How to Design Auction System
In this post, let’s discuss a little bit how to design an auction system similar to the one on eBay, where owner could list their items in the system and others could place a bid on it. User with highest bid would be the winner of this auction and could buy it.
In a real world auction system, there are lots of components involved, such as the search (user could search active auction based on their interest), payment (winner need to make the payment) and inventory (owner could add new items). We would not dive deep into these components, but would only focus on the auction service itself. For search and payment, I plan to have other posts to discuss them in depth.
In this post, we would discuss 2 different ways to design the auction system, stateful and stateless, and see what would be their pros and cons. In reality, stateless is more common, while stateful design still play a critical role in different use cases, e.g. stream processing.
Functional Requirement
We would assume the following functional requirement to be offered by our system
- User could start an auction
- User could view the active auction, and place a bid in the auction; user could also get realtime update on the current highest bid
- Auction is closed when there is no higher bid for 1 hour
- Winner of the auction would receive notification and has 10 minutes to make the payment
Non Functional Requirements
- High availability
- High scalability
- Low latency
- Eventual consistency is acceptable for live bidding part (we could discuss for higher consistency level), but when determine the winner of the auction, it needs strong consistency
- 1B DAU, 100k auctions per-day, on average 10% of user place 1 bid per day, assume 10:1 read:write ratio
Some questions to clarify
- What if there are multiple bids with the same price, who would be the winner?
- The first bidder would be the winner
- Do we allow a bidder to place multiple bids within the same auction?
- No, each bidder could only place 1 bid, but they could increase their bid if their original one is not winner
- Do we need to record all bids that user placed during the auction?
- This is great question, let’s keep all bid that users have placed instead of just winners
- What shall we do if there is no bid for certain auction, do we need user to provide a TTL?
- Let’s simplify the problem as of now and assume there is no TTL required
High level design
Newton has said that
If I have been able to see further, it was only because I stood on the shoulders of giants
In this design, we would also stand on the shoulders of giants, which is live comment and cron job scheduler.
