KDD 2025 Paper Summary
It has been a while since KDD 2025, finally I have had sometime to finish reading all papers that I interested in and summarize some of my learnings in this post ![]() . My primary focus is still on the work related to recommendation system from industry track, especially the area of user sequence modeling and the integration of LLM in recsys. Below if the follow list of papers covered in this post
. My primary focus is still on the work related to recommendation system from industry track, especially the area of user sequence modeling and the integration of LLM in recsys. Below if the follow list of papers covered in this post
- Contrastive Text-enhanced Transformer for Cross-Domain Sequential Recommendation
- Multi-granularity Interest Retrieval and Refinement Network for Long-Term User Behavior Modeling in CTR Prediction
- Applying Large Language Model For Relevance Search In Tencent
- Complicated Semantic Alignment for Long-Tail Query Rewriting in Taobao Search Based on Large Language Model
- Real-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever
- HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou
- Aligning and Balancing ID and Multimodal Representations for Recommendation
- Beyond Item Dissimilarities: Diversifying by Intent in Recommender Systems
- Improving Long-tail User CTR Prediction via Hierarchical Distribution Alignment
- LettinGo: Explore User Profile Generation for Recommendation System
- Generative Next POI Recommendation with Semantic ID
- Scaling Transformers for Discriminative Recommendation via Generative Pretraining
- Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
- MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting
Sequential Modeling
Contrastive Text-enhanced Transformer for Cross-Domain Sequential Recommendation
This work is a fusion of combining embedding alignment with cross domain together. In cross domain, there is one source domain which is usually with rich user behavior data and one target domain which is with limited behavior data. The goal is to see if there are certain underlying structure hidden behind these 2 domains so that we could learn user profile in target domain better with the insight we gain from source domain. And this source domain -> target domain flow is similar to what the embedding alignment adopted for multimodal embedding learnings.
- For each input item, there is one text encoder to convert the rich text information as text embeddings; as well as a native embedding lookup table to convert item id to id embeddings (which would be learnt during training)
- A complicated alignment between the text embeddings and id embeddings is adopted. First, a cross attention is used: the source domain’s text embedding is used as
