How to use LLM for recommendation task
Recently, I have been working with some of my friends (Dalao) on leveraging GPT to do recommendation tasks. This gives me an opportunity to review some paper in this field. In this post, I would like to summarize some of my learnings along the journey.
Some key take away:
- LLM internally has encapsulated lots of knowledge about the world and it could leverage these knowledge to do some general recommendation (such as Movie)
- In context learning is a powerful technique to inject various information into promote to provide more context for LLM, such as user profile and user past interaction history
- Use training data that specifically constructed for recommendation task to fine tune LLM could further improve the performance of LLM
- We could directly use LLM to output candidate, or use LLM output as additional signal to inject into existing recommendation models
PS: due to the rapid change of this area, the paper I read might have been outdated. Please feel free to leave comments on the latest work/idea in this domain. Also I’m reading the latest paper from arxiv and will potentially have a new series of post on summarizing the latest work in LLM and ML area, stay tuned! PPS: I would primarily summarize my understanding without to much technical terms and mathematic formula; the main goal is to grasp the high level idea of the paper
Context
In classical recommendation system, we usually adopt a 2-stage architecture. In first stage, we adopt heuristic rule, or leverage some simple model to quickly identify some promising candidates from the entire eligible population (actually, there is indexing step before here as well, but for simplicity, let’s skip that). This first stage is called candidate retrieval, which we usually optimize for recall. In the second stage, we would rank the candidates we retrieved in the first stage, via more signals and more powerful model. This stage is usually called rerank, which optimize for precision.
Pairwise Ranking via LLM
In paper “Large Language Model Are Effective Text Rankers With Pairwise Ranking Prompting”, the author proposed a new format of prompt that let LLM to rank a pair of candidates given a query, which outperforms the point-wise and list-wise format. The format of the prompt is as follow:
1
2
3
4
5
6
7
8
9
f"""
Given a query {query}, which of the following two passage is more relevant to the query?
Passage A: {description of A}
Passage B: {description of B}
Output Passage A or Passage B
"""
For each pair of candidates, we use the above prompt to let LLM output the choice, and compute the final scores as
\[s_{i} = 1 * \sum_{j \neq i} I_{d_{i} > d_{j}} + 0.5 * \sum_{j \neq i} I_{d_{i} = d_{j}}\]and rank the document accordingly.
Enrich the information for LLM to recommend
Personalized recommendation is critical to improve the conversion rate. Use profiling, user past’s item interaction history bring valuable signal for recommendation. In this section, we will take a look some idea on how to inject such information into prompt to let LLM “learn” the flavor of user and provide better personalized result.
In “Is ChatGPT a Good Recommender? A Preliminary Study”, the authors proposed different type of prompt of different type of tasks. These prompt could be decomposed as task descriptor, user-specific injection, formatting restrictions. User-specific injection is the part where we add user’s past item interaction info. The format for sequential recommendation is as follow (content in bracket is comment)
1
2
3
4
5
6
7
8
9
10
11
f"""
Requirement: you must choose 10 items for recommendation and sort them in order of priority,
from hightest to lowest. [task descriptor]
Output format: a python list. Do not explain the reason for include any other words. [formatting restrictions]
Given user's interaction history in chronological order: {[i_1, i_2, i_3, ..., i_n]},
the next interaction item is {i_n+1}. [In context learning]
Now, if the interaction history is updated to {[j_1, j_2, j_3, ..., j_n]} and the user is likely to interact again,
recommend the next item. [user-specific injection]
"""
In this prompt, a common technique, which is called in context learning, or few shot prompting , is used. By showing LLM some examples to follow in the prompt, we could change the underlying distribution of LLM model and bias it to generate the output conditionally on the examples we have given. This stanford blog is a great source to learn more on how in context learning works. In short words, the additional example we provided helps LLM to better locate concept internally, and thus more aligned. A Bayesian inference view on that is as follow, which is pretty easy to understand
\[p(output|prompt) = \int_{concept}p(output|concept, prompt)p(concept|prompt)d(concept)\]In “PALR: Personalization Aware LLMs for Recommendation”, author adopted similar approach to integrate users’ past interaction into prompt. One novel idea in this paper is to leverage LLM to generate user profile, which leverages the summarization capability of LLM. The prompt is as follow (use MovieLens-1M as example)
1
2
3
4
5
6
7
8
9
10
f"""
Input: Your task is to use two keywords to summarize user's preference based on history interactions.
The output is an itemized list based on importance. The output template is:
{KEYWORD_1: "HISTORY_MOVE_1", "HISTORY_MOVE_2"; KEYWORD_2: "HISTORY_MOVE_2"}
The history movies and their keywords
"MOVIE_1": KEYWORD_1, KEYWORD_2
"MOVIE_2": KEYWORD_1, KEYWORD_3
"MOVIE_3": KEYWORD_4
"MOVIE_4": KEYWORD_1, KEYWORD_3, KEYWORD_4
"""
Then the user profile is also input into the prompt to let LLM recommend items from the candidate set.
In context learning is a technique that I widely used during my project. It is much cheaper compared to fine-tune LLM, and the performance is also pretty good as long as you have high quality data. From my experience, formatting control is pretty challenge and sometimes could not be 100% solved by explicit instructions or few shot. Sometimes, we need to have some dedicated business code to do some postprocessing on LLM output to parse the part we interested most out.