Auction creation
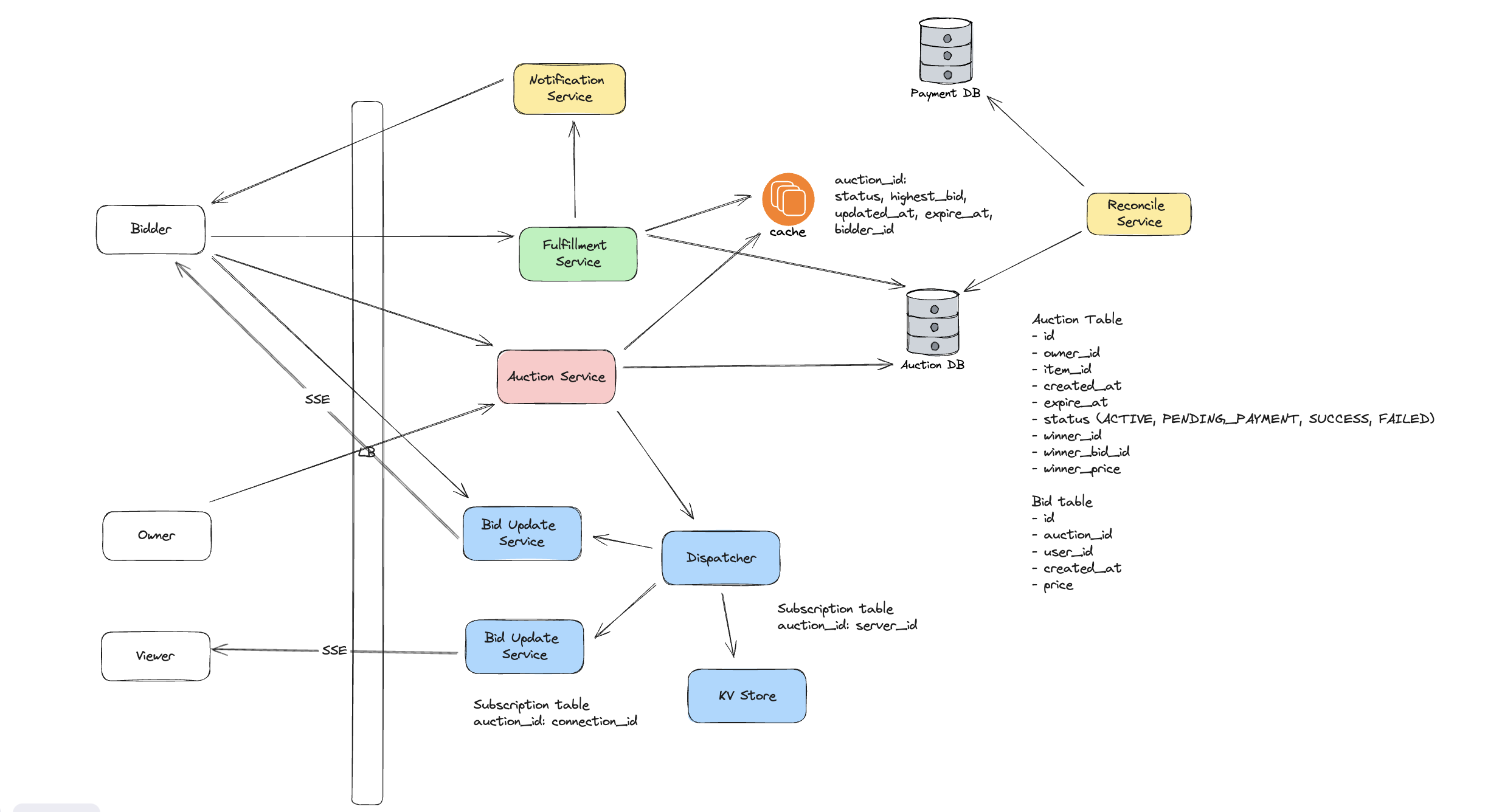
This part is relative simple. We have Auction Service to handle the creation HTTP request from user. The auction service would write a new entry to the auction_table within Auction DB and update to cache. Below is an example schema of our auction table. Besides the regular metadata such as owner_id, item_id and created_at, there are 2 important fields, status and expire_at, which is critical for us to manage the transition of auction and handle the payment.

When we create a new auction, we would also update it into the cache and mark it as a ACTIVE auction. This design choice actually makes our auction service stateless: it does not need to maintain any data on the server regarding the auction. If it needs to know the status of an auction, it would query the cache and then do the necessary processing. The cache is primarily used to help us improve the read performance regarding the highest bid for a given auction. If DB write or cache update fails, we would return failure to client and client would retry the creation.
There might be issue that the status in cache and in Auction DB are inconsistent, we would dive deeper into this topic in Cache and Auction DB consistency section.
Auction Bid Place and Update
For this part, there are 2 key problems we need to answer:
- the connection mechanism between client and our service
- the mechanism to route highest bid to users who are viewing the current auction
For the first problem, we would use a combination of HTTP request and server sent event (SSE): to place a bid, we issue an HTTP request to Auction Service; while to receive highest bid from others, we leverage SSE connection with Bid Update Service. Other connection options are HTTP long polling and websocket. HTTP long polling is relative less efficient because client needs to repeatedly query the backend for new bids. Websocket is a little bit over killing in our scenario as we don’t expect each user viewing the auction actively place bids, thus a single direction connection is sufficient. However, websocket might also be applicable in some cases. A more detailed comparison between websocket and SSE is available in Websocket vs SSE.
For the second problem, one naive approach is to write all bids into DB and let the Bid Update Service to poll the DB to see if there are new bids. This approach works if there is not much traffic, but is less efficient in our scale and would put too much pressure on DB (# of auction x 60 / # of granularity QPS from a single Bid Update Service). Here we would leverage a hierarchy fan-out mechanism to route the bids.
