Recsys 2024 Paper Summary
In this post, I would provide a quick summarization to some papers from Recsys 2024 which I think is pretty interesting and worth a read. The list of paper is selected based on my personal research & study interest and is highly objective. I highly encourage you to review the accepted papers as well and I’m happy to discuss if there is some great paper I missed out.
There are around 20 papers I have selected and proofread, with a mixing of long/short format paper. For short paper, there is not much details due to the limitation on the number of pages. We would just go over there high level idea and compare it against with some other papers.
Here is the list of all papers (PS: the papers are from ACM which might have limited accessibility, sorry):
- Embedding Optimization for Training Large-scale Deep Learning Recommendation Systems with EMBark
- AIE: Auction Information Enhanced Framework for CTR Prediction in Online Advertising
- EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
- CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation
- A Multi-modal Modeling Framework for Cold-start Short-video Recommendation
- Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations
- FLIP: Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
- Toward 100TB Recommendation Models with Embedding Offloading
- Short-form Video Needs Long-term Interests: An Industrial Solution for Serving Large User Sequence Models
- Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
- Scaling Law of Large Sequential Recommendation Models
- LLMs for User Interest Exploration in Large-scale Recommendation Systems
- Co-optimize Content Generation and Consumption in a Large Scale Video Recommendation System
- AI-assisted Coding with Cody: Lessons from Context Retrieval and Evaluation for Code Recommendations
- Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention
- Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
- The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
- Self-Auxiliary Distillation for Sample Efficient Learning in Google-Scale Recommenders
The paper FLIP and Better Generalization with Semantic IDs has been discussed before and thus would be skipped in this post. Please refer to my pervious post for details. I would categorized these papers based on their high level domain and group them in individual sections.
LLM
Large language model is definitely the most popular topic in recent years. In Recsys 2024, there are several papers related to how LLM could be integrated into the recommendation system.
EmbSum: Leveraging the Summarization Capabilities of Large Language Models for Content-Based Recommendations
This work comes from Meta and one novel idea is to leverage LLM to generate a summary of user interest explicitly before generating the user representation. Some key ideas in the work:
- The user history (interaction with items in the past) is chunked by session to get ride of context length limitation (besides chunking, actually perform certain compression to the original prompt probably would also work, such as how HLLM optimize to support super long user history). Each session is encoded via a T5 encoder model, and the
<SOS>token, which is the special token stands forstart of sentenceis extracted as a intermediate representation of this user session (classical approach in BERT) - Leverage commercial model to generate a summarization of user engagement (they adopted Mixtral-8x22B-Instruct, curious why not Llama 3.1). Then all encoded intermediate representation of user sessions are concatenated together and input into T5 decoder and then have the model to predict the user interest summary (in a NTP fashion)
- Then the last token from T5 encoder, a.k.a EOS, is concatenated together with the encoded session representation. They go through multiple individual attention block to learn more fine-granularity user representations (similar to multi head attention). And these final representation is going to be used for CTR prediction
- Candidate is processed similarly as user history, the only difference is how the input prompt is constructed
- The CTR prediction is computed through a inner product between the final user and item representation, together with a attention mechanism to compute wight to aggregated all matching scores
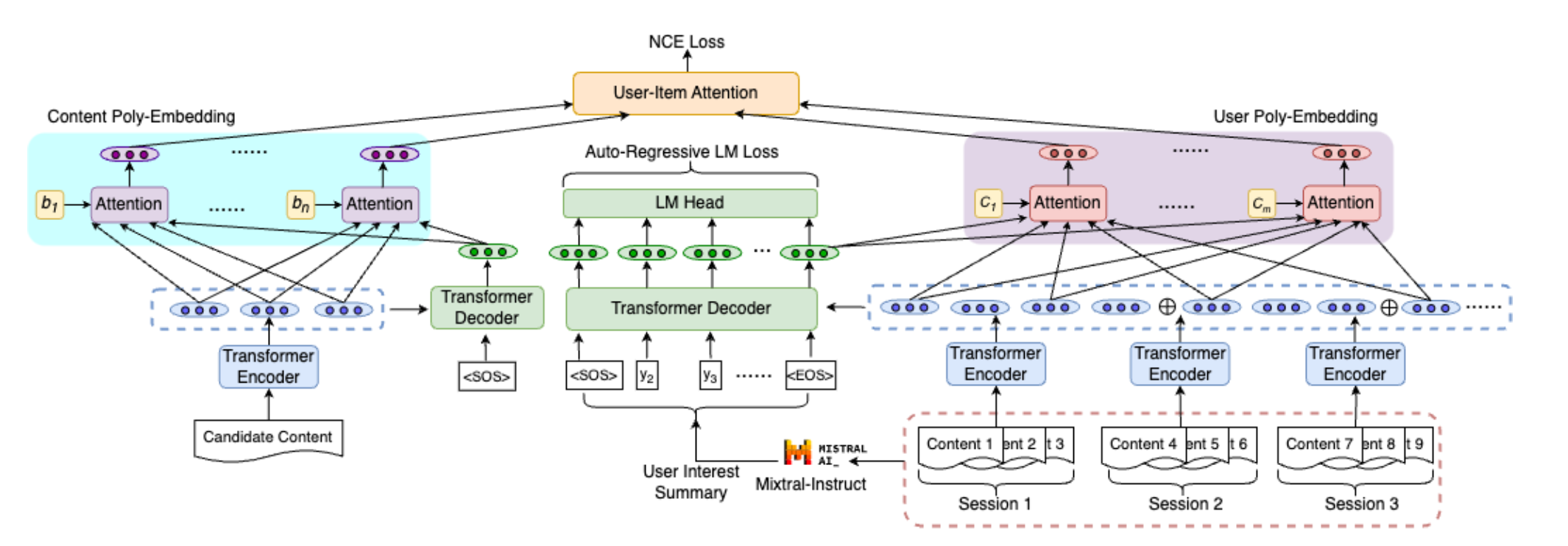
CALRec: Contrastive Alignment of Generative LLMs for Sequential Recommendation
This work from Google proposed a new framework to fine-tune LLM for sequential recommendation and they adopted a generative recommendation strategy, which means directly leverage LLM as the main model for recommendation. Some key insights of this work is:
- They defined the main task as Next Item Generation Objective, which is try to predict the next item’s text description based on the pervious item in user’s history, which is pretty similar to the NTP task
- The main task only focus on the token level information, and might miss the big picture on the user/item level. They adopted 2 contrastive learning to overcome this and forge the collaboration signal into LLM: one is to add a contrastive loss between the item embedding from LLM and user history representation from LLM exclude the item, as well as the item embedding conditioned on user history
- One more interesting part is how the model is inferred online. Since the LLM is generating text output, they adopted one additional BM25 matching to retrieve the actual item from the candidate set that is closet to the LLM output
- One finding from the work is that LLM could quickly memorize the item description it has seen during fine tuning and thus we could even the BM25 matching stage; but this would cause huge issue for item cold start
