How to Design Webhook
Today, let’s discuss about how to design a system that could let customer to register webhook and send webhook requests to destination.
Let’s first align on some terms that we are going to use across this post:
- webhook provider: the platform that let customer to register webhook and send the webhook request
- webhook customer: they provide the endpoint they would like the provider to send the webhook request to
What is Webhook
For readers that are not familiar with Webhook, it is a type of notification mechanism that communicates in one direction. This is a technique widely used in SaaS platform (e.g. Shopify, Strip, Slack) for external applications to receive data when some events they interested in happened on these platform.
For example, codingmonkey.com is a website that I’m running (hosted on AWS maybe), and I have a shop on Shopify that sells awesome keyboards. I could register a Webhook on Shopify so that whenever there are some Shopify users purchase awesome keyboards, a purchase event would be sent to an endpoint that is hosting on my server to process (e.g. store it in database, issue an invoice to purchaser, or send a thank you email).
Sounds similar? Yeah, it sounds pretty like a notification system. The difference here is that customer need to register webhook to express which event they would like to listen to and which endpoint URL the data need to be send to. There are also some other difference, such as we need to know if the webhook request is successfully received by codingmonkey.com or not, and additional security check to protect the data we are sending. Excited to learn more? Let’s dive deep and see how we could build such a system.
Functional Requirement
I didn’t find very crystal requirements on this, the following is some FR I summarized from the industrial examples
- Customer could register webhook and they could register multiple webhook
- Support retry of webhook and minimize lost webhook as much as possible
- Provide observability to customers
Non Functional Requirements
- 1B events pre day, which is equivalent to 10k qps for webhook trigger and request sending
- High availability
- The design should scale
- Security
Some questions to clarify
- Do we allow event loss?
- No, we should avoid event loss as much as possible.
- What delivery semantic do we provide? At least once, at most once or exactly once?
- At least once
- If we resend webhook, could we resume the endpoint to be idempotent?
- Yes, but we need to provide necessary info to achieve that
High Level Design
I would skip the API design and the back envelop estimation for the sake of sanction of this post. We would start simple to first meet the functional requirements, and then improve the availability, scalability of our system.
Webhook Registration
We need to be able to let user to register webhook in our system. Below is a simple design of this part
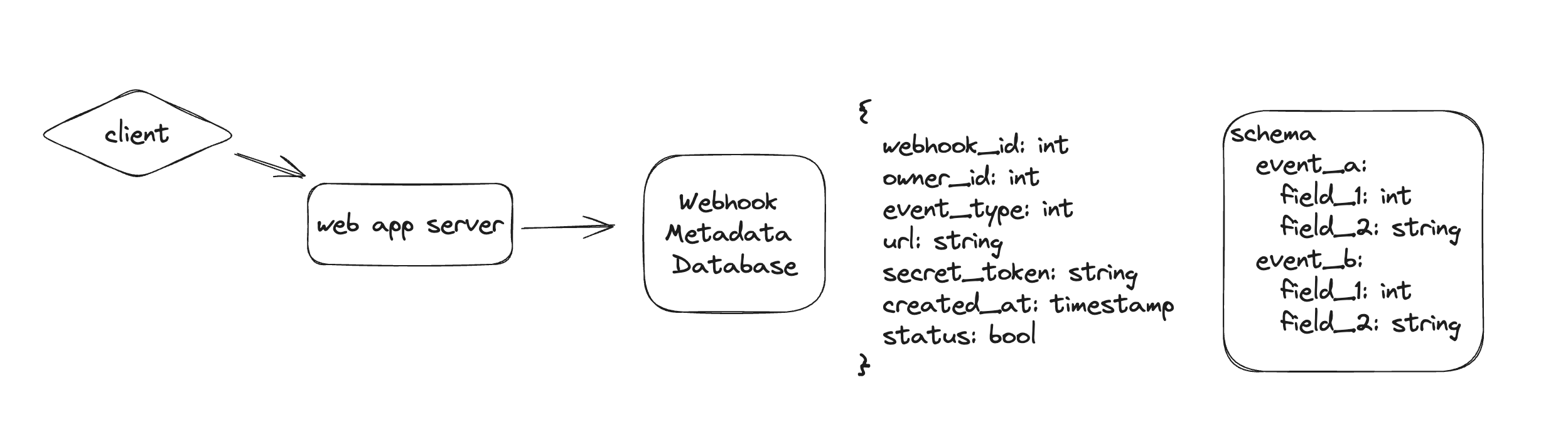
The design is pretty simple, which we have web server to handle request from client and store the information in the webhook metadata database. This metadata database is going to be used by the webhook delivery flow to figure out where to send the webhook request to.