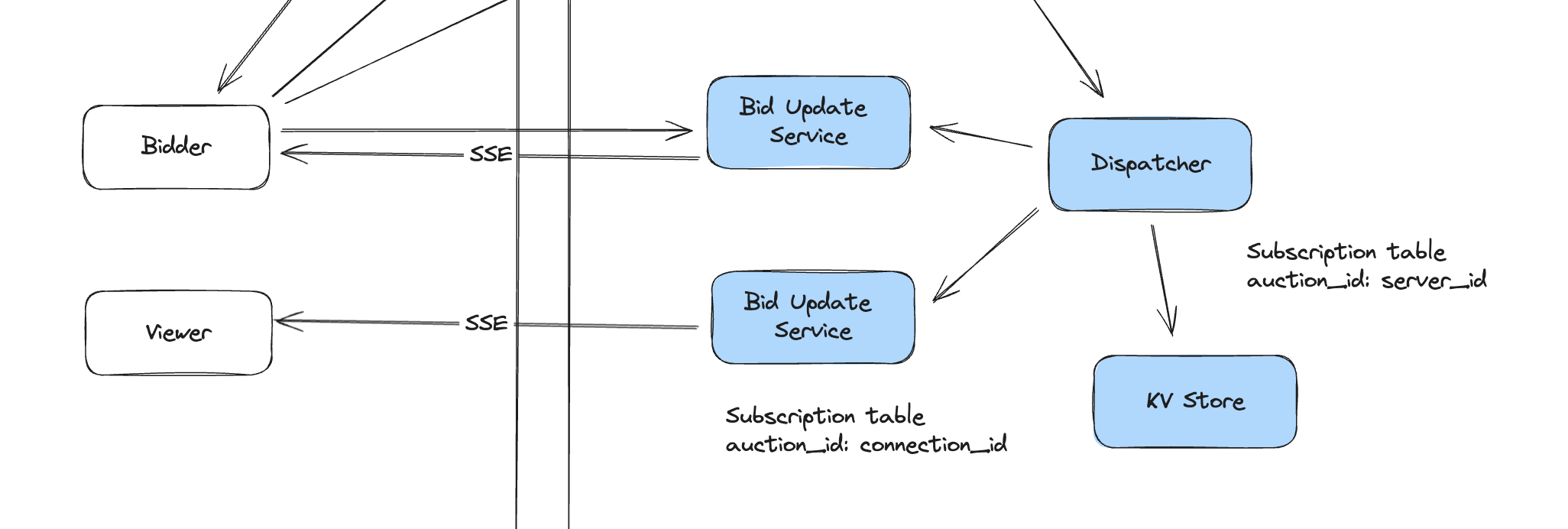
When user first navigate to an auction page, we would retrieve the information about the auction through Auction Service via regular HTTP request. If the auction is still in ACTIVE status, user would build a SSE connection with one Bid Update Service (Load Balancer could randomly pick one). The Bid Update Service bus1 would update its in-memory subscription table to record that a user u1 is viewing auction a1. Also, this server would also make a request to Dispatcher specifying that itself is listening to a1 and Dispatcher would also update its in-memory subscription table.
1
2
3
4
5
6
7
8
9
# bus1 subscription table
{
'a1': ['u1', 'u2'],
}
# dispatcher subscription table
{
'a1': ['bus1'],
'a2': ['bus2'],
}
When user make a bid, client would send a HTTP request to Auction Service, the node that handle the request would also make a request towards Dispatcher. The Dispatcher would check its internal subscription table to figure out which Bid Update Service (in this case bus1) needs this update. Once bus1 receives the request, it would also check its internal subscription table to figure out which connected user it needs to send this update.
In the version we just described, Dispatcher is a stateful service because it needs to maintain the subscription table. If it is down, we won’t able to forward bid update anymore and thus making it highly available is critical to our system. The following options could be considered:
- Adopt write ahead log and snapshot to rebuild the state after failure
- Replicate the state to external storage (e.g. KV store) so that other nodes could pick it up
- Active standby node to be promoted to primary once original one fails
Another consideration here is that we might be able to remove dispatcher, and just use coordination service or a distributed kv store to maintain the subscription table. Bid Update Service would directly make update to coordination service, and Auction Service directly query it to figure out the Bid Update Service it needs to send update to.
There are pros and cons of both approach
- Dispatcher
- pros: simplify Auction Service’s responsibility (SRP), could scale individually, handoff on retry
- cons: slightly more complex overall architecture
- Without Dispatcher
- pros: simpler architecture, less maintenance cost
- cons: Auction Service needs to handle forwarding and retry
If we would like to achieve higher consistency, such as each update needs to be sent to all users that is within the same auction. We could enable ACK among the services. For example, if certain Bid Update Service does not reply ACK to Dispatcher, Dispatcher would retry the request. It is possible that on the client side we receive duplicated events, but it is pretty simple to dedup as we only need to keep the highest bid.
It is still possible that certain bid update is lost during the transmission and it might not a big duel. The reason is that:
- During normal active auction, there would always new bids coming out, which overwrite the pervious one; so certain data loss on client side would not make a big issue.