Kand id embedding (which is rich in collaboration signal because of more data) is used asV, the target domain text embedding is used asQ; Second, self attention is applied to both text embedding and id embedding individually in the target domain; Third, the attention scores ofattn(target_text_embedding, target_text_embedding)andattn(target_text_embedding, source_text_embedding)is aligned through an operator before aggregation withV - The loss adopted is InfoNCE, users’ positive action in different domain is used as positive pairs, and other users in the same domain is used as negative pairs
- Eventually, both the user representation learnt from source domain and target domain would be concat together, and use for the traditional recommendation task
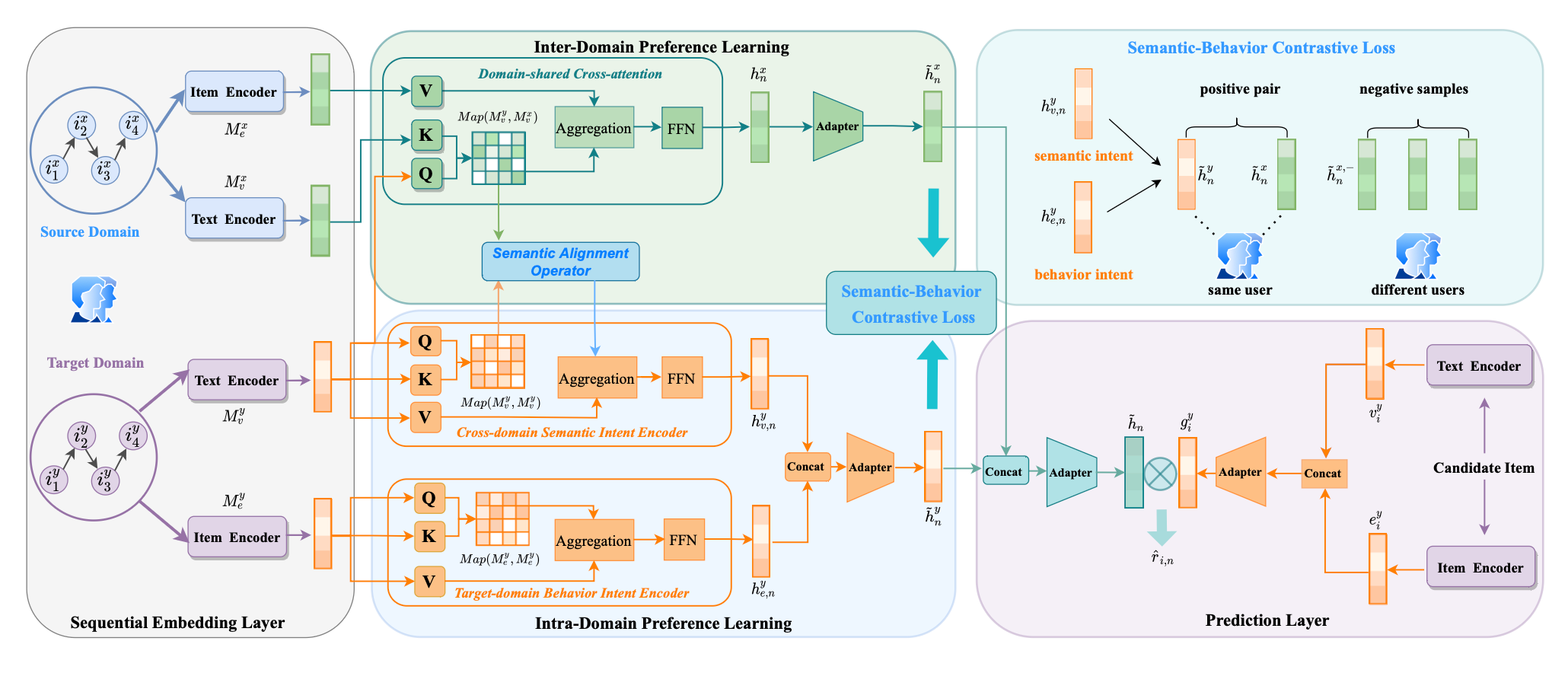
The main take away from this work is how the alignment is done: besides the classic cross attention on semantic rich embeddings, contrastive learning, the original attention scores are also used.
Multi-granularity Interest Retrieval and Refinement Network for Long-Term User Behavior Modeling in CTR Prediction
The main problem addressed in this work is related to long user behavior sequence. And the solution proposed is pretty similar to what have been adopted in TransAct V2 or OneRec, where multiple user behavior sequence sampled through different strategy is used as input to the model.
- Instead of use a single user behavior sequence, 3 sequences are used and these sequences is constructed through a query against user’s behavior sequence: First, the target item is used as query to search across user’s sequence, and SimHash is used here for quick similarity computation instead of dot product; user’s recent behavior is converted to a query via pooling of hidden state learnt from GRU; user’s life long sequence is clustered based on DPC algorithm, and use target item to query which cluster is most close
- Besides the sequence, fourier transformation is also applied to the sequence dimension to reduce the attention computation time complexity from
O(n^2)toO(nlogn); I understand the high level motivation but didn’t quite understand the implementations
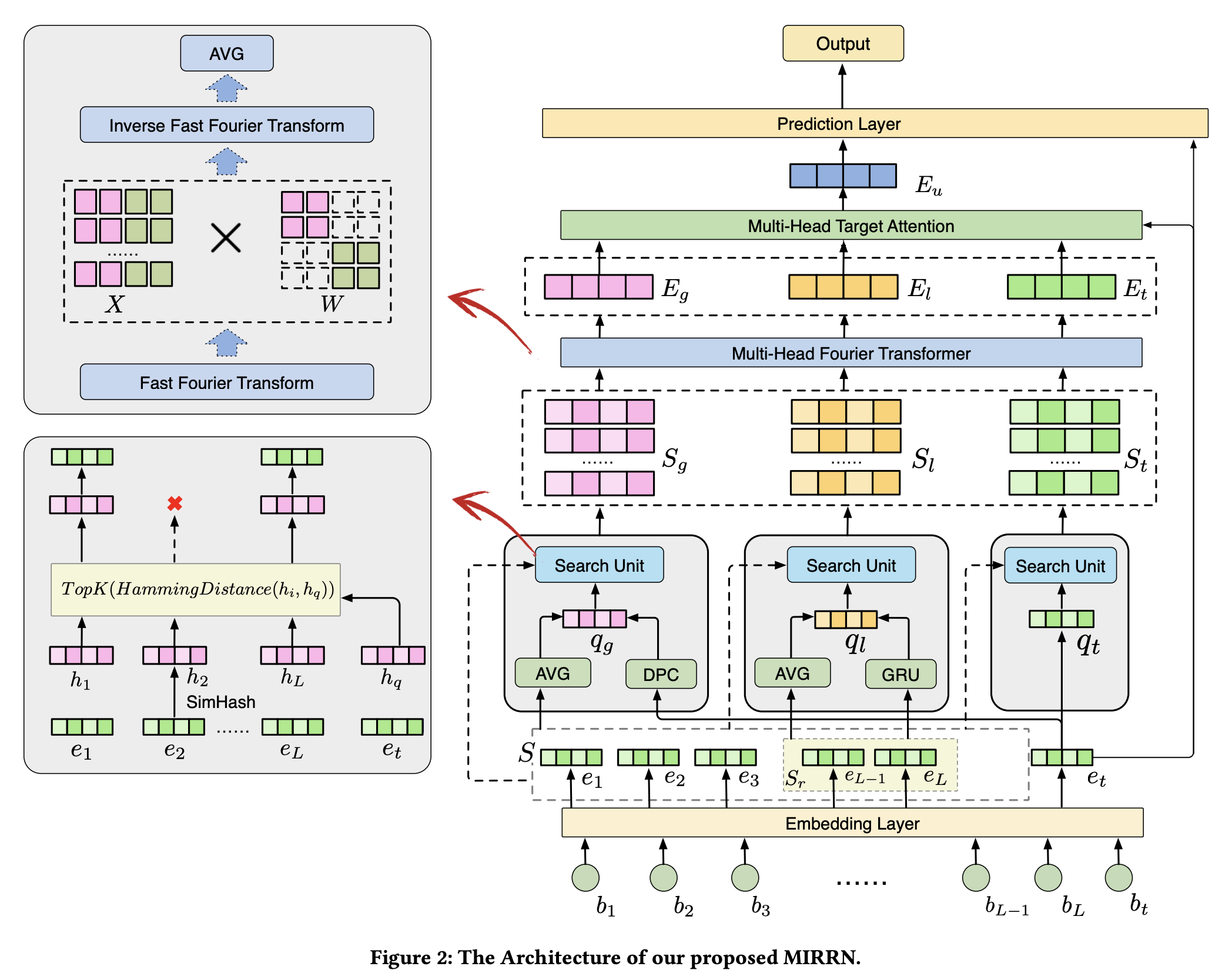
Using multiple sequence instead of single sequence to enrich the semantic and context might be a good approach? Instead of use 3N single length sequence, use 3 sequences with length N might offer similar performance but much better compute efficiency.
LLM & Search | Recommendation
Applying Large Language Model For Relevance Search In Tencent
This works from Tencent mainly explored how to apply LLM for the relevance task in search engine. This work is integrated into QQ web browser’s default search engine.
