Trend of Sparse Features in Recommendation System
In my pervious post, I have briefly mentioned about sparse features and how they could be used in recommendation system. In this post, let’s have a deeper look into sparse features, as well as reviewing some new ideas about how sparse features are being used in modern recommendation system, especially in the realm of LLM world.
What is sparse features
Sparse features are usually composed as some entity ids that a user has taken certain action during a period of time. For example, the facebook post ids that a user has viewed in the last 24 hours or the amazon product ids that a user has purchased in last week. These ids would be feed into model as input to generate predictions. Usually, we would go through a component called Embedding Lookup Table to convert these raw meaningless ids into some dense vectors so that they could be numerically computed with other features or layer weights. The Embedding Lookup Table would be updated along with other model parameters during training stage. A simple illustration is as follow

If you come from XGBoost world, you might be as surprised as I was when seeing how ids are being used as feature into a model. XGBoost could not directly use id as input features. To leverage these ids, we usually need to manually crafting a dense version of these ids, for example, aggregating the number of posts that the user has viewed in the last 24 hours. If we need to have some more fine granularity view, a common practice in industry is to add additional breakdowns, e.g. breakdown on the category of posts.
However, one obvious limitation to this feature engineering methodology is that it lose memorization of user interactions and lose subtle differences among entities. For example, only knowing a user has viewed 3 posts related to sports is much less predictive than knowing the user has viewed 3 posts from NBA official account; and even though the post is related to basketball, users reaction to NBA and to CBA could be pretty different. Representing entities in their raw ids, converting them to dense vectors (a.k.a embeddings) and training with the target dataset (e.g. user clicks) could help memorize user interactions and learn a better representation of these entities in the target domain.
Recently I have watched a talk given by Hyung Won Chung in MIT and one opinion from him impress me a lot regarding why GPT4 or other large language model suddenly demonstrate such powerful performance:
We should enforce less structure in learning; instead, we should leverage the more and more easily accessible computing power to learn from unstructured data
I think the adoption of sparse features in recommendation system also matches to this, where we deprecate the structure part (feature engineering) and move towards less structure (raw ids) and more computing (more capacity of the model).
Recent works on sparse features
As we have a brief review on what is sparse feature, let’s move to some recent works on sparse feature, or embedding, and see what kind of problem they are trying to resolve. I hope that this could help you borden your ideas and benefit you either for the preparation of machine learning design interview or for ML projects that you are working on.
Shareability of embeddings
Making the embeddings learnt from one domain to be reusable in another domain has been a pretty popular research topic in industry due to a practical reason: memorization of history knowledge without full retraining. For example, reuse the same sparse features’ embedding from CTR model to CVR model; or reuse the embeddings from last month’s model to new release candidate to carry-over the past knowledge. However, naively extracting the embeddings from source model and integrating them into target model does not work well. A technique called transfer learning is usually used to mitigate this type of incompatibility issue.
