Recommendation System - Long User Sequence Modeling
User sequence modeling has been a hot topic recently in recommendation system thanks to the advancement of transformer architecture and more powerful hardware. In this blog, I would like to have a simple review on the evolution of user sequence modeling work, especially long user sequence modeling. Hope this blog could inspire broader exploration ideas for the future.
Here is a quick outlets on the papers that we are going to discuss about today
- TWIN: TWo-stage Interest Network for Lifelong User Behavior Modeling in CTR Prediction at Kuaishou
- TWIN V2: Scaling Ultra-Long User Behavior Sequence Modeling for Enhanced CTR Prediction at Kuaishou
- TransAct: Transformer-based Realtime User Action Model for Recommendation at Pinterest
- TransAct V2: Lifelong User Action Sequence Modeling on Pinterest Recommendation
- LONGER: Scaling Up Long Sequence Modeling in Industrial Recommenders
- DV365: Extremely Long User History Modeling at Instagram
Now, let’s begin our journey with the ancient world.
Ancient World
User sequence essentially is a chronologic sequence of collaborative signals collected from certain domain, e.g. the feed posts that a user has viewed, clicked and commented or the ads that a user has clicked. In the past, these signals are usually processed in a reduction format, which means that we would drop the chronologic information and use a simple pooling strategy to fuse the information together, similar to the example below.

There are some issues within this approach:
- The lost of chronologic information leads to the loss of granularity on user’s short term and long term interest. There is some solution such as introducing recency wight to put more emphasis on user’s recent behavior, but still might lead to suboptimal representation of user
- The simple pooling strategy leads us not able to learn too much useful signals from user’s sequence behavior. For example, after seeing a video of NBA, user might visit sports shop for basketball. Such relationship is implicitly encoded within user’s behavior but could not be learnt once they are aggregated together.
There are some work to overcome the reduction style of user sequence handling in the past. For example, in DIN the attention mechanism (more formally, it is target attention) is introduced to selective find the items most relevant to the current ranking candidates from user’s behavior history. This helps the model to use the most effective portion of information from user’s past behavior, instead of letting those signals being averaged out.
Modern World
Transformer architecture has revolutionized the NLP world. Due to its superiority in terms of modeling relationship among tokens and inference efficiency compared to RNN, researchers also start to apply this technique into user sequence modeling. One of the most representative work is Pinterest’s TransAct model.
Before introducing TransAct, there are some common properties I have summarized from the papers I have read. I plan to use this as an architecture to explain the works that is going to be introduced in this post:
- Token representation: which refers to how the sequence is represented. For example, is each token a composition of several different embeddings, or there are different types of token (similar to multi modality) in the sequence
- Sequence length: the time span of the user past behavior to use. For example, use past 2 years history, or just recent history
- Attention type: multi head attention or cross attention
- Dimension reduction: mainly adopted for long sequence scenarios to reduce the computation time complexity. For example, use search in the sequence or directly compress the sequence to shorter length
The idea in TransAct is relative straight-forward: applying transformer encoder to user’s recent (in their paper, they called it as real-time) sequence and forwarding the output from transformer block to downstream of the model (TransAct is being a module within the entire model, other component adopted is DCNv2).