- The work does not beat one of their baseline which adopt item id + text (actually this is very common case in current recommendation system)
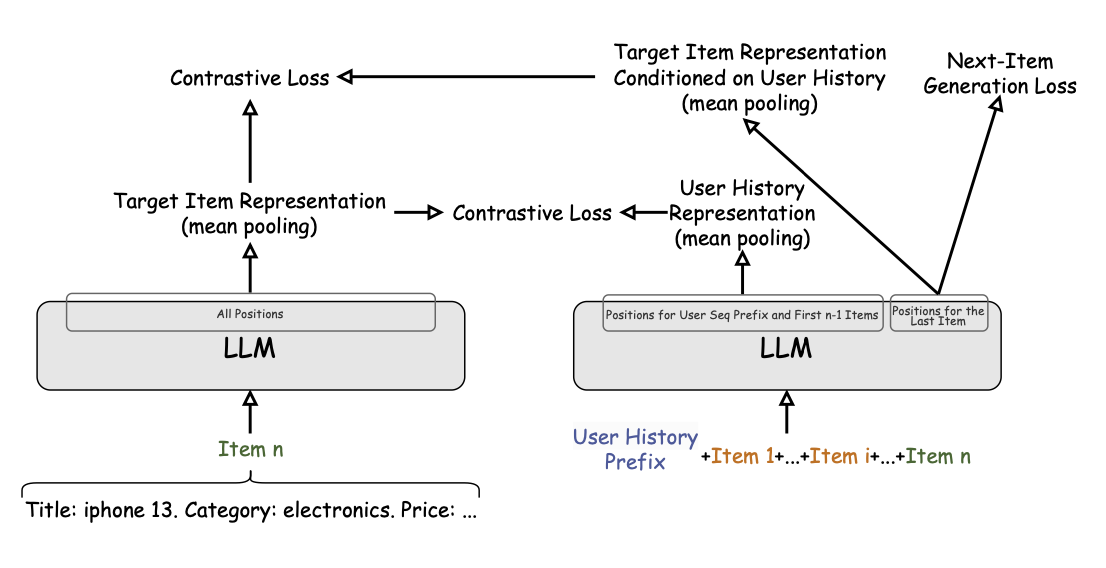
After reviewing the work, one question I have for this work is how does the model get online trained so that it could learn new item descriptions or new user/item interactions from the production traffic. In the traditional recommendation system, we could enable online training to update the embedding table continuously; while updating LLM parameters would be more challenging even with PEFT technology.
A Multi-modal Modeling Framework for Cold-start Short-video Recommendation
This work from Kuaishou is to use the multi-modal model to help resolve the item cold start problem within recommendation system. Their approach is similar to the FLARE paper we have introduced before from Google in my pervious post, which is also combine the content embedding to help boost the new short-video created. Some key differences are as follow:
- A dedicated modal encoder is designed to encode different type of input, such as text, visual and acoustic. Since the embedding is generated using pre-trained model and these embeddings are freezed, they also introduced a trainable cluster id embedding, which is obtained via K-means algorithm, to be fused with the original modal embedding
- In the user tower, user embedding interacts with the item embeddings from user behavior sequence via MHA (user embedding as Q and item embeddings as KV); besides, user embedding is also going to interact with the item’s multi-modal embedding from the model encoder, and all these output would go through a
multi-modal interest intensity learningnetwork (this is sightly different strategy how id embedding and content embedding is fused compared with FLARE) to aggregate embedding from different modal with a learnable weight (maybe some user are more text focus, while some enjoy visual more) - The item tower is similar with one unique gate component. This gate component is used to control how id embedding and multi-modal embedding is merged together. In the beginning while item is still in cold start stage, we could use more multi-modal embedding; while as the item get more exposure and the id embedding carry better collaboration signal, we could increase its effect by turning up the gate parameter
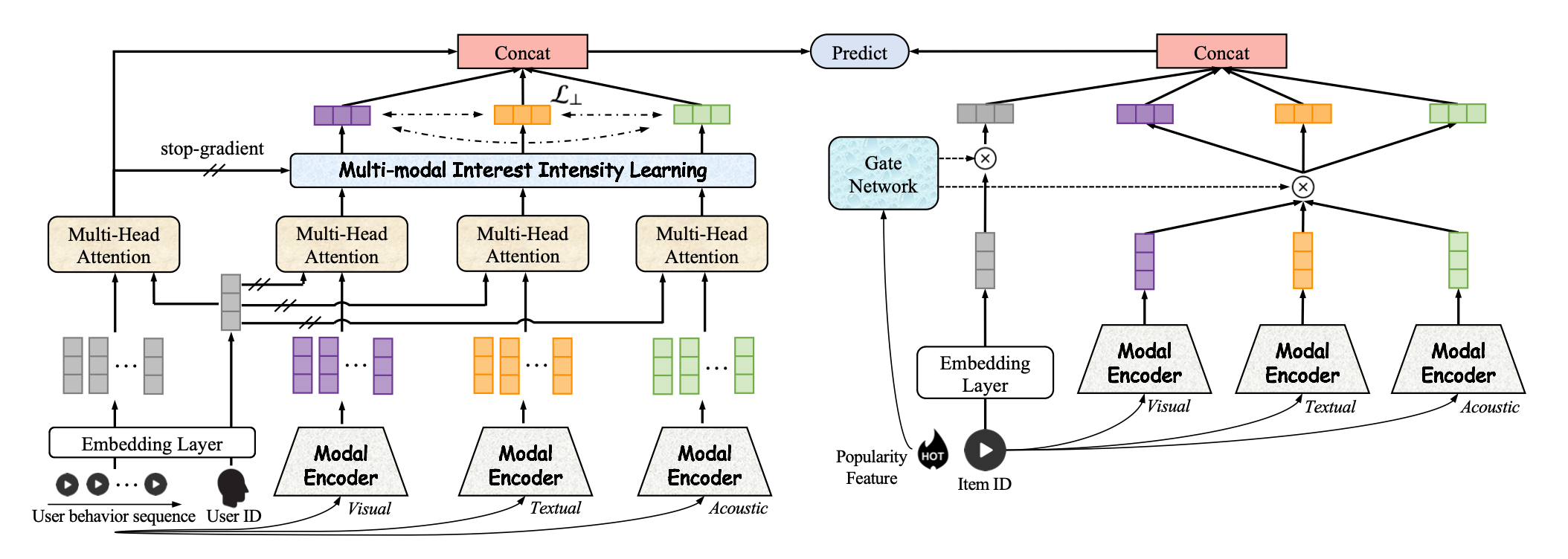
Using LLM definitely provide a good direction to resolve the item cold start problem in recommendation system, as text, image these semantic information is generic and does not require collaboration signal to learn (like we are recommending items based on some common sense from the world). However, user side cold start problem is still there, how could you get the flavor of new user as soon as possible and target them with the right item is pretty critical for their retention on your platform.