In this paper from Meituan (a Chinese company similar to DoorDash and has pretty strong technique in cross-domain recommendation), the author proposed a new way to transfer learning from source domain to target domain. They leveraged the idea of pre-trained model dominating LLM world and the hierarchy philosophy for information compression:
- First, a model called tiny pre-trained model (TPM) is trained. TPM is trained with simple model architecture, less number of features but large volume of data (past 6 months). Each month’s snapshot of embedding is extracted and stored separately
- Second, a model called complete pre-trained model (CPM) is trained. CPM is trained with the exact same architecture and features against the target domain model on past 1 month of source domain data. The embedding from TPM is adopted for CPM model training (bootstrapping) via an attention pooling. The training of CPM help mitigate the issue of full-qualified-name mismatch issue during model parameter initialization with the cost of flexibility
- Finally, the target domain model is trained. The model is initialized with the parameters from CPM (for both embeddings and dense parameters, batch norm layer’s is dropped due to different traffic) and then do incremental training on the past several days data on target domain
- TPM helps memorize long term history, and is refreshed monthly; CPM helps to fuse long term and short term memory, and is refreshed weekly; target domain model adapt to latest online traffic, and is refreshed daily
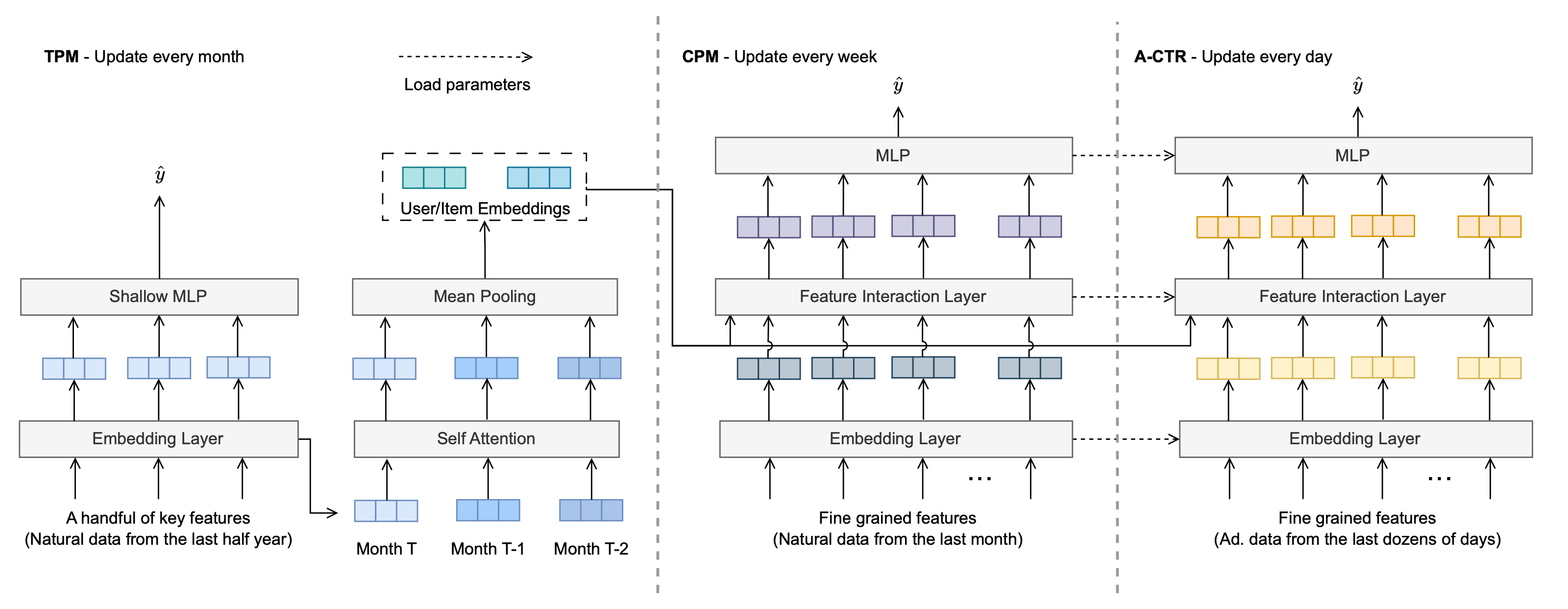
The idea of this method is not very complex. In my pervious company, we have been trying to use the embeddings from production model to bootstrap the performance of new model candidates so that it could catch up more quickly. This method requires less cost compared to knowledge distillation and data augmentation, but putting more pressure on MLOps as well as making the model development cycle much more complex.
Generalizability of embeddings
As mentioned above, embeddings in recommendation system are usually learnt from the training dataset, which is composed of user’s behavior information against the candidates. Actually, we could assume that the embedding learnt is trying to capture the collaborative signal from users’ behavior. It is similar to the non-model based approach such as Collaborative Filtering, which is also trying to compute a vector representation for each user/item for the matrix filling task. This actually puts some limitation on the generalizability of embeddings. For example, the learnt embedding of a pizza restaurant in Sunnyvale might be quite different from a pizza restaurant in Beijing because of the difference in the population or culture (which is observed via data we collected), even though their branding name includes pizza text which is an obvious information for humans to understand that these two restaurant should be the same (I was asked a similar question during my ML interview with Airbnb ![]() ). In the realm of LLM, we have more powerful tool to process such text/image information and extract their semantic information. How we could better integrate such semantic information into traditional id embeddings has been a popular topic recently.
). In the realm of LLM, we have more powerful tool to process such text/image information and extract their semantic information. How we could better integrate such semantic information into traditional id embeddings has been a popular topic recently.