For each webhook, we would generate a unique webhook_id as the unique identifier of each webhook. Besides that, we also need to store the event_type that this webhook listen to, as well as the owner_id. The event_type is a list of per-defined events that are available on our platform, which could be revealed via API document provided to customer. Besides that, we also need to store the url and secret_token in the database, to know where we should send the request to, as well as sending the request safely. The secret_token could be used for authentication and encryption for sending the webhook requests. In this schema, customers could register multiple webhook within the system.
One challenge here is that how to verify that customers have ownership on the urls they have provided. One common solution here is to send a test event to the endpoint they are providing, and ask them to verify they have received it; or by including a “challenge” in the request that the endpoints need to echo back (e.g. Dropbox webhook).
Webhook Delivery
Next, let’s take a look at the webhook request deliver flow, which is the meaty part of the entire system. As mentioned earlier, the entire system is similar to notification system, and thus I use notification system as a template for this design. Below is a high level design of this flow
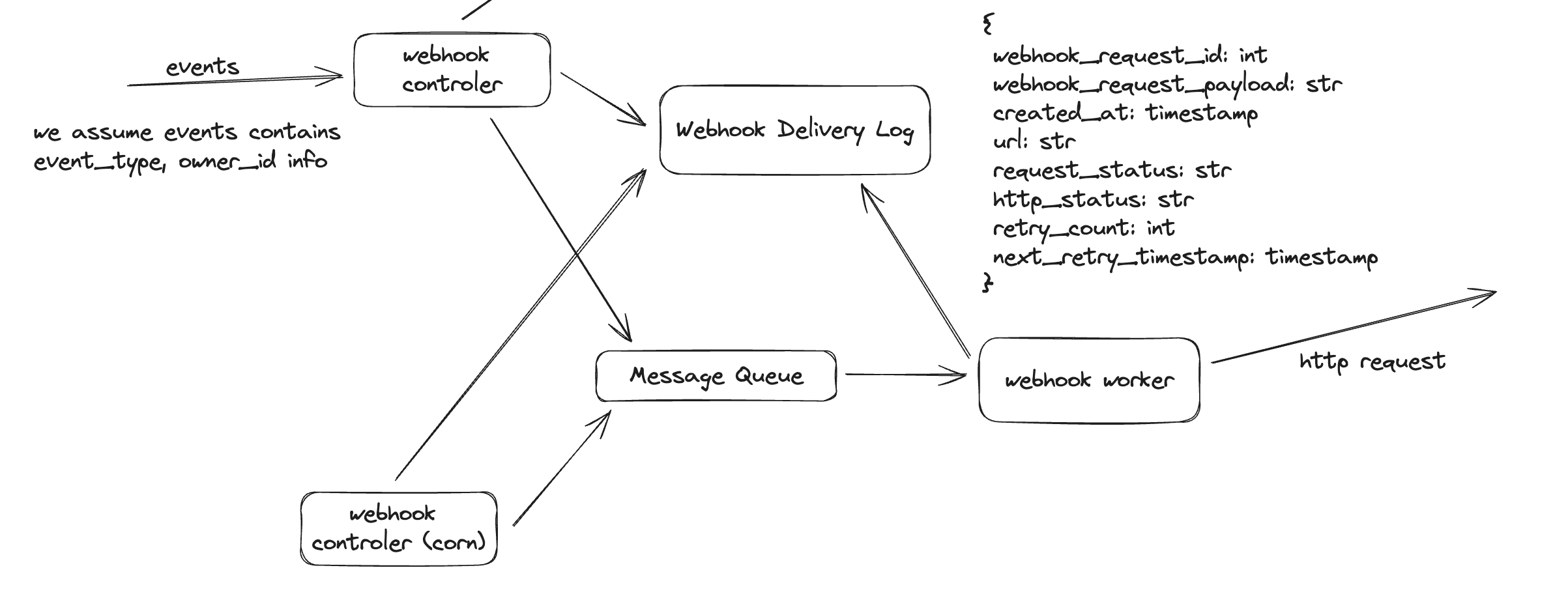
In this design, we adopted a single responsibility strategy and separate the delivery logic into several components
- Webhook Controller is responsible for processing the events (that are generated on our platform) and figuring out which endpoint we should send the data, as well as constructing the payload of the request. Here we assume that the events generated from our platform contains the
event_typeandowner_idinformation (because we don’t want the event that happened in our shop to be delivered to others’ endpoints). Withevent_typeandowner_id, controller could retrieve the record from the metadata database and construct a webhook request task. Once the task is constructed, controller would write an entry into Webhook Delivery Log database to persistent this information, and set therequest_statustoPENDING, which we could leverage later for different retry strategy. - Message Queue is adopted to store the webhook request task, which worker would consume. Using message queue bring the following benefits, which outperform the additional complexity they bring:
- controller don’t need to wait for the current webhook request to be delivered to process the next one (it is async okay). This not only saves resource, but also increases robustness (e.g. if worker failed, controller could still make progress and put job onto the queue instead of being blocked).