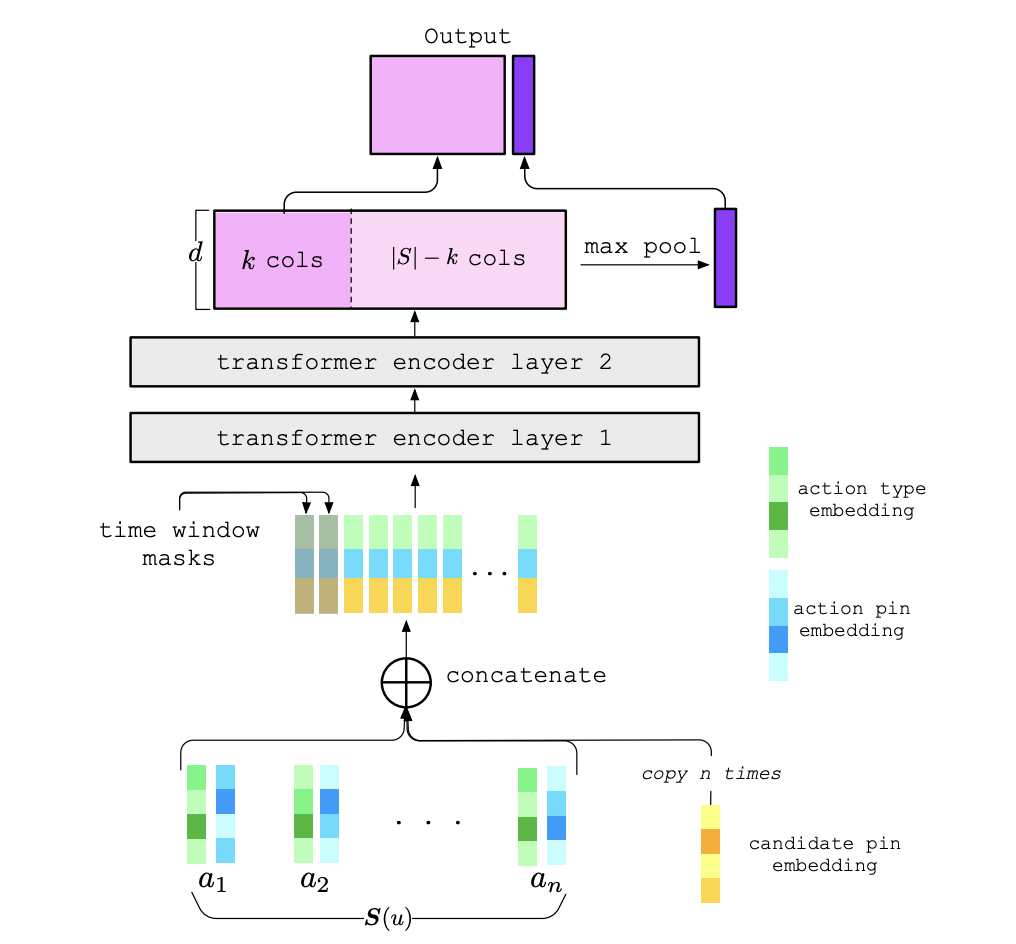
- Token representation: The token contains the positive actions from user’s past behaviors, e.g. pins clicked or shared. Each token is a composition of 3 parts, the action embedding, the interacted item embedding and the candidate embedding. The action embedding is learned during the training and the interacted item embedding and candidate embedding is from PinFormer, which could be viewed as static. These 3 embeddings are concatenated to form the final token embeddings (they compared using sum of embeddings and production the concat version).
- Sequence length: only the latest 100 user actions is used due to the training & serving cost at the time of the work; padding is used if there is no 100 actions from the user (e.g. cold-start users). Since the sequence is pretty short and to avoid model over-fitting on the last user actions, they introduced a random mask based on the request timestamp (masked attention).
- Attention type: self attention is adopted as only the encoder of transformer is used; note that the cross part of the candidate item with items user historically interacted with is implicitly handled because of the token representation.
- Dimension reduction: no dimension reduction is adopted due to the relative short length used.
The last K output of the transformer blocker + max polling of all token’s hidden representation is used as the input to the remaining part of the model; it is flattened and concatenated with other vectors such as embedding lookup output of sparse features.
Towards Longer Sequence
Due to $O(N^2)$ time complexity of the transformer blocker, it is pretty challenging to really scale to longer sequence. To make it work in practice, different solutions from infra or from modeling has been proposed.
TWIN is one of the pioneer to scale user sequence from $10^2$ to $10^4$ so that we could model user’s lifelong behaviors.
- Token representation: The feature associated with each item is converted to categorical and go through the embedding lookup to convert to the dense vector format.
- Sequence length: There are 2 stages in TWIN framework. The first stage is a general search stage where the input sequence length is $10^4$, and the second stage is exact search stage where the input sequence is $10^2$, which is the top items selected from the general search stage. This is similar to the retrieval-ranking mutli-stage arch in traditional recommendation system.
- Attention type: Multi-head target attention is adopted. This is still similar to DIN’s cross attention, but use different projection to transform the QKV into multiple heads so that each head could learn different aspect of the hidden representation.
- Dimension reduction: The technique adopted is still search style, which is top-k attention scores. In the general search stage, the candidate item is used as query to perform multi-head cross attention with $10^4$ user history interactions. And the top $10^2$ scores are selected and sent to exact search stage.