- Given a query and a document, a prompt is provided to LLM to predict the probability of the relevance scores between the query and the document, and the probability is used as weight to compute a final rank scores.
- Besides the pure query and document, certain information from the traditional search engine, such as intent and tags from query understanding component or document features, is added as tokens into prompt to improve LLM’s capability on relevance task.
- One additional exploration in the work is to use LLM as judge or LLM synergy negative examples to improve the BERT model widely used in search engine.
- Knowledge distillation from LLM to BERT is also explored. The way is to transform the
CLStoken in BERT via one additional head to match to the output from LLM head, and then do the logits level distillation
Complicated Semantic Alignment for Long-Tail Query Rewriting in Taobao Search Based on Large Language Model
This works from TaoBao introduced how LLM is leveraged for search query rewrite, especially for the long-tail queries. The main problem in this scenario is that the query from user might be pretty different from merchant’s description of the item. How to write the query so that the language of users and merchants could be on the “same page”, while still perverse users’ original intention, is a challenging problem. The solution in this work proposed is to fine tune LLM for query rewriting and alignment.
- A high quality SFT dataset for query rewrite is proposed. Starting from the search log, several long tail queries are identified via certain heuristic rules; then leverage LLM to rewrite query and human to annotate the quality of the rewrite; during the generation of rewrite, a RAG-styled prompt technique is used
- One alignment dataset for user query and merchant product description is also provided. Based on the SFT LLM, several rewrite query is generated and human to annotate if the rewritten query still captures user’s original intent; and the rewritten query is also send into query engine for retrieval, and the recall volume is treated as the feedback
Aligning and Balancing ID and Multimodal Representations for Recommendation
One work from Kuaishou about multimodal embedding and id embedding alignments. The technique used in multimodal is relative standard. The novel part is how multimodal embedding and id embedding is aligned. Instead of using the traditional cosine distance, Wasserstein distance is used. Another technique they proposed is a gradient module to dynamically adjust the predict power of the id embedding and multimodal embedding, to avoid one overwhelm the other during training.