Bridging Search and Recommendation in Generative Retrieval: Does One Task Help the Other?
This is a research paper from Spotify where the researchers would like to verify the hypothesis that, under generative retrieval scenario (not traditional DL based model), would having dedicated model to train on specific task better or having a single model that trained on the joint task is better.
In this paper, they only discussed the recommendation and search task, which might due to these 2 scenarios are the most popular one on their platform. Their conclusion is that joint task is better than separated task one. And their explanation is as follow:
- The joint task would make the overall training data more smooth, which perform a type of normalization. This is relative easy to understand as usually more data points could make the overall distribution less skewed (central limit theory)
- The joint task would make the intermediate representation learned more regulated, as the representation needs to be perform well on both task, which might help avoid some local minimal
This conclusion might be case by case and need to verified via the actual data of your problem. In my pervious company, we have identified contradict scenarios that the joint trained model would lift the metrics for one task while hinge the other task.
LLMs for User Interest Exploration in Large-scale Recommendation Systems
This is a short paper from Google where they explored the potential of LLM to inference user interest. First they build a interest cluster and assign item with cluster ids. Then based on user’s past behavior, inject these cluster id as prompt and let LLM to predict what could be some novel cluster id that user would be interested in. Once get these novel interest cluster id, traditional sequential recommendation is leveraged to generate the recommendation.
In order to control the output of LLM and let it understand the term of interest cluster as while as the collaboration signal from their domain, they get some high quality data online and adopted fine tuning on the LLM to improve its quality.
Sequential Modeling
I have a personal view on the evolution of deep learning model used in recommendation system (highly subjective):
- in the ancient age, it was a three kingdom period, where collaborative filtering, GBDT and logistic regression share the world
- next comes the deep neural network, which quickly take over the leading position in recommendation realm due to its superior performance
- the following trend is the integration of sparse features into model, which dramatically increase the capacity of model
- after that, we have different types of feature interaction techniques blossom to improve the expressivity of model
If there is no advance of LLM, it would be sequential modeling’s world.
