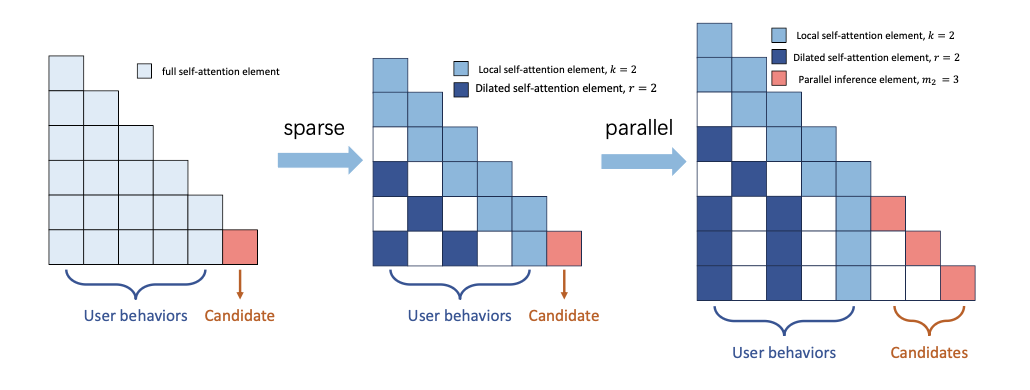
Beyond Immediate Click: Engagement-Aware and MoE-Enhanced Transformers for Sequential Movie Recommendation
One work from Amazon Prime regarding stream recommendation. Some high level points worth to try out
- Based on user’s completion rate to do personalized hard negative sampling (engagement aware).
- Adopted MOE architecture. Each MOE handles one type of user sequence, which is categorized based on recency of the behaviors (a.k.a short/mid/long term). With each MOE, use the transformer encoder to process the sequence. Finally one attention pooling is used to compress the hidden state on the sequence dimension (a.k.a learnable project + softmax to compute attention scores).
- Adopted a gating mechanism to merge different MOE’s output. The gating weight is computed based on user features and use softmax to compute the weight.
- Use multi-task learning as the final loss. The completion rate is also introduced as a weight.
Classical Recommendation Tasks
Multi-Granularity Distribution Modeling for Video Watch Time Prediction via Exponential-Gaussian Mixture Network
This work from Xiaohongshu proposed a new solution to model the watch time prediction problem.
- Based on the result from data analysis, they model the watch time as a Exponential Gaussian Mixture distribution. The exponential part is used to model the quick-skip behavior and the gaussian mixture part is used to model user’s multiple interest.
- To estimate the parameters of EGM, they proposed a Exponential Gaussian Mixture Network to learn from training data. The structure of the model is relative straight forward. A backbone model (e.g. DIN, DCNv2) is used to convert input features into a hidden representation. And then the hidden representation is used to generate the parameters for each distribution, as well as generating the gating wights for gaussian mixture.
- The loss function is composed by three parts. The first part is maximum likelihood estimation to fit on the training data; the second part is an entropy maximization to make sure all distribution could be used instead of collapsing; the third part is a regression loss to minimize the actual watch time and the expectation of the estimated EGM parameters.