In this paper LARR from Meituan (yes, besides cross-domain problem, they also have cross-scene POI problem), the author proposed one approach to align the semantic embedding generated from LLM with the collaborative id embedding learnt from recommendation system, to improve the performance under realtime scene recommendation scenario. The main idea is to first generate the semantic embedding via text constructed via heuristic rules and then leverage contrastive learning to align the embeddings:
- First, a LLM is fine-tuned with the rich textual data available from the entities, e.g. the name and description of the restaurant. During the generation of the input into LLM, different textual feature is separated with different special token to help LLM tell apart them (a pretty common practice). In their setup, the input text is the name and location of the restaurant, and they try to predict the description and menu of the restaurant. This helps LLM to learn the connection between location and associated dishes
- In the second stage, the fine-tuned LLM would be used to generate embedding for different entities and further trained via contrastive learning. The embedding of last token from the input sequence would be projected via a MLP layer, and then scored through a similarity function (e.g. cosin) with another embedding. They preformed user profile <-> user profile, POI <-> POI and user profile <-> POI contrastive learning. The final loss of this training stage is a linear combination of these 3 contrastive learning loss, which are all similar to
- In the last stage, the parameters of LLM are freezed and used to generate semantic embedding from realtime scene text features. However, these embeddings lack collaborative signal and thus require some additional processing. Due to the inference limitation, only 10 realtime scene text feature is used, each of them would be processed through LLM, and then one additional bi-directional encoder is used to aggregate these 10 embeddings, with the information summarized into a special token
<agg>. Finally a MLP is used to project the aggregation into the same dimension of collaborative id embeddings, and then one additional contrastive learning is adopted (so many CL ).