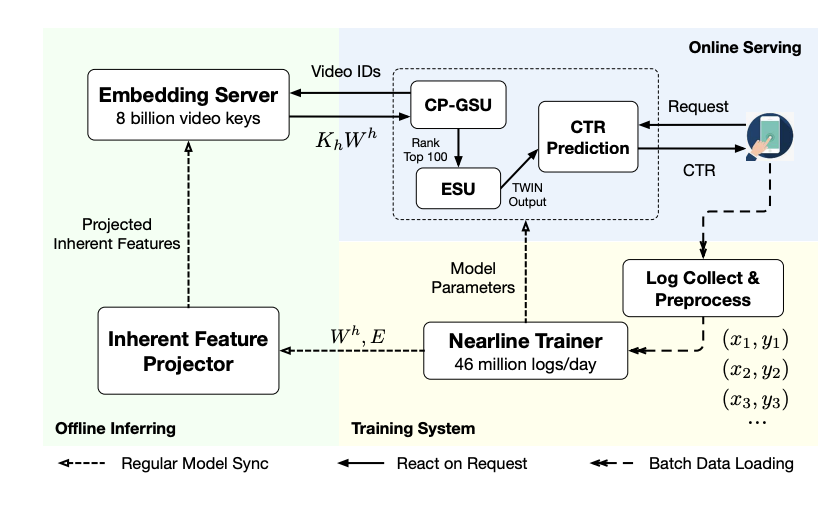
To make the computation in the general search more efficient, a feature decomposition is adopted to enable precompute & cache
- For each token representation, it is decomposed as a item specific section and a item-user cross section; each section is associated with a projection matrix $W$; the item specific part is still used as normal attention computation, and the item-user cross part is modeled as a bias term to be added to the attention scores
- After offline training, the project matrix of the item specific could be used to precompute and cached into the offline inference service. This cache is updated with the latest embeddings of items and latest project matrix synchronized from the training system to minimize the staleness of the result.
- Once there is a request comes in, the offline inference server could return the precomputed result for user’s history sequence and the remaining computation is done on the fly.
- This removes the major computation bottle neck in TWIN which is the projection of $10^4$ user sequence.
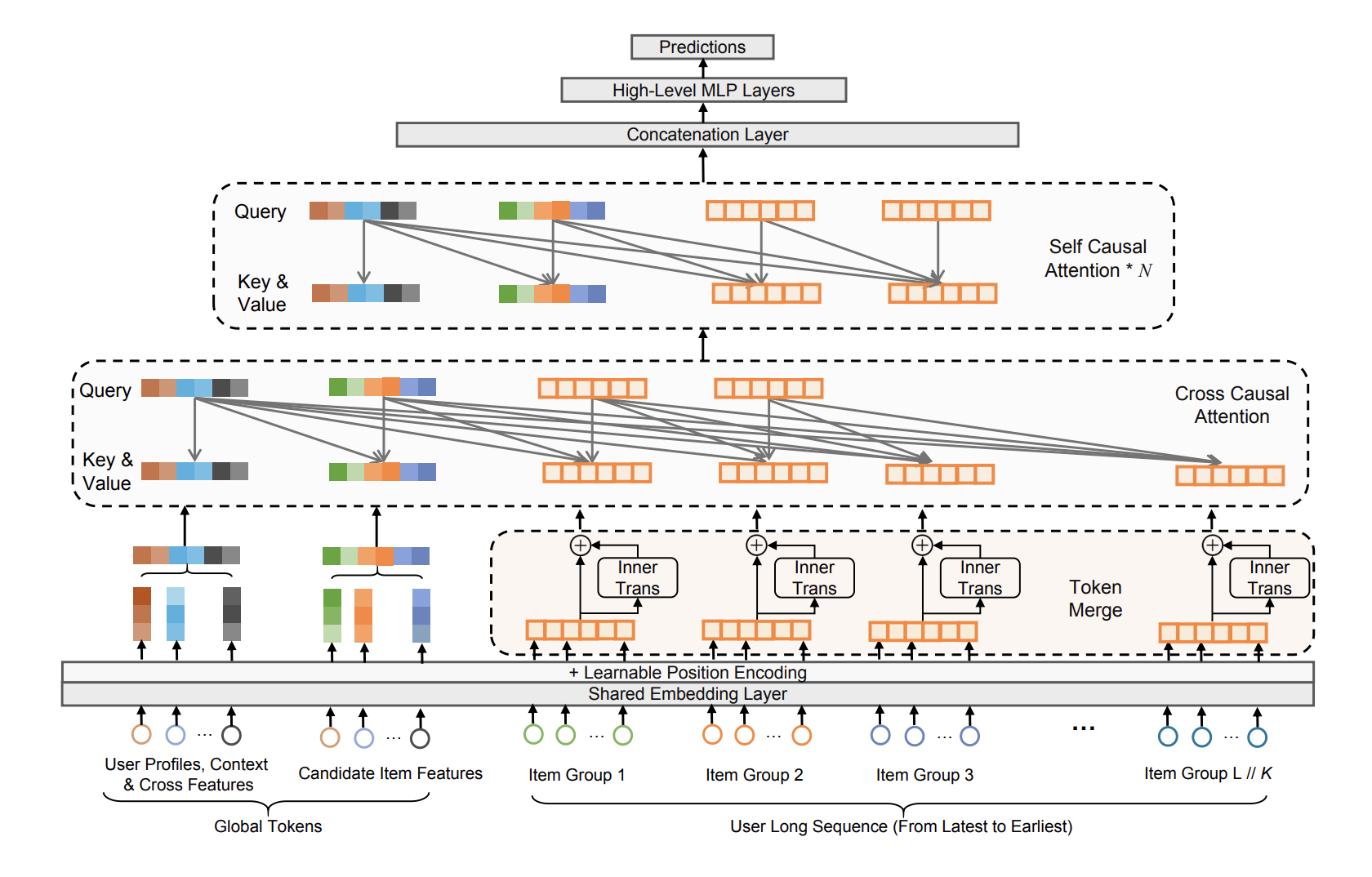
LONGER is another long user sequence work from Bytedance and it used a different approach to reduce the sequence length. Also the overall architecture is similar to HSTU.
- Token representation: Different type of features going through the same shared embedding layer, and then with the addition of position embedding. To reduce the token length, a token merge strategy is used here to merge adjacency tokens into a single one. InnerTrans block is used for this merging so that local information is still preserved after token merge.
- Sequence length: Over $10^3$ length of user history items. The construction of the sequence not only include the user history interactions, but also include the candidate item features and user profile features, which is used for construction as global tokens to interact with all all user history behaviors.