- if there is a burst of events come in, message queue could help buffer the increased volume of task so that worker won’t be throttling.
- Webhook Worker is responsible for consume webhook request task from the queue, and send the actual HTTP POST request to the endpoint. The payload of the HTTP POST request could be something like this
1
2
3
4
5
6
7
8
9
10
{
"id": str
"event_type": str
"created": int,
"data": {
"field_1": value_1,
"field_2": value_2,
...
}
}
Worker would need to wait for the response from the endpoints, to know if the request has been successfully received. If received, then worker could update the record’s request_status in the Webhook Delivery Log database to SUCCEED; otherwise, different strategy of retry could be adopted to resent the webhook request. Supporting retry also means that we are providing at least once semantic, which could result in duplicated request sent to endpoints. We expect these endpoints need to be idempotent, which is doable with the id sent along with the HTTP POST request.
Webhook Retry Strategy
One critical consideration for webhook system is the retry mechanism in case HTTP POST returns 4xx or 5xx code, or timeout. There are different retry strategies:
- Retry immediately upon failure within a time range repeatedly, or until max retry limit
- Exponential backoff within a time range (e.g. 24hrs), or until max retry limit
For example, Strip would attempts to delivery webhook up to 3 days with an exponential backoff. Option 1 is easy to implement, but the issue is that: if endpoint is returning error code, then it might take some time to mitigate the issue; immediate retry is likely to hit the same error, try again later time would be a better option.
In order to achieve exponential backoff retry mechanism, we would use a cron version Webhook Controller, which dose not consume the events from upstream, but scan the Webhook Delivery Log database to identify the webhook requests that are still in PENDING status and have not exceed the max retry. For each of such request, the controller would bump their retry_count or retry_timestamp, and publish a new task into message queue.
The addition of this cron version Webhook Controller could also help mitigate worker failure issue. For example, if one webhook http request is consumed and removed from the message queue by a worker, but suddenly the worker failed; since the task is already removed from the queue, other worker won’t able to get it and process it again. However, the cron controller would notice in from the log that there is one PENDING request and schedule it to retry.