).
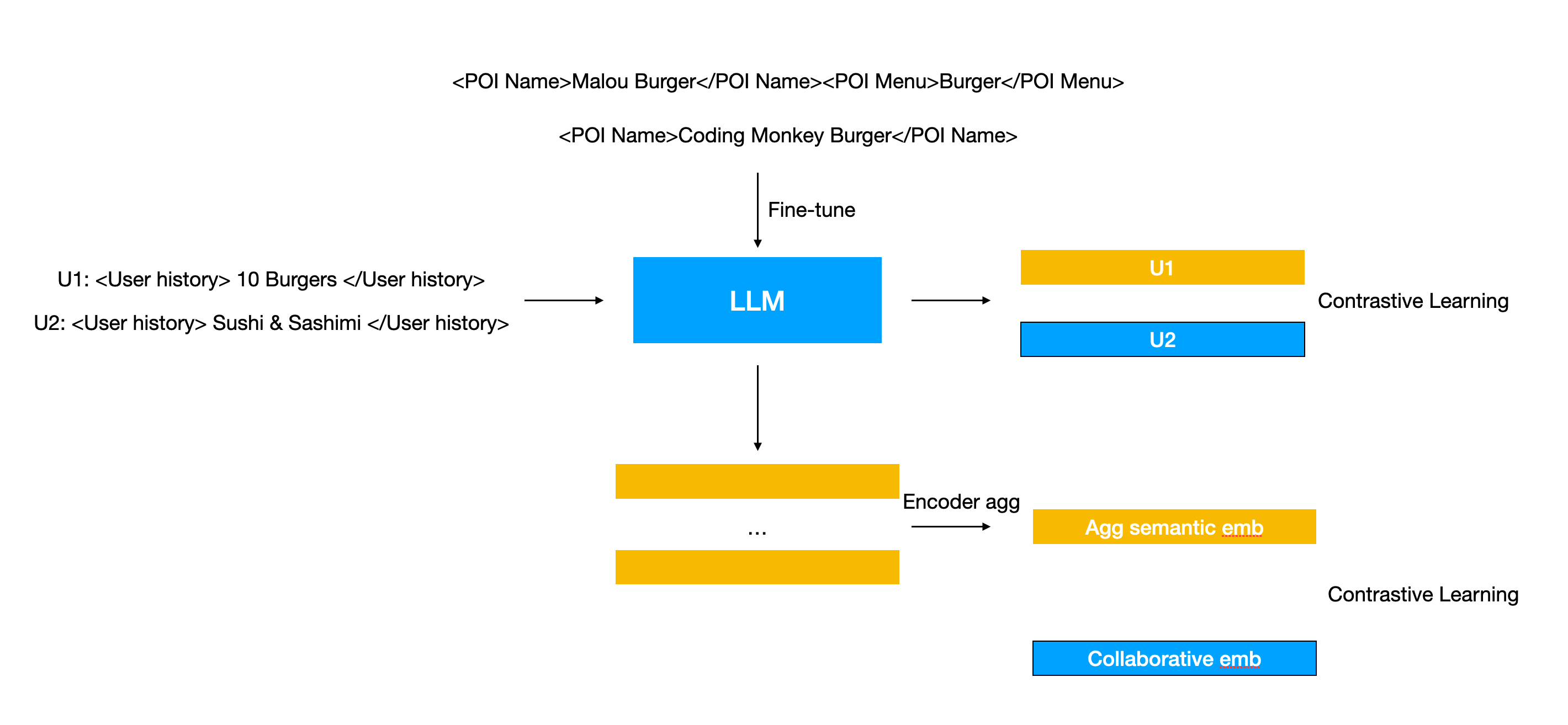
Google recently also published one paper on how to better leverage the text information of ids to boost the traditional collaborative id embeddings. In this work, they adopted masked language modeling and CLIP style contrastive learning to make the long tail ids benefit from the popular ids. For example, Pizza Hut and Coding Monkey Pizza are both pizza restaurant, but Coding Monkey Pizza would not receive much exposures (a.k.a impressions) similar to Pizza Hut, and thus we could not learn a good embedding for Coding Monkey Pizza (lack of training samples). However, leverage the text data, such as the description of the restaurant, both Pizza Hut and Coding Monkey Pizza would share similar semantic embeddings, and this would help connect them and help Coding Monkey Pizza to steal some information from Pizza Hut. There high level approach is as follow:
- One part of the training objective comes from the masked language modeling type loss. For a sequence of item ids (e.g. the product id user has purchased), some of them would be randomly masked, and then the ids would go through the embedding lookup table, and then go through the transformer to predict the masked id. The embedding is a combination of the collaborative id embedding and LLM processed text embeddings
- Another part of the training objective is the alignment between the collaborative id embedding and its corresponding semantic embedding, via contrastive learning
- One additional thing besides the
<id, text>pair is the critique string, which is also some text information, but separately encoded via LLM. This information is not masked during MLM and the reason for that is to encourage model to learn to predict target id via semantic information instead of the memorizing ids
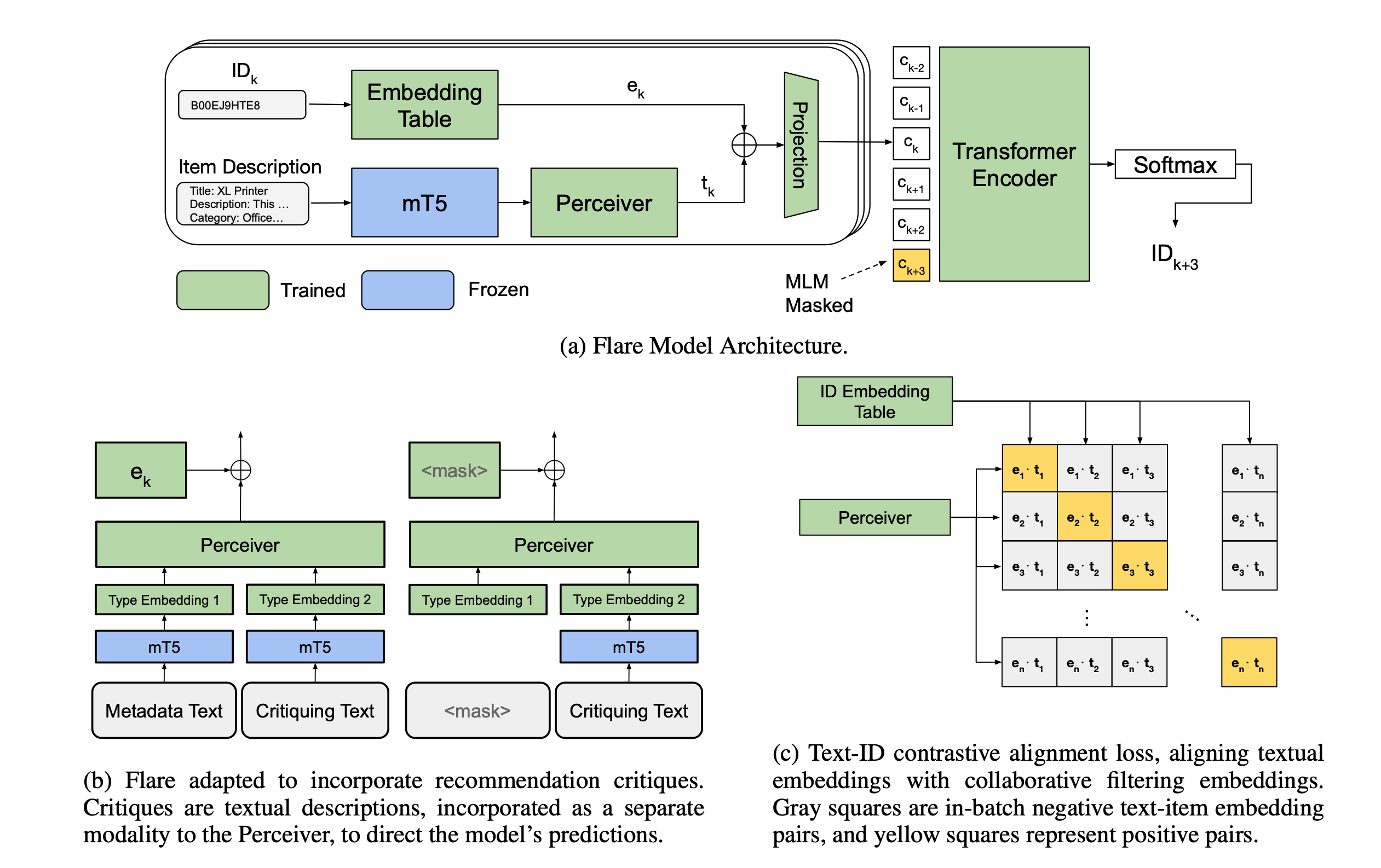
The last example trying to align semantic embedding from LLM and id embedding comes from Huawei. In this work, they proposed a framework to align this 2 types of embedding, which is suitable for most of the model architecture. Similar to the work from Google, they also adopted MLM for training, but their method steps more towards the CLIP style modeling:
- For any traditional sparse features, they are going to convert it to a text narrative (different from the Meituan’s work where the text is already available), similar to a combination of
feature name: narrative of feature valuepair. Then all sparse features’ text narrative would be concat together. During the training, some random feature is going to be masked. And then, given the LLM embedding on the text narrative, and the masked id embedding, predict the masked feature value (called MTM); or given the id embedding and masked text narrative, predict the masked text tokens (MLM) - In MLM, the id embedding is concat to all text embeddings for prediction; in MTM, cross-attention, pre-feature MLP and InfoNCE is used for prediction
- Besides the alignment within instance (feature level), instance level contrastive learning is also used
- After aligning both semantic embedding and id embedding, they are fine-tuned with downstream task via a tow-tower architecture
Cardinality of embeddings
One hidden story I haven’t talk about is how actually a raw id get converted to a dense vector through the embedding lookup table. In general, the raw id would be converted to an index within the embedding lookup table and retrieve the corresponding vector. If the total number of raw ids is not that large, we could have a 1-to-1 mapping between ids and index (in another world, the column size of the embedding lookup table is the same as the number of ids). However, if we have much much more number of ids, it is impossible to have a that large table. In this scenario, we would apply what is called hashing trick: apply a hash function on the id and mod the total column number. This means that a single vector actually represent multiple different ids which might be totally irrelevant with each other: they might be contradict with each other; or the vector is overwhelm by popular ids. In my pervious company, I have asked about this issue and proposed if we could infuse certain category information into id or id hashing function to alleviate this collision issue, but didn’t work it out due to “ruthless prioritization” ![]() .
.