LettinGo: Explore User Profile Generation for Recommendation System
User profiling is one critical parts in recommendation system, it helps the system to understand user’s interest so that more matching items could be delivered to users. Traditionally user profiling is learnt from data and usually captured via embeddings (e.g. an embedding lookup table for user ids).
In this work, LLM is used to summarize a user profile in text based on user’s history. Different LLM is leveraged to generate a diversified user profiles (this is called profile exploration stage). Once the user profiles are generated, they are sent into recommendation model for prediction, along with user’s history and a target item. The model’s prediction and the ground truth could be collected as positive and negative samples for DPO fine tuning.
Improving Long-tail User CTR Prediction via Hierarchical Distribution Alignment
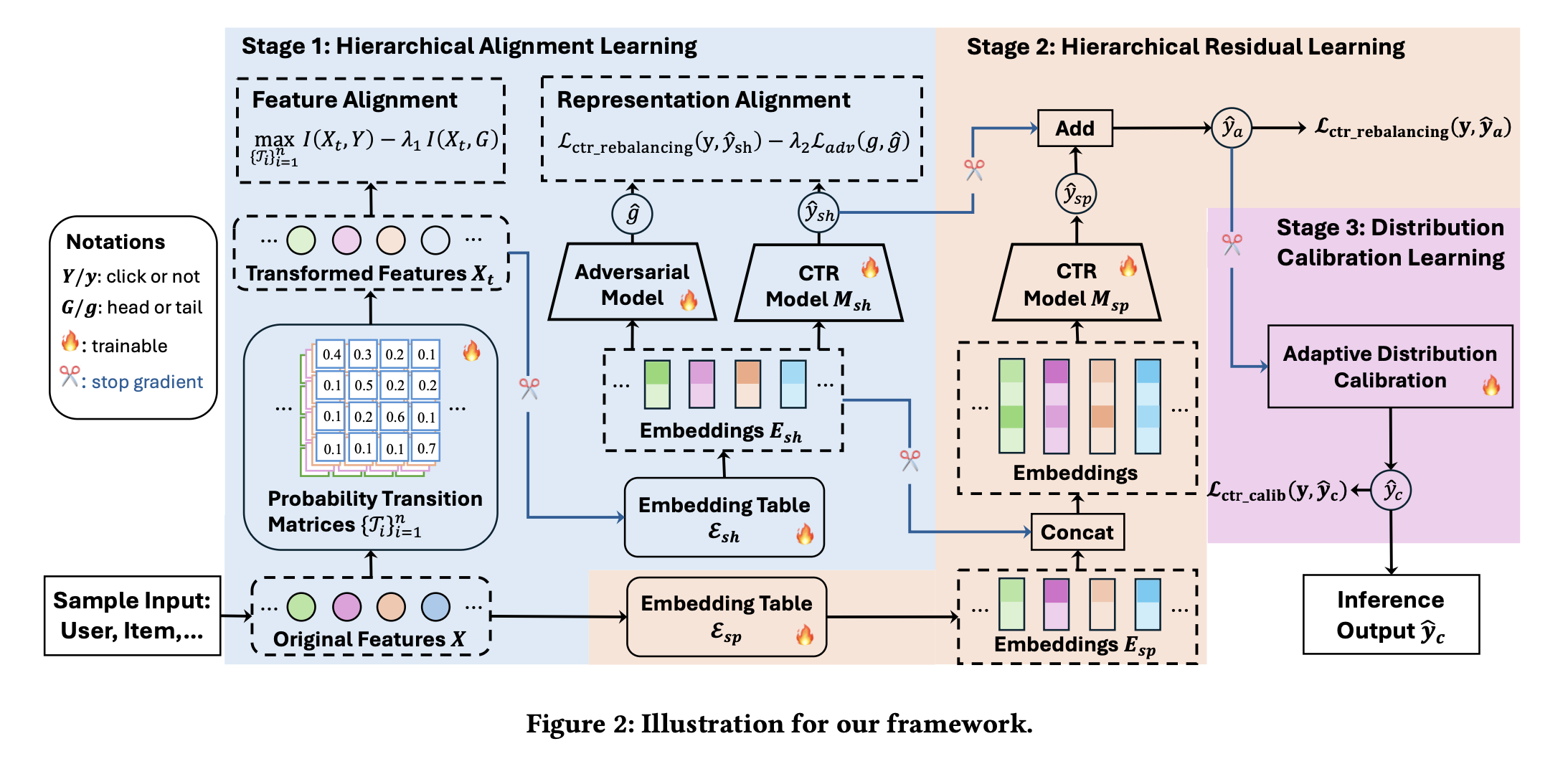
This work from Kuaishou main focus on the long tail user issue in recommendation system. Because of the data sparsity, it is challenging to learn good knowledge/insights about long tail users.