- The only critical one is the miss of highest bid, which would be the last bid on the current auction. We could set a timer on the client side, and if it has been 10mins since we receive last update on bid, we could issue a hard pull to Auction Service to get the latest bid information.
Having discussed about how bids are routed to other users, let’s take a look how we maintain the current highest bid. When user make a bid, one instance of Auction Service is going to handle the request. It first check if the auction exists in cache or not, and see if the status of the auction is still ACTIVE status. If there is a cache miss, it reads Auction DB to check the status of the auction (this could happen but should be some corner case). If auction is still ACTIVE, then Auction Service write the bid into the bid table in append pattern, which is great for write throughput. This choice would result in multiple bids for a single user given an auction, and we would use the latest one as user’s final bid (latest could be determined by insertion time, or we could have client side request id which would be more robust). Once DB write is done and if the new bid is higher than the current one in cache, we would also update the information in cache and Auction Service would also send request to Dispatcher to deliver this new update to all clients.
It is possible that the DB write is failed or the cache update is failed. We would retry the request if is some transitional issue.
In the cache, we would store the following metadata
auction_id: (status, highest_bid, highest_bidder_id, updated_at, expire_at)status, highest_bid and highest_bidder_id is relative straightforward. updated_at is used to record the staleness of the cached entry, expire_at is used as timer to trigger the auction execution (see Auction Bid Execution). This state works because in our FR we assume that the same user could only modify his bidder to higher price instead of lower. If we allow user to bid lower, then we need to store all user’s bid or top 100 bid.
Since we cache auction state by auction_id, we could suffer from hotspot issue. For example, Wing Gundam Zero is so popular that everyone tries to bid it and we have lots of concurrent update to the cache. Below are some options that we could consider
- To deal with high volume of concurrent write request, we could use lease to coordinate the update to avoid potential stale update. The downside is that the update might need to retry multiple times to succeed.
- If we choose quorum as our replication strategy, we could potentially set write commit to 1 to increase the write throughput and have customized conflict resolve (relative simple as larger-is-winner). This works because in our FR we assume that the same user could only place higher bid but not lower.