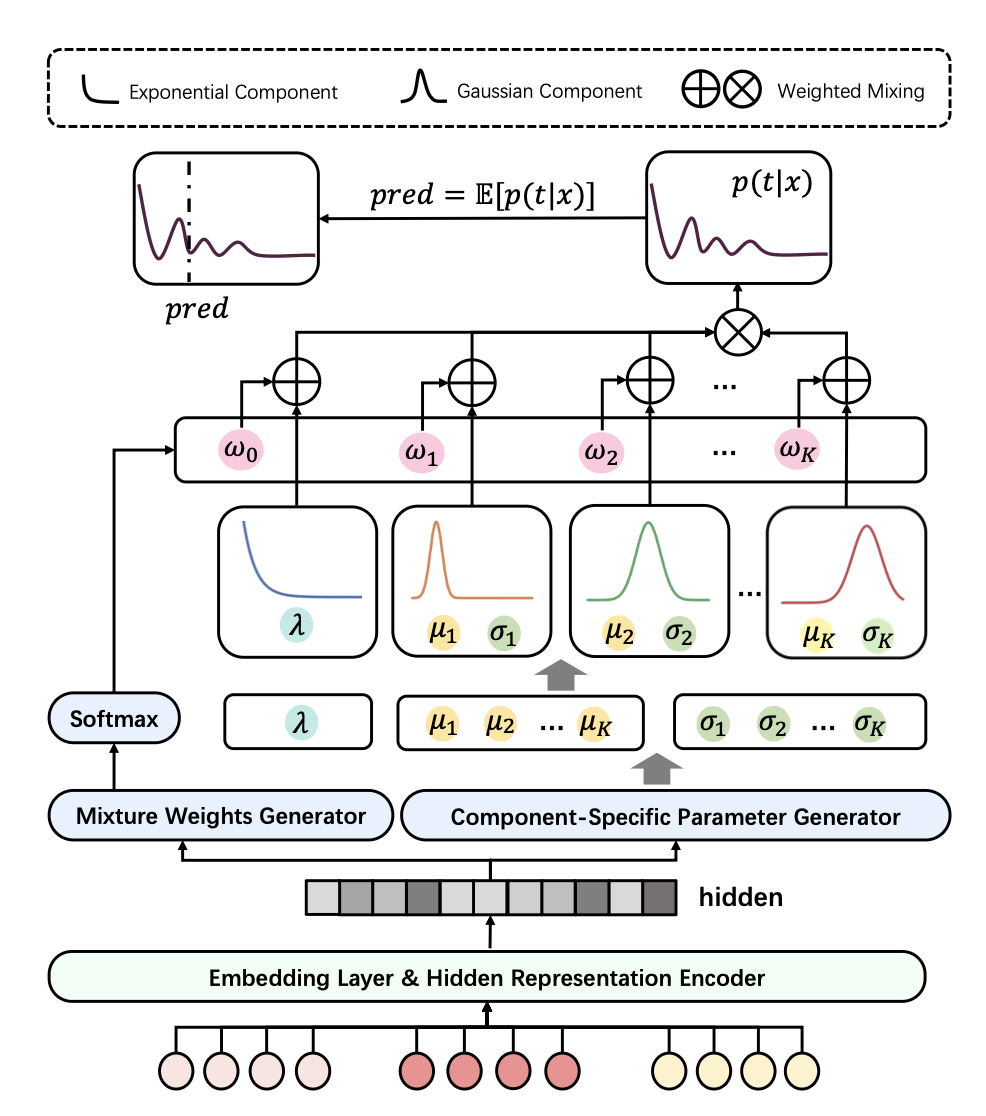
My learnings from this work is that:
- Know your data, understand your data
- Bake the right assumption into your model, that will help it learns better on your data
- How to estimate distribution using neural network
Cross Domain
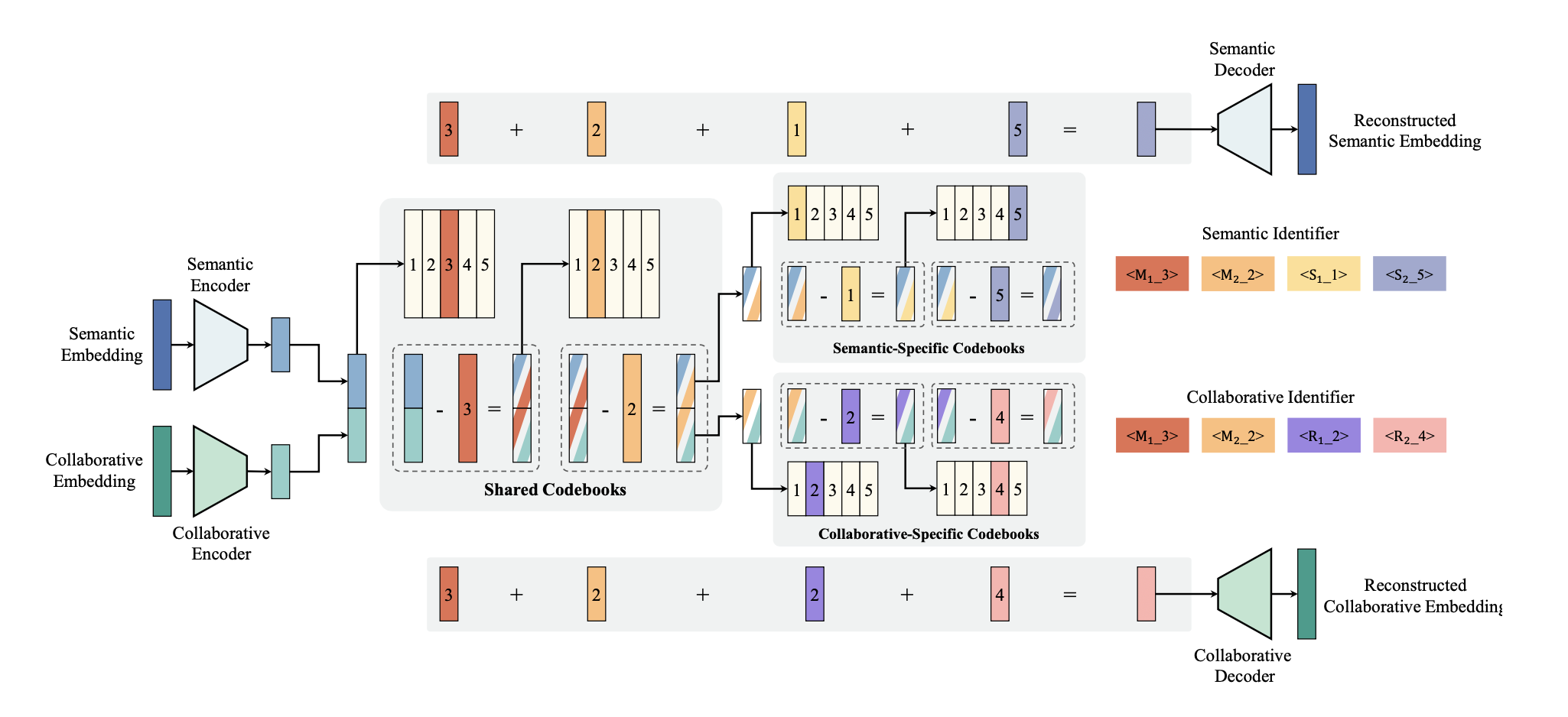
GenSAR: Unifying Balanced Search and Recommendation with Generative Retrieval
One work from Kuaishou on unifying the search and recommendation and co-train these two domains together. In this approach, we could learn some signal that perviously is not accessible. For example, during the recommendation, maybe we could leverage user’s recent search history to recommend some related items; during search, maybe we could leverage the rich preference signal in recommendation domain to provide better personalized ranking for user.
One interesting idea is how the semantic ids are trained in this work
- The semantic embeddings from search and collaborative embeddings from recommendation are trained and quantized together.
- The semantic id algorithm adopted is RQ-VAE and a hybrid codebook strategy is used. The semantic embedding and collaborative embedding is first concatenated together, and go through the quantization process via shared codebooks; and then the residual is split and goes through the individual codebooks.
The remaining part of the work is similar to OneSearch/OneRec (which I plan to have a separate blog for more detailed discussion). User’s behavior is tokenized using the semantic id, and a special token is prepend to instruct the LLM if the task is a next recommendation item, or next search item generation (which is similar to PinRec’s controllable item generation).
Zero-shot Cross-domain Knowledge Distillation: A Case study on YouTube Music
One work from Youtube Music regarding cross domain distillation: how they leverage Youtube ranking model to distill and improve YouTube Music ranking model.