- In this work, the problem is modeled similar to transfer learning, where the head users and long tail users are treated as 2 different domains, and we leverage the rich knowledge about head users to boost the learnings of long tail users. To extract the shared knowledge among head users and long tail users, a feature probabilistic mapping (which transforms the original input feature into another format) is used for feature decoupling, and adversarial learning is adopted for representation learning.
- The training data is reweighted to balance the bias introduced due to downsampling of head users data. The weight is computed within each batch. And a dedicated Beta calibration is introduced due to the CTR sensitive task (trained on an individual dataset)
The feature probabilistic mapping is a new technique to me, plan to learn more details about this and see if it could be applied to the project that I’m working on.
Scaling Transformers for Discriminative Recommendation via Generative Pretraining
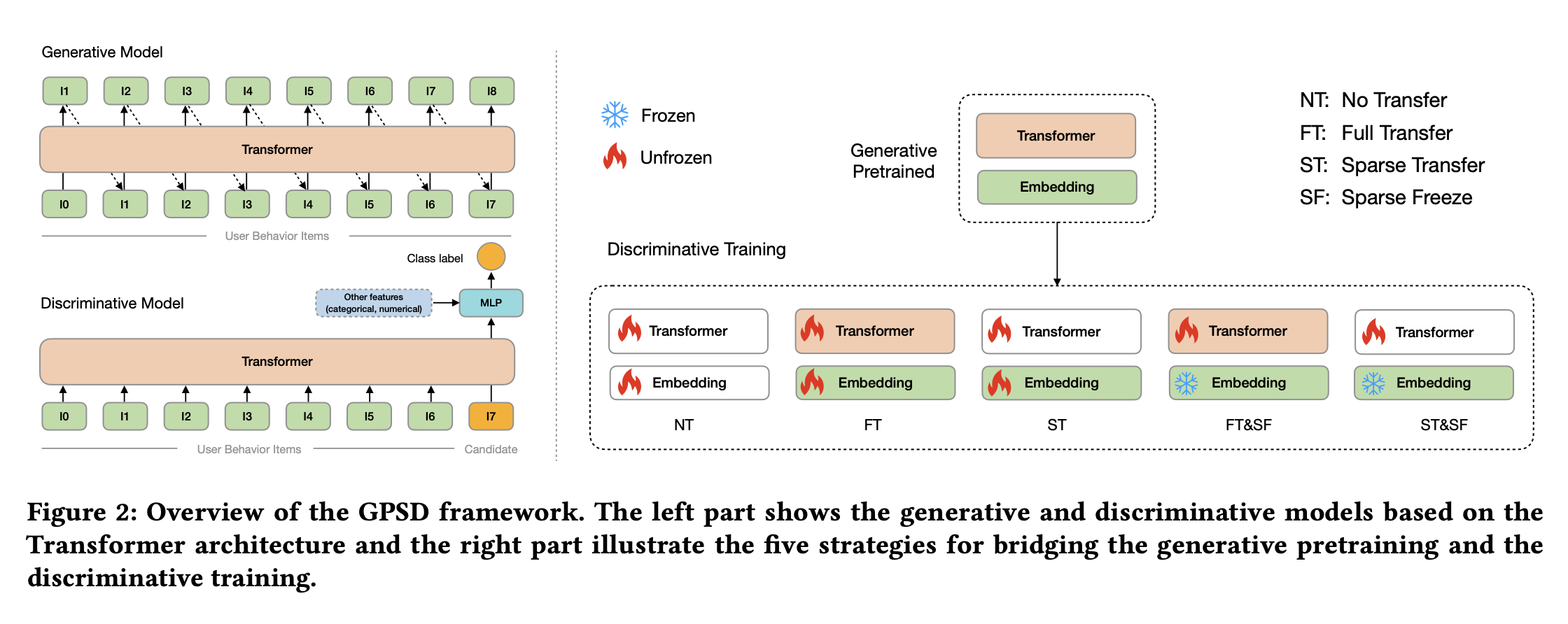
This works from Alibaba applied pretraining technique widely used in LLM training to CTR prediction model training to mitigate overfit problem.