Scaling Law of Large Sequential Recommendation Models
Scaling Law has been in LLM area for a while, and there are many more different style of scaling law coming out. This paper verified that scaling law also exists in the sequential recommendation models, regarding the data volume, model capacity and training epoch.
They also verified that larger model also performs better on the downstream task. However, I have some questions regarding the conclusion here. The better performance might comes from the memorization of the model instead of generalizability.
The Elephant in the Room: Rethinking the Usage of Pre-trained Language Model in Sequential Recommendation
This is another research paper study how LLM should be adopted in sequential recommendation. Based on their study, they purposed a framework to balance the quality and cost of adopting LLM: fine tune LLM with sequential data and use the embedding output as the initialization parameters for the ID embedding in traditional DL models.
One thing they observed during their study is that, the embedding from deep layers’ head behaves similar to the ID embedding in traditional SR models. Also, they found that they could get similar evaluation result with a LLM only fine tuned a few layers using sequential data, which means there are lots of redundancy in LLM parameters.
Training & Inference
Embedding Optimization for Training Large-scale Deep Learning Recommendation Systems with EMBark
This work is from NVIDIA about how to optimize the large embedding tables within the traditional deep learning recommendation. I’m still learning this area and just share this paper here for awareness. Their work is incorporated in HugeCTR repo.
Toward 100TB Recommendation Models with Embedding Offloading
This is a short paper from Meta which introduce CPU offloading during large model training. With offloading, we could train model with large embedding tables that exceed the available GPU memory. One key optimization here is to overlap the data transfer between CPU and GPU with computation to minimize the latency impact. Thus they adopted pipelining and pre-fetching to avoid GPU waiting for data to compute. They also optimize the sharding algorithm to balance embedding offloading across all ranks (they used pin-backing algorithm to achieve this).
Short-form Video Needs Long-term Interests: An Industrial Solution for Serving Large User Sequence Models
This work from Google introduced how to integrate user sequential model into the main ranking model in a resource efficient way. The key idea is to adopt pre-computing idea: moving the user sequential model inference out of the critical path. They designed a User Behavior Service to pre-compute the embedding and export them to offline storage. During inference, this pre-computed user embedding is used. However, the user sequential model and the main model is co-trained.
Enhancing Performance and Scalability of Large-Scale Recommendation Systems with Jagged Flash Attention
A quick introduction to Jagged Tensor and Jagged Flash Attention. The work is implemented via Triton which is a very popular library for authoring CUDA kernels.
LLM Agents
I have the fortune to work on some LLM code agent as part of my project in the new company and have the chance to holistically review the work in this area. From my current experience, developing coding agent is not as simple as writing some good prompt and make a call to LLM. There are lots of things need to be considered to make the agent generate high quality result consistently.
AI-assisted Coding with Cody: Lessons from Context Retrieval and Evaluation for Code Recommendations
This is the only one paper I have found related to LLM coding agent in Recsys. The overall architecture is a RAG system. They designed a context engine to find the best context to be integrated into prompt. This context engine would retrieve from multiple sources to improve recall and then go through a ranking model to find the best candidate.
The author also introduced some high level challenge they have faced with when developing their coding agent. One is regarding the data privacy. Lots of context data only exists on users’ devices and could not be logged to server. Another one is the data sparsity regarding high quality labeled data. They have to have experienced engineering to label them manually, which is pretty inefficient (I also encountered similar situation in my project).
Recommendation System
There are still lots of study and research fall into the old school style.
AIE: Auction Information Enhanced Framework for CTR Prediction in Online Advertising
This is the first paper I have read that talks about auction bias which exists in the Ads delivery system. In Ads delivery system, the final rank usually is computed as $eCPM = pCTR * bid$, which meas that if a very low quality ads (no one like it, pCTR is low) always places a high bid (I have nothing but money), then our system would rank these ads high, leading to the system would only collect negative feedback (no one is clicking on our recommendation). This is pretty dangerous as our model need positive feedback signal to learn well. If the low quality ads slowly overwhelm the system, then it would be hard to improve our model to provide accurate pCTR estimation.