- Attention type: In the first layer, causal cross attention is used and regular causal self attention is used for the remaining layers. In causal cross attention, the global token is used as the query, along with several items retrieved from user’s behavior sequence (they find using the most recent k items yield best performance).
- Dimension reduction: As mentioned, the primary reduction strategy is through compression. Token merge is one layer of compression, cross attention on selective query tokens are another layer of compression to reduce the sequence length.
Recently Pinterest also upgrade their TransAct to TransAct V2 to scale user sequence from $10^2$ to $10^4$.
- Token representation: Static embedding is still leveraged as input (from PinSage) and candidate’s embedding is still append to each user interacted items’ embedding. However, the action embedding is not concatenated but added. Besides action embedding, surface embedding and timestamp embedding (as position) is also introduced, and also added with the item embedding.
- Sequence length: 3 sequences are introduced. Lifelong sequence length is 90th percentile of user’s past 2 years history, which is at $10^4$ scale. Realtime sequence which contains user’s latest interaction sequence scales at $10^2$ level. Impression sequence which contains user’s negative interaction (no action from users) scales at $10^2$.
- Attention type: Similar to TransAct.
- Dimension reduction: Nearest neighbor search against the candidate item is used to reduce the sequence length for all 3 sequences. After NN the sub-sequences are concatenated together to go through the transformer encoder.