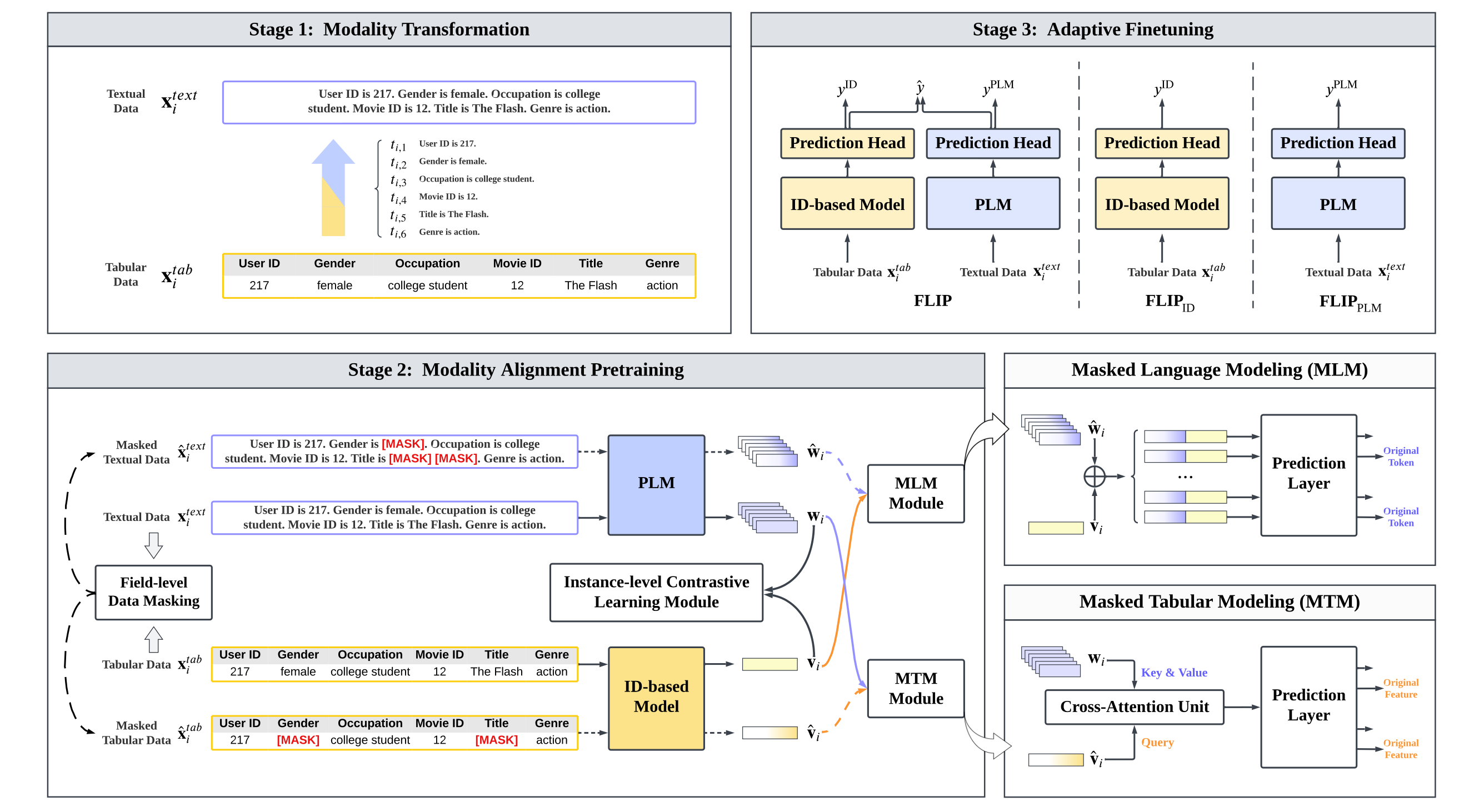
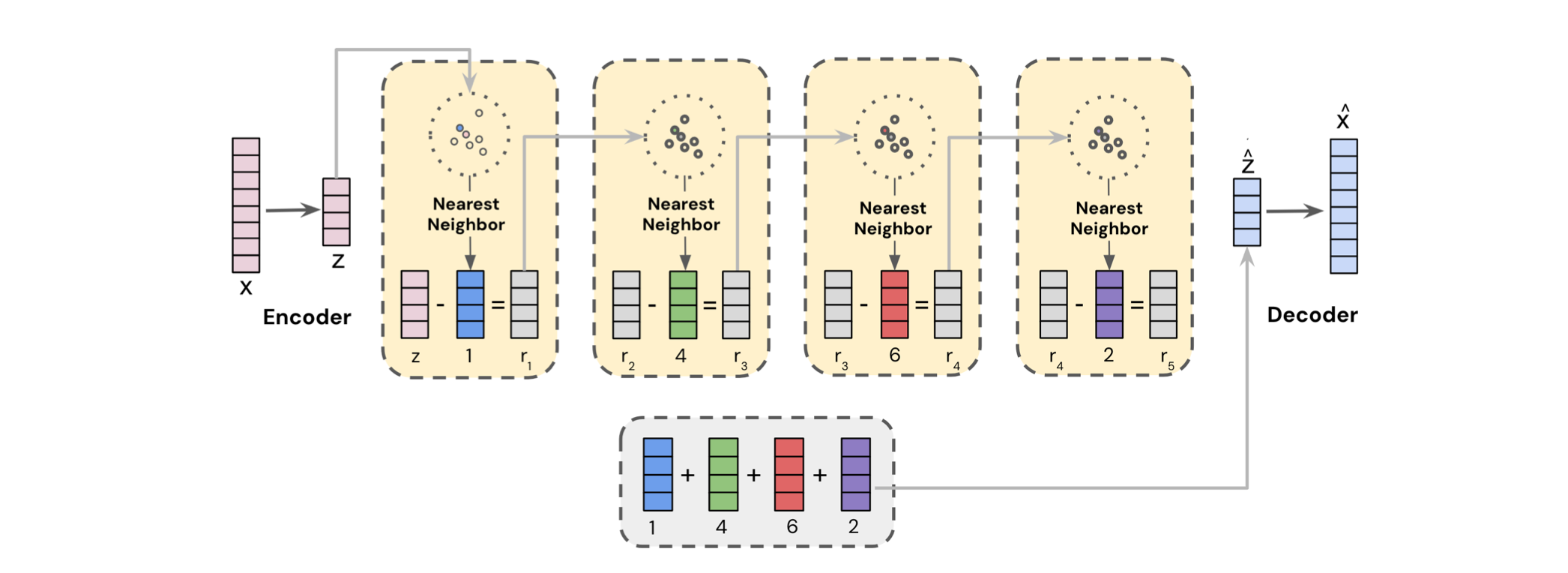
Google recently proposed a new solution similar to categorization, which is called semantic id. The high level idea is to learn a implicit hierarchy structure to index ids, so that the ids sharing similar semantic information would be grouped closer:
- The solution is composed by 2 parts: the first part learns a model to encode ids; the second part freeze the model learnt and encode ids for downstream model training
- In the first part, they adopted RQ-VAE to encode the content embeddings; the codex id within each layer of RQ is concat together to compose the semantic id. Via this approach, the ids that share similar content (because of similar content embedding) would share a similar prefix within the semantic id, but still would preserver some slightly difference in the tail part of the id. The training part follows the VAE, where the codex id’s corresponding embedding is retrieved and summed together and try to reconstruct to the input content embedding
- In the second part, based on the semantic id, we would learn another set of embedding based on them. The semantic id is a sequence of codex id, and we could use different strategy to convert them to dense vectors, we could use ngram to create different combinations, or we could use Sentence Piece Model to dynamically group them, and then go through the
embedding lookup table(here we could have a 1-to-1 mapping similar to LLM, instead of using hashing trick again)
My bet on the future trend
After reviewing these work, here is some of my bet on the future of how sparse features or embeddings going to involve in recommendation system:
- Using LLM’s output as additional input into traditional DRS model would still be the main-stream. More exploration would be done here, such as fine-tune LLM for specific downstream task to generate better semantic embeddings, adopt multi-modal LLM to ingest richer information into RS, leverage more semantic embeddings to resolve the cold-start problem
- There would be more work studying how to better combine embedding generated from LLM and traditional id embedding to improve the generalization capability of recommendation system
- In the future, the embedding might take more and more responsibility for memory and the dense layers take more on computing and reasoning; better structure of embedding would help encode more implicit information which could be unveiled during computing
- Due to the cost of inference of LLM, semantic embedding would probably still be precomputed, and this would put some new challenge on the feature serving and management infrastructure
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Acknowledgement
Thanks Yunzhong and Yitong for the great discussion on these papers.
Reference
- Efficient Transfer Learning Framework for Cross-Domain Click-Through Rate Prediction
- LARR: Large Language Model Aided Real-time Scene Recommendation with Semantic Understanding
- FLARE: Fusing Language Models and Collaborative Architectures for Recommender Enhancement
- FLIP: Fine-grained Alignment between ID-based Models and Pretrained Language Models for CTR Prediction
- Better Generalization with Semantic IDs: A Case Study in Ranking for Recommendations
Comments powered by Disqus.