- A foundation model is first pre-trained similar to how GPT is trained: user sequence item id is used as input tokens and use next token prediction as the loss (sampled softmax is used due to the large vocab size); other feature such as category features are converted to embeddings and sum into id embeddings. During NTP, these features are also being predicted as part of the loss.
- The final ranking model is using transformer architecture, the best transfer strategy discovered is Full Transfer + Freeze Sparse, where all parameters from the pretrained model is transferred and all sparse parameters (e.g. id embeddings) are frozen and not updated during training.
Semantic Id
Semantic id is becoming more and more popular. It offers infra benefits compared to the original dense embeddings. In my opinion, it is critical to generative recommender as it is a more efficient and compact tokens to represent items compared to plain text.
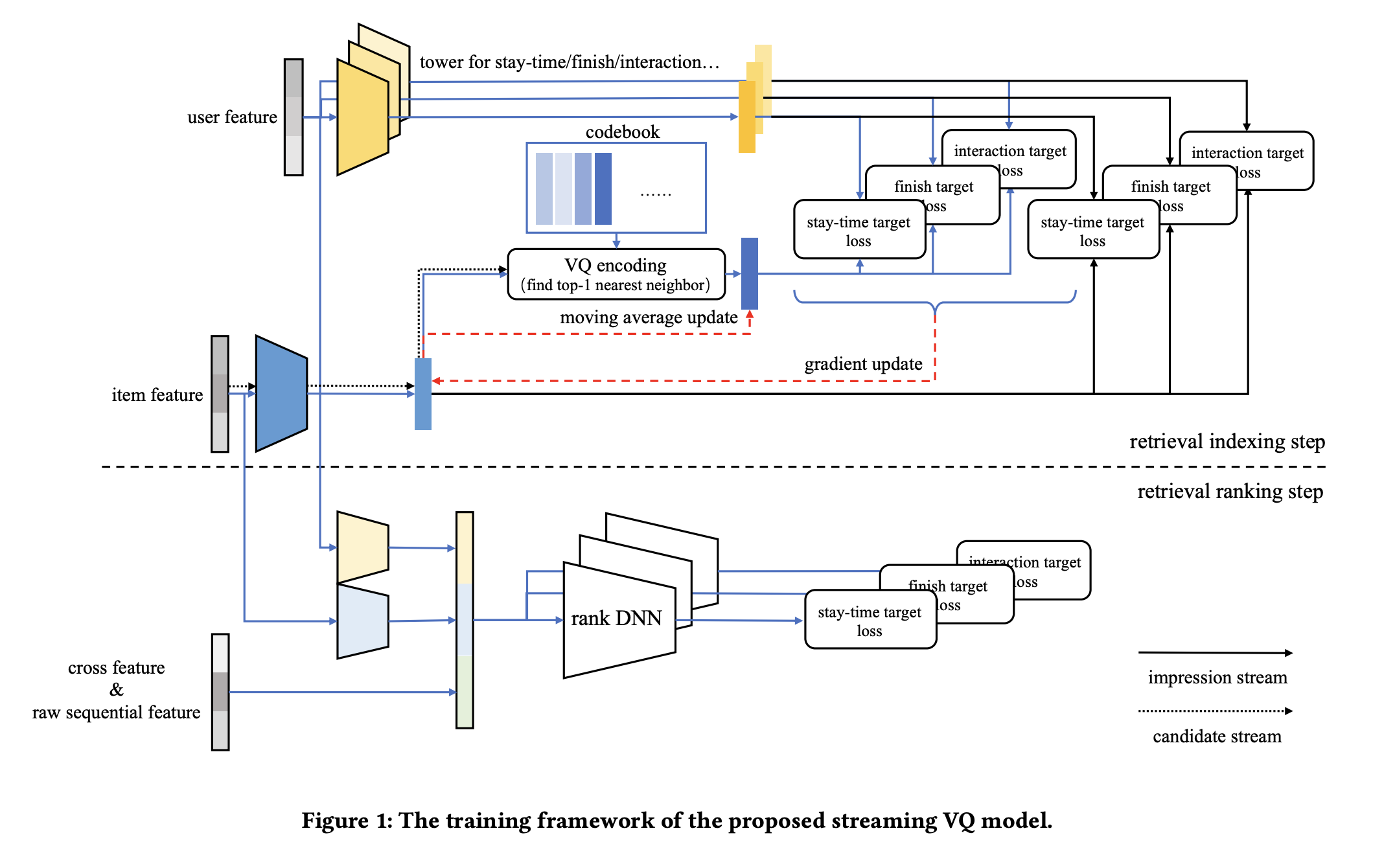
Real-time Indexing for Large-scale Recommendation by Streaming Vector Quantization Retriever
This work from Bytedance discussed about the idea of adopting Vector Quantization (VQ) to retrieval index, which outperforms the traditional way of embedding index such as HNSW.