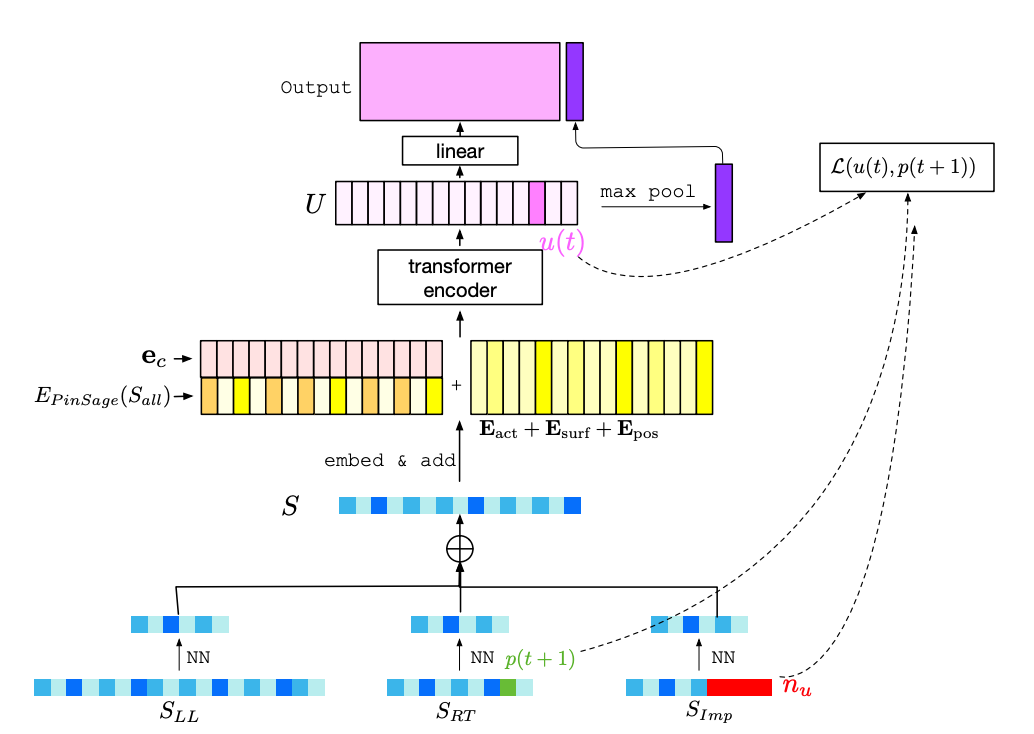
Another modeling improvement in TransAct v2 is to adopt contrastive learning to enhance the representation learning. For the hidden representation for timestamp $t$ (not that due to the causal attention ), the $t+1$ item from the realtime sequence is used as the positive samples and the 2 representation are pushed closer; while random negatives are sampled from the impression sequence to be pushed away.
Sequence Length ++
Although $10^4$ is already a pretty long sequence, researchers do not stop their effort to scale to even longer sequence.
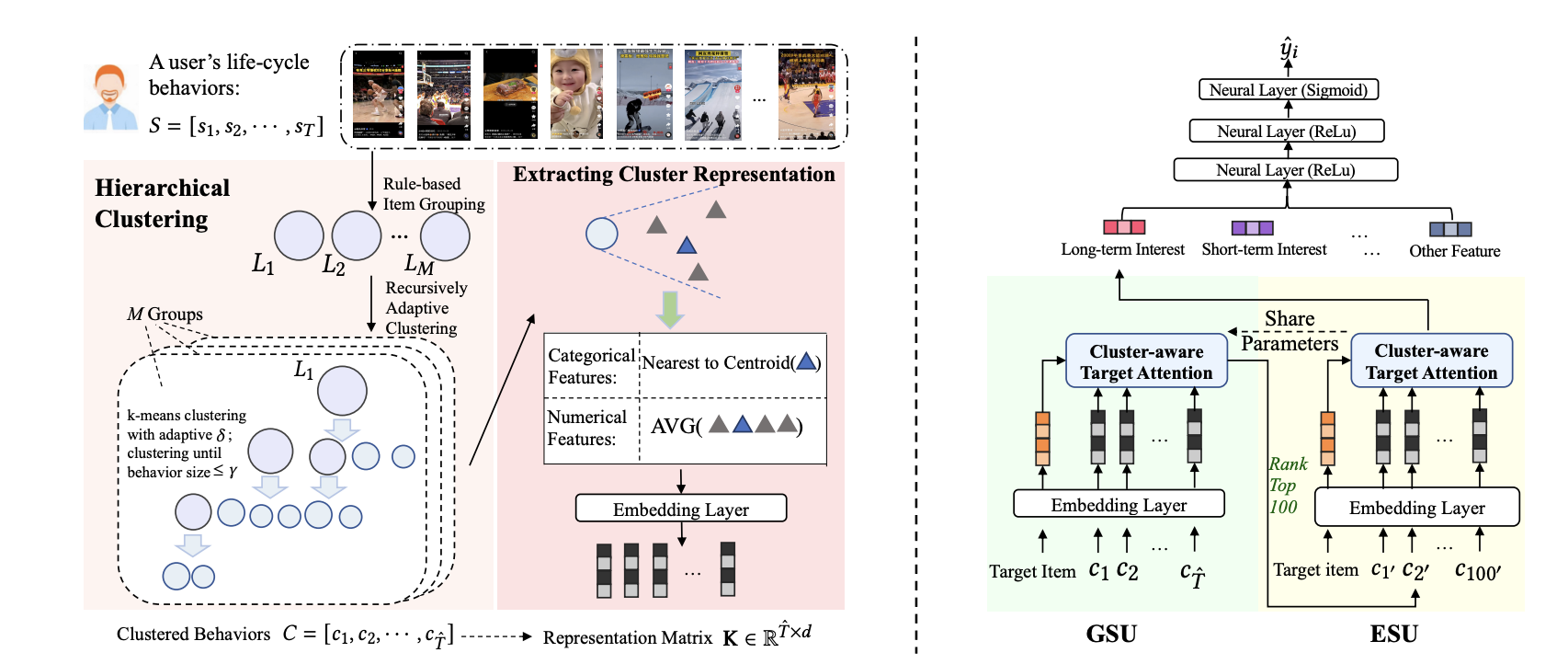
TWIN v2 is one upgrade of the TWIN algorithm and scale the sequence from $10^4$ to $10^5$. The majority of the components do not change except for the part of dimension reduction.
- Token representation: Cluster embedding which is computed through the hierarchy K-means algorithm.
-
Dimension reduction: Besides the general search and exact search unit similar in TWIN, one addition clustering based sequence reduction process is adopted to mitigate the scaling challenge. The clustering algorithm is done in 2 stage:
- In the first stage, item in users’s sequence is grouped via a heuristic approach. In the work, they group the items based on the percentage of the consumption of the video by the user.
- Within each group, a K-means algorithm is used to cluster the item into several clusters. The newly formed cluster would go through another round of K-means if the number of item within the cluster is higher than certain threshold; once the number of item drops below the threshold, this cluster is finalized and would be moved out from the process and append to global result. The item embedding used for the K-means is from the recommendation model, which means it is using collaborative signals.