Auction Bid Execution
To execute the winner’s bid after 1 hour, we have a Fulfillment Service. This service is similar to a cron job scheduler that it periodically scan the state we have in cache and see if there is any bid that needs to be executed by checking the status and expire_at. Once it identify one bid that needs to be executed, it would also send a request to Auction DB to double check if this is indeed the winner bid we need to execute:
- If not, it would make a write to cache to correct the information in cache. This is similar to read repair in quorum replication.
- If confirmed, then Fulfillment Service would update the status of the auction to be
PAYMENT_PENDINGin both DB and cache. Theexpired_atfield inauction_tablewould be set based on the policy (e.g. 10mins in our case). Thewinner_id,winner_bid_id,winner_pricewould also be populated all together. And then send request to notification system to send a payment notification to the winner. This event update would also be sent via the Dispatcher to all live users in this auction.
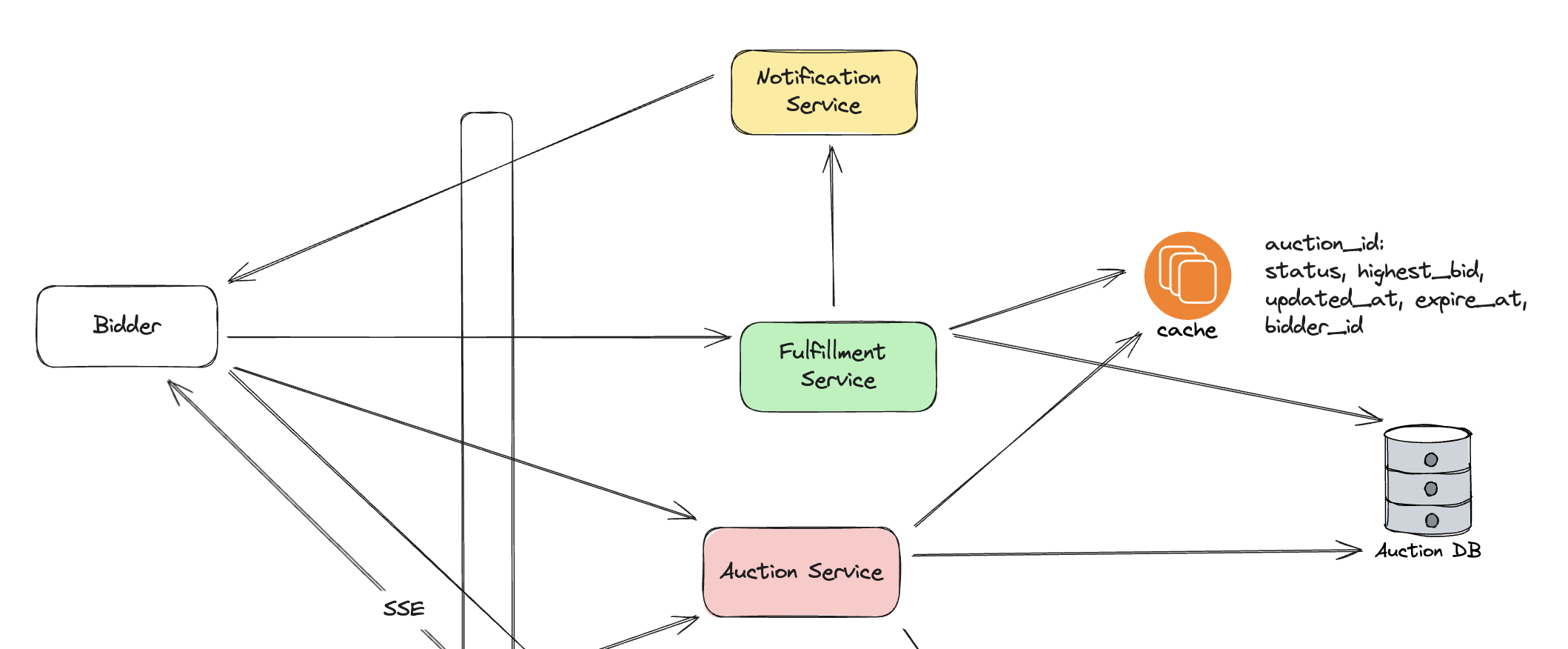
The actual payment would be handled by another dedicated system which we won’t discuss too much in details. But once the payment is done, the payment service would update the auction status to SUCCEED.
The Fulfillment Service would also periodically check the auction that is in PAYMENT_PENDING status and see if there is any auction that exceeds the deadline but still not SUCCEED yet, and move them to FAILED status.
Notice that in our design, the Fulfillment Service depends on the cache to trigger the bid execution. This requires us to have cache to be highly available (through strategy such as different replication mechanism). Another option is to directly have the Fulfillment Service to query the Auction DB where our ground truth data exists. It needs to perform a relative complex query to join auction_table with bid_table to find the wining bid of each ACTIVE auction and check if they need to be executed or not. This is one tradeoff we need to consider:
- use cache, pros is reduced latency, cons is potential inconsistency issue which cause missed execution
- directly read db, pros is accurate and no missed execution, cons is high latency and more pressure on DB
Final Stateless Architecture
In the final design, we also introduce a Reconcile Service which help us to detect certain abnormal situation. For example, the payment has succeed but the auction status is not correctly updated.
Stateful Choice
The discussion above is mainly on the stateless design. In this section, we discuss a little bit about the stateful design and see how it would be different from the stateless one.