The paper mentioned 2 techniques to resolve the issue. One is to use the auction information as additional input during model training to help model debias. This is pretty similar to how we resolve the position bias. Note that since these information is only available after the model inference, they falls into the definition of privileged features (please refer to this paper for details). Another one is to introduce a auxiliary task to predict the price of the ads and compute a weight for the positive samples in the main CTR prediction task (similar to IPS).
Co-optimize Content Generation and Consumption in a Large Scale Video Recommendation System
This paper from Google discussed about the problem of how to incentive users to generate more content, which means could we recommend some videos to user that could motivate them to become a video uploader. This is one kind of down funnel problem, similar to ads click -> website conversion.
They primarily adopted the multi-task modeling framework. Some main technique used in their work is as follow:
- to overcome the sparsity of label, they adopted proxy label which is known to be highly positive correlated with content generation
- conditional loss is used to reduce the noisy, such as the logout user session
- MMoE is adopted in the main architecture of the model, where the gate is controllable; resnet is also adopted for representation learning
Bridging the Gap: Unpacking the Hidden Challenges in Knowledge Distillation for Online Ranking Systems
This is a pretty good paper to learn about the industrial practice of adopting knowledge distillation in recommendation system. The paper mainly focused on three problems:
- how to handle the distribution shift between teacher and student (the teacher might has learnt some bias during offline training, and this would also be learnt by student)
- how to efficiently manage the configuration of teacher model (MLOps)
- how to reduce the maintenance cost of KD infra (MLOps)
Regrading the first problem, they adopted a auxiliary task for knowledge distillation instead of having the student model directly trained on teacher’s label. For the second problem, they do it a hard way which is similar to a grid search to find the best configuration in one shot. For the last problem, they use a single teacher model to distill several student model, where the output from the teacher model is written into a columnar database.
Self-Auxiliary Distillation for Sample Efficient Learning in Google-Scale Recommenders
This paper introduce a new way of doing knowledge distillation, which could help avoid the mis-calibration issue caused by teacher’s soft label. The main idea is to add a auxiliary head which works as a student. The main head is used for searching to to generate teacher soft labels, and this label is considered together with the ground truth label via a label selector (e.g. curriculum learning) and then decided the label that the student head should learn.
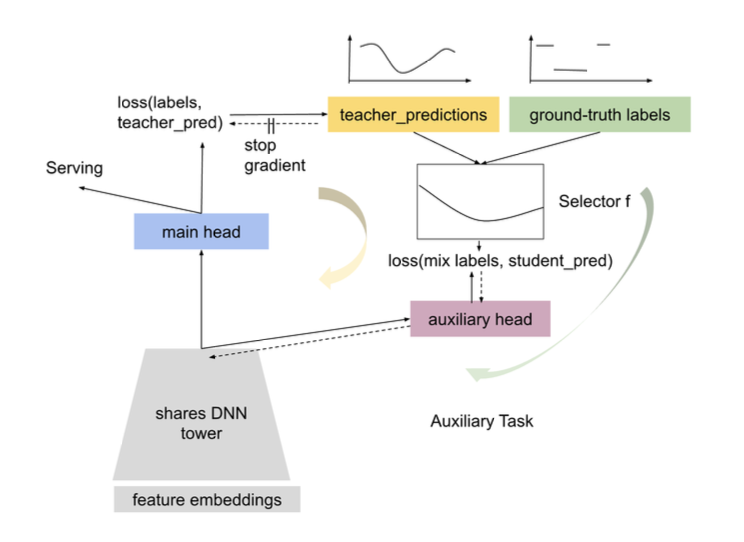
One thing that has impressed me a lot is that they used this new distillation for the signal loss scenario and achieved pretty good result.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.