- They use the Youtube Ranking model as the teacher model and tries to improve the HomePage ranking and Radio ranking task in Youtube Music domain
- Since Youtube Ranking model has similar task as the HomePage ranking in Youtube Music, they adopted a data augmentation approach that given teacher model’s logits to predict teacher label
- There is no similar task to Radio ranking in teacher model, and thus they added a non-serving task to predict Youtube’s watch next soft label
The learnings here is some guidance regarding the setup of knowledge distillation based on the property of the tasks.
Infra
LEAF: Lightweight, Efficient, Adaptive and Flexible Embedding for Large-Scale Recommendation Models
Embedding is a common component in recommendation models. It plays a critical role on “memorization” (please refer to wide & deep series of papers). However, in industry scenarios, we usually need to apply hash trick to fit entity ids with extreme cardinality. And hashing collision is unavoidable and could cause some issue on representation learnings.
In this paper, the authors proposed a new way of hashing these ids:
- Separation of frequent & infrequent features: this is done via an online sketch counting algorithm that process on streamed batch of data. This create the first level of hierarchy and we could use more resources (e.g. embedding tables) to model the frequent features.
- Multi hash functions: multiple hashing functions (in the format of $(a \times x + b) mod c$) are applied and compute multiple embedding indices for the feature. Then the embeddings are pooled together as the final result. Via multiple hashing functions, we are virtually creating a much larger space beyond the cardinality of the original embedding table.
The idea in this paper is relative simple and I plan to try this out in my project as well.
Streaming Trends: A Low-Latency Platform for Dynamic Video Grouping and Trending Corpora Building
One work from Google discussion about the overall infrastructure design to detect trending videos. I feel this actually could be a pretty good system design problem ![]()
The core part of the system is an online clustering component. Once a video is uploaded, certain feature is extracted from the video and sent to a online graph service. The service would leverage locality sensitive feature hashes to identify potential neighbors, and these neighbors would be passed to model inference service to compute the exact similarity. Based on the computed similarity, the new videos would be merged into existing clusters or create a new clusters. And these information would be leveraged by the trends API to identify trending contents.
Kamae: Bridging Spark and Keras for Seamless ML Preprocessing
In machine learning, people are usually exciting about different model architecture and feels that is the most cool thing. However, there are also many dirty work which is critical for the performance of the model, and feature preprocessing is one of these dirty works.