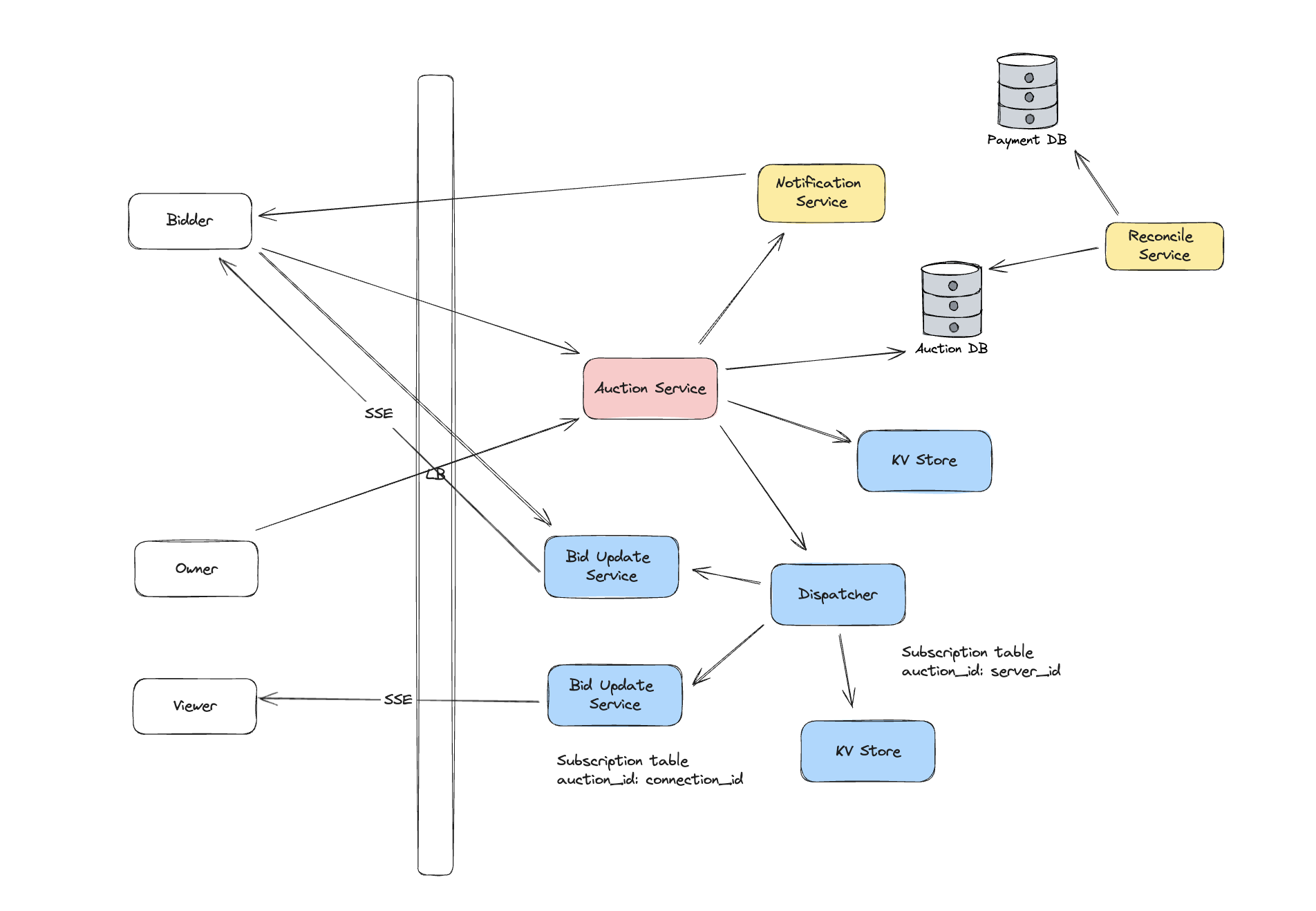
We would make Auction Service stateful, which means that it would maintain all bid related data for an auction. Once owner create an auction, it would be randomly assigned to a Auction Service and all bid for this auction would be handled through this instance. To minimize the latency, we could make the state maintained in memory. But similar to Dispatcher, we still need to make it highly available. WAL + snapshot or rebuilding from Auction DB are available options.
If user make a bid, we would leverage the load balancer to route this request to the right Auction Service instance to handle it (service discover). We don’t need another cron job scheduler to check if there is any bid needs to be executed, all these information is already available within the instance and it could handle that correctly.
We could take a simple comparison between stateful and stateless
| stateful | stateless | |
|---|---|---|
| consistency | easier to achieve high consistency as all data related to an auction is handled by a single server, for example we don’t need a separate fulfillment service to check if there is a bid to be executed | more challenging because there could be concurrent data write on the same auction handled by different servers |
| availability | more challenging to achieve as we need to replicate the stateful data | easier to handle as the server is stateless and all state data is handled by external storage |
| scalability | more challenging to scale, especially hotspot | easier to scale as we could add more machines and evenly balance the traffic |
Additional Discussion
In this section, we discuss about several additional points about the design.
High Availability
During the high level design discussion, we have touched a little bit about how to achieve high availability in each component. In this section, we summarize the key points and add some additional ones.