Go beyond In-Context Learning: Fine-tune LLM for recommendation task
In context learning is a powerful technique, however, due to the fact that LLM is trained on NLP task instead of recommendation task, its performance is still sometime limited. Using some training data that is specifically constructed for recommendation to fine-tune LLM could help LLM to learn more for recommendation task.
In TALLRec: An Effective and Efficient Tuning Framework to Align Large Language Model with Recommendation, the author proposed a 2-stage fine-tuning framework. In first stage, they leverage Alpaca Tuning to improve LLM’s generalization ability, and then in 2nd stage, they use recommendation training data to do rec tuning. The format of the training data is as follow
1
2
3
4
5
6
7
8
9
f"""
Task instruction: Given the user's historical interactions, please determine whether the user
will enjoy the target new movie by answering "Yes" or "No".
Task input:
- User's liked items: GodFather.
- User's disliked items: Star Wars.
- Target new movie: Iron Man.
Task output: No
"""
A high level flow is as follow 
Work with existing Recommendation models
Besides directly let LLM to output the recommendation from the candidates, we could also use LLM together with existing recommendation models. Use the output of one model as input to another model has been a widely adopted practice in the ranking world, e.g. using the GBDT leave as feature in NN. You could think of that we leverage model to do some compression and preprocessing on the signals, which is similar to traditional feature engineering.
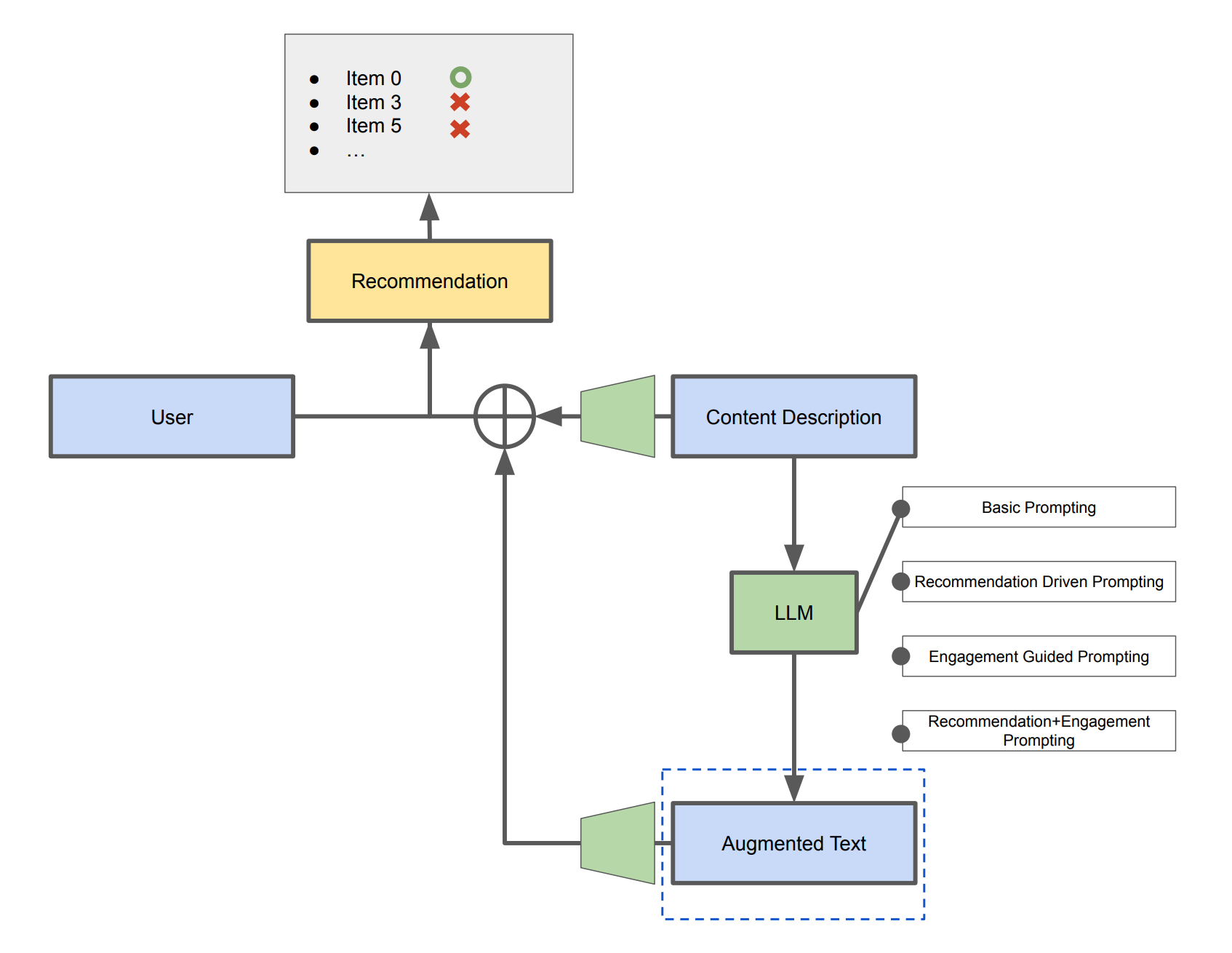
In LLM-Rec: Personalized Recommendation via Prompting Large Language Models, the author used different prompt to generate various text description from the original content, and then embedding them as additional signals and feed into MLP for ranking together with the original descriptions. Below is a high level architecture of their model
Comments powered by Disqus.