- During the training, still using the classic tow tower model to model user and item embeddings separately. Additionally, each item embedding would go through the VQ stage and top-1 neighbor is selected as cluster. Once item embedding is updated, the cluster embedding would not be updated immediately (via stop gradient op), and a moving averaging is used to compute cluster embedding based on the items assigned to this cluster.
- During serving, the cluster is first ranked based on the target item, only item from the top cluster would be considered and move to the next stage.
- The loss is compounded by two parts, one is computed over the cluster embedding and user embedding; and the other is the computed over the original item embedding and user embedding.
- The benefit of this approach is that the index update time is essentially the same as the model update time; since the cluster assignment happened during the model training stage; also, compared to FAISS, the cluster embedding is optimized the downstream task.
- For long tail items, a dedicated candidate stream (instead of the impression stream used for online training) is used to make sure that the long tail items is being assigned to the right clusters based on latest cluster embeddings learnt.
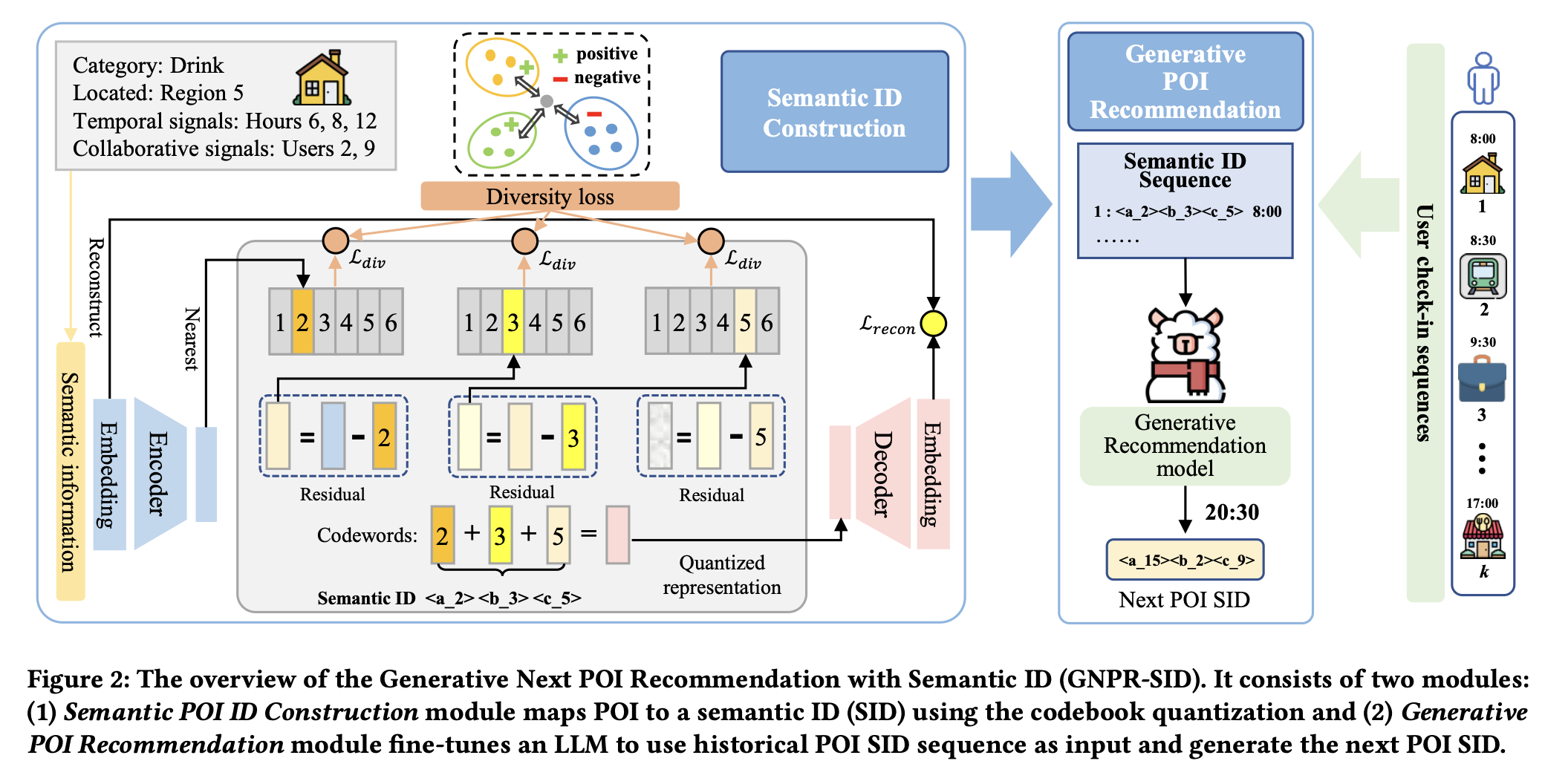
Generative Next POI Recommendation with Semantic ID
A work that leverages semantic id for POI recommendation. This could be a good example to learn how to integrate semantic id into recommendation model.