- Auction Service
- in the stateless design, there is not much concern here, if the node is down before response back to client, the client would just retry and another node would help server the request. There might be duplicated write/update but it is fine in our case
- the auction creation could use upsert and check if there is the same
user_idanditem_idcombination within a time rage for dedup - the bid is designed to be in appends and only the last one (by request id or injection time) would be used as the user’s final bid
- the update to cache is fine regarding duplicated ones
- the auction creation could use upsert and check if there is the same
- in the stateful design, we need to replicate the service state, by having follower node or snapshot the state to external storage
- in the stateless design, there is not much concern here, if the node is down before response back to client, the client would just retry and another node would help server the request. There might be duplicated write/update but it is fine in our case
- Dispatcher: this is also a stateful service and the strategy is similar to the stateful Auction Service
- Cache, Auction DB, KV Store: different replication strategy could be discussed here, such as single leader, multi leader and quorum based. If you are not familiar with these concepts, please refer to the video below learn more details
- Bid Update Service: even though these service are also stateful because they need to maintain the connection with client, we don’t need to replicate them nor persistent the information similar to other stateful service. The reason is that: 1. this stateful information is coupled with the liveness of this service, if the node is down, the connection has to be rebuild with other nodes; 2. the stateful information is not shareable with other nodes
- Fulfillment Service: this is also stateless and we could have a active standby to take the work once the primary one is done
High Scalability
We didn’t talk too much about how the system could scale.
- Auction Service
- in the stateless design, it is pretty easy to scale as we could add more nodes to improve the request that we could handle
- in the stateful design, we could scale it via sharding by
owner_id; sharding byauction_idis an option if we have a separate id generator to assign it upon the creation request
- Dispatcher: the size of the
subscription_tableis manageable (# of bid update server x 100k x 8 bytes ~ GB level), thus a single sever should be sufficient; however, the size of data is only one dimension we need to consider when scale the system, the QPS would also be a factor that we need to consider. For Dispatcher, it needs to deal with pretty high volume of request, thus we could add read replica to improve the throughput (sync replication for stronger consistency or async for eventual consistency), or we could also shard it byauction_id - Cache, Auction DB, KV Store: different sharding strategy could be discussed here, such as partition by
auction_id(which offers good co-locate property for theauction_tableandbid_tablebut has the downside of hotspot); or partition byuser_id(which might better distribute the write as is it relative rare for someone that becomes a hotspot and they could be rate limited) - Bid Update Service: it is also easy to scale by adding more nodes because they only keep in-memory
subscription_table - Fulfillment Service: we could shard it by
auction_idto evenly distribute the processing to more nodes
Cache and Auction DB consistency
In our stateless design, we store all data into Auction DB, and also store highest bid related information for each auction in a cache. We adopted something similar to write through, in which we write DB first and then update the cache; another option to consider is write back, in which we update cache first, and then at sometime later right back to DB. Write back could be used if we decided to in real time update the winning bid into the auction_table to reduce the volume of write request.
It is possible that we write to DB success but failed to update cache. For example, the request to update cache is failed or the node is down before try to update the cache. Retry could be used here, but it could still possible that the update to cache is failed after several retry. But since our Fulfillment Service reads the cache to execute the bid, it might read some outdated data because of the above potential failure. That is also why we have updated_at field to track if we should read from DB again to see if the data is up-to-date. Also upon serving request from client on pulling highest bid, we leverage updated_at to do a read repair to fix the potential out of date.
Websocket and SSE
Websocket and SSE are 2 common way we build a connection with backend and keep it live to send/receive data; instead of repeatedly creating new request and sent it over. Below is a simple comparison of these 2 approach
| Websocket | SSE | |
|---|---|---|
| communication | bi-direction | single direction |
| support | most modern browser already supported | limited browser support |
| failure | could not reconnect and need to establish a new one | could reconnect |
| data type | support both text and binary data | text data only |
| application | realtime messaging, online gaming | stock monitor, live comment |
In our current design, we are establish a new SSE whenever user navigate to a new auction. Another design choice here is to let user establish a new connection upon login to our application. And keep a websocket connection. Whenever user navigate to another auction, it would send this event over the websocket so that the Bid Update Service could update the subscription table. Depends on the pattern of how general users are interacting with our system, we could optimize the choice of the connection mechanism.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Reference
- Streaming a Million Likes/Second: Real-Time Interactions on Live Video
- How we designed Dropbox ATF: an async task framework
- Design Data-Intensive Applications
- Scaling Stateful Service
- Difference between Websockets and Server Sent Events
- Scaling Memcache at Facebook
- Stream Processing with Apache Flink
- DDIA Chapter 6 Partition
Acknowledgement
Thanks Rita and Celia for the great discussion and lots of idea.
Comments powered by Disqus.