Feature preprocessing is certain feature transformations on training data before they are feed into model. And how to make sure the feature processing is consistent across different stage of your ML development cycle (e.g. training, serving, offline backfill, etc) is challenging due to the heterogenous design and infrastructure.
In this work from Expedia, they shared an open source project Kamae, which is a framework that unify the feature preprocessing in spark and tensorflow. Their high level design is to implement all the preprocessing logic within Keras using Pyspark. User would use these pre-built component to author feature transformation pipeline, and then export the pipeline as Keras model bundle.
I have worked on a project the is similar to Kamae and evaluated their direction before. However, we didn’t move along this path due to the concerns on the flexibility and maintaining costs.
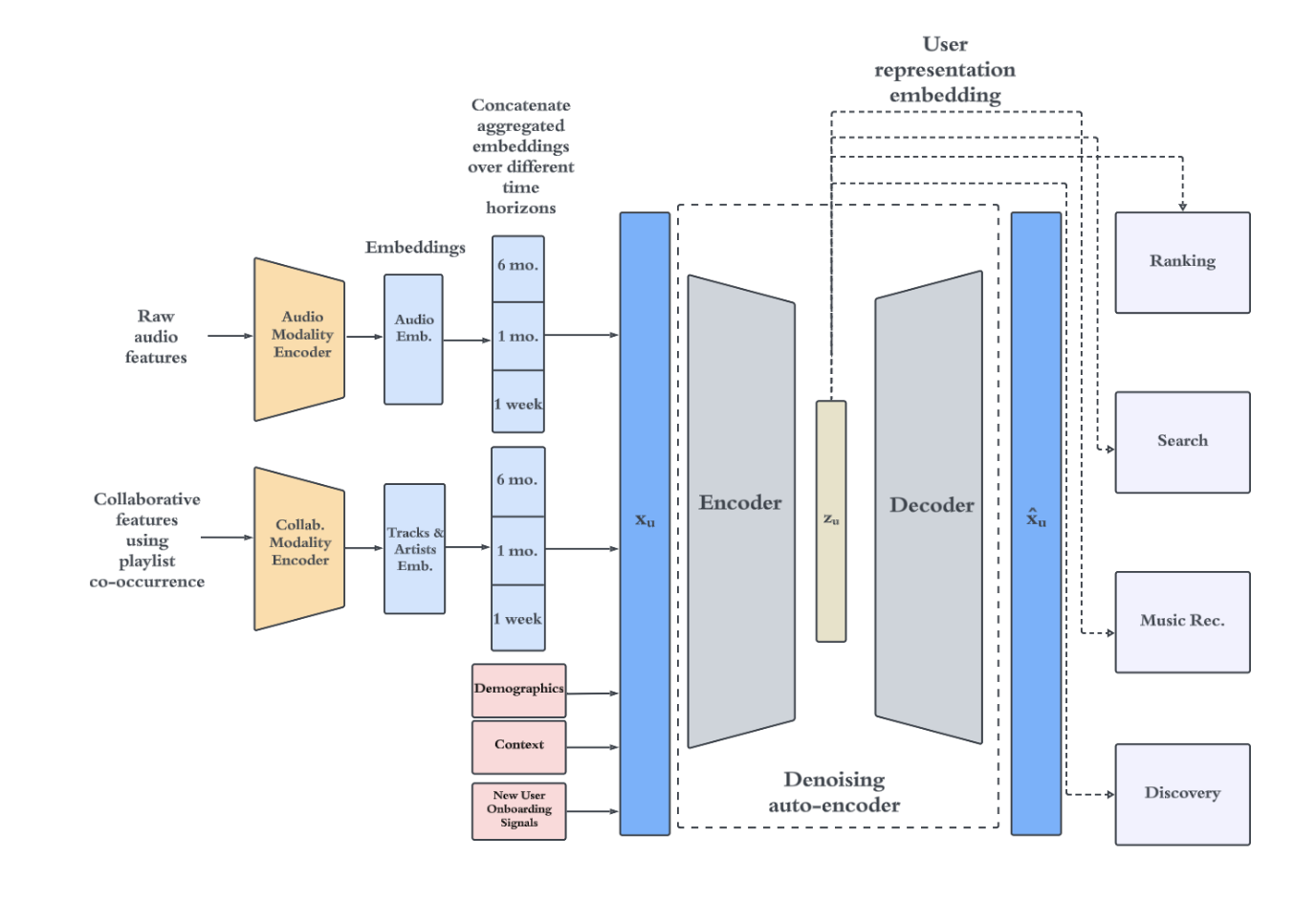
Generalized User Representations for Large-Scale Recommendations and Downstream Tasks
One paper from Spotify on user profiling embedding training. The overall solution is similar to the SUM work from Meta.
- Audio track data is encoded to dense embeddings as well as the collaborative features such as playlist co-occurrence. The paper does not provide too much details on the collaborative feature encoders, my guess is that this is just the sparse feature embeddings used in traditional recsys models.
- The embeddings are versioned on the time dimension into different granularity (1 week, 1 month, 6 months etc) and they are concatenated together. This helps improve the stability of the embeddings learnt, as well as providing richer information in longer time span.
- User features are then concatenated together with the dense embeddings. And is feed into an autoencoder for training. The hidden state generated by the encoder is used as the user profiling embeddings for downstream tasks.
- The embedding update is triggered via event and computed in nearline.
Closing the Online-Offline Gap: A Scalable Framework for Composed Model Evaluation
Online offline consistency is a headache for many machine learning engineers even there is no bugs. One reason is that during offline evaluation we usually only look at a single eval metric on a single model (e.g. NE or AUC); while in online multiple model is working together to compose the final scores.
In this paper from Meta, the author proposed to build a “simulated” online inference environment in offline so that they could replay the traffic in offline. During online inference, they log all model scores and PCT configuration; and in the offline, they reimplemented the PCT evaluation logic and recompute the scores based on newly inferred or logged model scores.