- The input used for semantic generation includes category, region code, timestamp bucket and user collaborative signal; it is a little surprise to me that no text or image information is used (probably due to data accessibility problem)
- The algorithm used is still RQ-VAE, one diversity loss is introduced to make sure the codebook is in good utilization as well as too much conflicting semantic is collapsed into the same index
- SID is hard prompted for generative recommender, which is a classic way to use SID for ranking models
Recommendation System Tradition Problem
HoME: Hierarchy of Multi-Gate Experts for Multi-Task Learning at Kuaishou
This work from Kuaishou addressed several common problem encountered when apply MOE to multi-tasking learning scenarios.
- Expert collapse, where only a few experts are being used. The solution proposed here is to add a normalization to the experts output.
- Expert degradation, where shared experts are only used by one or two tasks instead of benefitting all tasks. The solution proposed here is to category the tasks into categories and use the category level gate to aggregate the information and route.
- Expert Underfitting, where some task that are sparse in data would only use shared experts instead of leveraging task specific tasks as well. The proposed solution is to introduce a feature gate to transform the input features into multiple facets, which is similar to the multi-head projection used in transformer. One benefits of this approach is that it could prevent gradient from different tasks to collapse.
Beyond Item Dissimilarities: Diversifying by Intent in Recommender Systems
One work from Google which provide a new approach for rerank diversification. Rerank usually is the last step in the multi-stage ranking system, where the ranked item went through another round of ranking based on certain business needs, such as avoid putting the similar items next to each other. In this work, user’s intention plays a key role to diversity the results.
One model is built to predict user’s intention. The model’s architecture and input is similar to the one widely used for ranking, but the challenging part is labeling as there is no explicit intention given by users. Some heuristic rules are used here to define user’s intention based on their behavior on homepage.
The next step is a relative complex algorithm using Bayes formula to adjust the item scores based on user intention. In an iterative process, the item with highest scores are selected, once an item is selected, the user’s intention distribution would also be updated in a counterfactual way (if intention intent_a is selected on position m, then intent_a’s probability in user intention distribution should be lowered on position m+1, because if user goes from m to m+1, then it means that user does not have intent_a).
Agentic
Empowering Economic Simulation for Massively Multiplayer Online Games through Generative Agent-Based Modeling
This is a work from NetEase, one of the largest web/mobile game company in China. In this work, they leverage agentic to understand the economy behaviors within the game (e.g. trading between players)
- They built a simulated environment for the agents to interact; the action space of the agent is also structured to limit the over complexity
- Each agent is bootstrapped with certain user profile to mimic different style of players
- Self-reflection through LLM and long/short term memory are also integrated with the agent
This work is similar to the pervious sand-box style work “AI-towns”. If you are also interested in building something similar, highly recommend this paper as a referral.
MockLLM: A Multi-Agent Behavior Collaboration Framework for Online Job Seeking and Recruiting
A work from BOSS, which is a job hunting platform in China, regrading using LLM agentic to simulate the process of job matching. The agent is integrated with reflection mechanism for both interviewer and candidate; interviewer would evaluate the performance the candidate and see if he is a good fit; candidate would also evaluate the process and see if he feels the job is good match for him. The result generated from these simulations are used to guide the job matching on the platform.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.