- Eventually, user’s original sequence would be converted to a sequence of clusters. And the mean pooling of all items in the cluster is used as the representation of the cluster (which is going to be the new token representation).
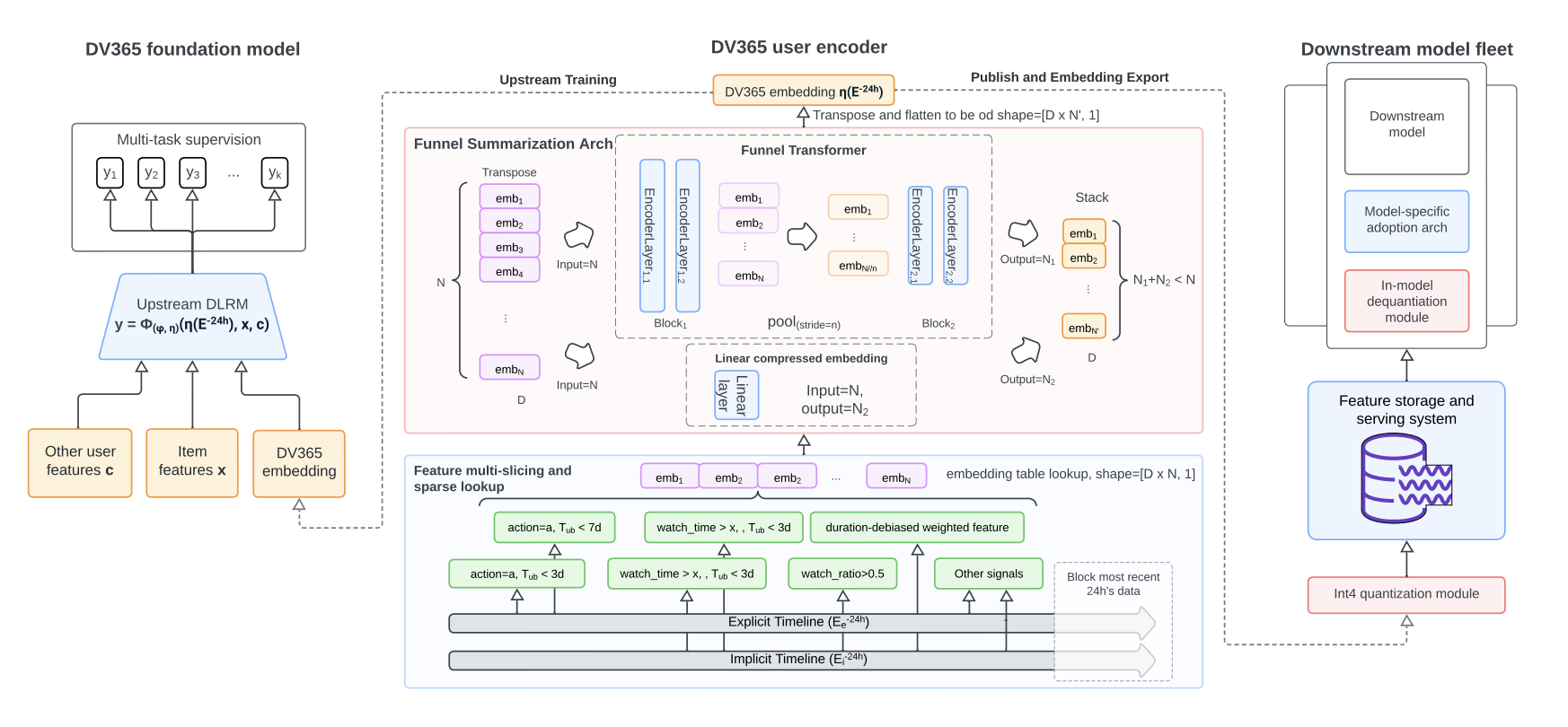
The last work is from Instagram, which is called DV365. The sequence length is also scaled to $10^5$, where the longest one is at 70000 and average is 40000. This work is used as a foundation model to generate high performant user profiling embeddings which is used as input to other downstream models. This is a relative disaggregated view compared to the work we have mentioned above.
- Token representation: Carefully manual crafted & selected features are used as the token representation. The features are bucketized (categorized) and then converted to dense representation via the embedding lookup.
- Sequence length: $10^5$ scale of length. User sequence are constructed in 2 different format, one is explicit sequence which contains users’ action such as click; and the other one is implicit sequence which contains users’ implicit reaction such as video duration & dwell time.
- Attention type: Funnel transformer is adopted, which pools in token dimension to reduce the sequence length in later stage of model. Linear compression is also adopted to compress the original sequence input and combined with the final output from funnel transformer.
- Dimension reduction: No other reduction technique is used such as item selection or clustering.
Is this end of era
The landscape of user sequence modeling has been fundamentally changed by transformer architecture and more powerful hardwares. Besides this traditional view of the user sequence modeling where it is treated as a feature processor or feature generator, there is also another disruptive stream in the recommendation area, which is Generative Recommendation. In GR, the input sequence is already changed from impression level to member level, and consume the member sequence directly as the input to predict the next item that user is likely to interact with. This is an interesting and active area, stay tune for my upcoming post!
Is GR going to be the killer for the traditional user sequence modeling work? Yes and no, and actually these 2 domain synergy pretty well with each other:
- Both needs to handle the scale of the user sequence. Right now in GR the raw sequence is still the primary choice, but we could see that lots of dimension reduction techniques used in user sequence modeling could be applied to GR as well.
- Item representation is shared. How to synergy collaborative embedding, semantic embedding, and even multi-modal in the sequence representation would still be the key.
- Inference challenging is the same. Lots of infra optimization work needs to be done to make it for online. Also how to enable incremental training and online training is also a challenging task.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Acknowledgment
This blog is inspired from a group discussion with several Daolao: Yunzhong, Daqi, Zeyu, Lili, Michael, Qiaqia. Appreciate their generous sharing idea and insights.
Comments powered by Disqus.