The solution sounds pretty straightforward, but there are probably lots of engineering challenging even though the short paper does not provide too much details. For example, how to make sure the online/offline implementation is exact same (even on the deployed artifacts); how to guarantee the offline execution could be effect (batch vs request), etc.
LLM
You Say Search, I Say Recs: A Scalable Agentic Approach to Query Understanding and Exploratory Search at Spotify
One work from Spotify on how to leverage LLM to better understand user query and route them to the best tools/service. Some high level points:
- Leverage caching on the common queries to scale the system
- Adopted teacher model to generate synthesized training data and combined with rejected sampling finetune to distillation knowledge into smaller model
- Leverage LLM-as-a-judge to evaluate the result
Lasso: Large Language Model-based User Simulator for Cross-Domain Recommendation
This is one very interesting work from Kuaishou, where they leverage LLM for the cross domain recommendation problem. In cross domain problem, the target domain usually suffers from data sparsity problem and thus we learn from the information rich source domain and transform the hidden knowledge that could be shared with the target domain.
In this work, LLM is used as simulated users to generate the potential interaction for the target domain
- LLM is first finetuned on the user behavior data from the overlapped user between target and source domain (LORA is adopted for this stage). The LLM is prompted to output yes or no given user’s behavior sequence in source domain and the candidate to evaluate in target domain.
- Certain strategy is used to make sure the LLM could simulate reasonable interactions in target domain. The first one is to limit the candidate to generate action: for each user, a candidate pool is generated through collaborative filtering (user similarity is computed and the top k users’ interaction candidate is pooled together). Another one is to also output the probability of the yes and no decision, which is used as a confidence score used by downstream task to filter the synthesized samples for training.
In my opinion, this is a very interesting and exciting direction. I have been thinking about if LLM simulation could be used for building RL environment for recommendation system as well. This could be a game changer for the future of how we train recommendation models.
Balancing Fine-tuning and RAG: A Hybrid Strategy for Dynamic LLM Recommendation Updates
LLM is powerful and there are lots of work has demonstrated that integrating LLM into recommendation boosts the performance. However, there are still lots of engineer challenges in real world. And how to make sure LLM could consume and adapt user’s latest behavior is one of such challenges.
In this work, researches from Google proposed one solution to trade off between the quality and infra cost to maintain LLM is refreshed and could capture user’s latest interest
- In the setup, they use LLM to predict user’s interest for next watch. Also they leveraged semantic id of the interest cluster so that they could apply generative recommendation.
- By computing the jaccord similarity based on the interest sequence from users, they find that the interest cluster is relative stable month by month. Thus they adopted monthly fine tuning on their model.
- To better leverage the dynamic information (e.g. hourly trending) on the platform, they use realtime analysis on user’s watch history, and use these as part of the RAG context in LLM prompt
Additional One Liner
- Collaborative Interest Modeling in Recommender Systems: Using transformer + routing matrix to learn multi-interest embeddings from user’s sequence data. Also leveraged neighborhood information to augment the multi-interest embeddings.
- Item-centric Exploration for Cold Start Problem: Use beta distribution to maintain a satisfaction distribution for each item and update the distribution based on the new positive and impression. For new item retrieved, filter it out from the result if model’s prediction is beyond certain confidence interval.
- Never Miss an Episode: How LLMs are Powering Serial Content Discovery on YouTube: Leverage LLM + few shot prompt to evaluate if the video within a playlist should be watched in certain orders. One interesting finding from this paper is that injecting reasoning or personality into the prompt hurts the quality of the result.
- Enhancing Sequential Recommender with Large Language Models for Joint Video and Comment Recommendation: Use comment data as augmentation to jointly train with video data. A good reference for multiple embeddings and alignments (e.g. text <-> id embedding, video caption <-> comment) are adopted during the training.
- Enhancing Online Ranking Systems via Multi-Surface Co-Training for Content Understanding: Use the pre-trained content embedding + content tower and ranking model’s feature excluding id features to train on different tasks. The content tower is exported as the embedding generation model.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.