Another option is that if message queue provide the capability to persistent messages, worker could commit the position of the message in the queue they have processed, and if worker failed, it could resume from its last committed position and process the message again
If for some endpoints, the failure is consistent for a certain time and over the threshold, we could temporarily mark the endpoints as disabled in the metadata’s status field to prevent new events from further deliver to them. And we could send alert email to customers to have them investigate into the issue. Once the issue is mitigated, the status could be changed back, and we could consumer the delivery log to resume the webhook request; or use other channel, such as dump the entire data that need to be delivered during this time and send it over to customer.
Observability
Since we have already log the status of each webhook request in Webhook Delivery Log database, it is easy to support the observability. This could be implemented via having web application server to send a query to the database to aggregate the data and render it as a dashboard for customers. They could know how many webhook request have been sent, what’s the failure rate, etc.
Security
Security is especially important in webhook system. In webhook registration section, we authenticate that the endpoints belongs to users, we also need to authenticate ourself that the HTTP request is from us.
One common approach is to use HMAC to sign the request with a shared secret with the user and sent the signature along with the request(e.g. Strip uses this approach) and user could verify the signature with the shared secret. This shared secret could be auto generated upon user register webhook in our system, and show them to user in their monitor dashboard. This approach could also help us prevent replay attack, by including a timestamp used to expire webhook request.
Another approach, which is less common, is to get a token from the consumer and add it to the Authorization header for validation. For example, if the owner of the endpoint has authorization server, then before sending webhook request, we could first obtain a JWT token and store it within our metadata table secret_token and use it each time we need to send webhook request.
Besides the authentication problem, we also need to prevent the data we are sending could be read by others. There are also several options with different trade off:
- Avoid send sensitive information in the webhook payload. Instead, we could only send some entity id which is totally meaningless and ask customer to pull data again via other API. Pros is that this is the most safe approach, and the cons is that customer experience is worst
- Another option is to encrypt the data with a shared secret key, which is only known between webhook provider and webhook consumer. A follow up of this question is how could we share this secret key safely between customer and provider over the unsafe network? Here we could use RSA encryption. (This is a general practice, RSA is safe, since only yourself know the private key; but the amount of data could be transferred via RSA is limited. So it makes since to use RSA to send another secret key, which is used for encryption/decryption of large volume of data)
- Sending data with HTTPS and certificate pinning is also an option to safely transfer sensitive data, but this would have some performance hurt and require customer to have HTTPS setup such as CA
High Availability
Let’s see if there is any single point of failure in our current design. What comes to us first is the database and message queue. There are multiple replication strategy here we could use, each comes with different trade off:
- For Webhook Metadata Database, we could adopt single leader strategy, and have 2 followers. The followers could use synchronized replication, which provides good consistency, but the write throughput on the leader would be low; while if we use async approach, leader could handle more write request while could lead to consistency issues among leader and followers. If we are building for a geo webhook system, we might also consider multi-leader strategy, with better write request severing based on location and annoy of write conflict.
- For Webhook Delivery Log Database, besides the aforementioned strategy, we could also consider the quorum based replication, which provides the best write throughput and eventual consistency is acceptable in this case. (Q: what would be the worst case here).
- For Message Queue, similar to the database, we could also have replica setup so that the message is written to multiple node instead of single one. Also, even if we only have a single node queue and it failed. Since we are storing all scheduled webhook request in the Webhook Delivery Log Database, the webhook controller (corn) would identify the abnormal ones and try to reschedule them.
For other components such as web app server, webhook controller and webhook worker, they could be stateless. If a node fails, there would be other nodes available to continue the work.
Scalability
For scalability, we could horizontally scale web app server, webhook controller and webhook worker by adding more nodes into the cluster. For database, we could shard it to scale if the total volume of data is too large to fit onto a single machine. Message queue could also be horizontally sharded by increase the number of partitions.
There could be hotspot. For example, my awesome keyboard is so popular that lots of customer is visiting my shop and vast amount of events are triggered. To handle the hotspot, we could use a dynamic config to redirect the traffic of hotspot to specific cluster of machines, instead of starving the quote with other customers; or we could further shard the hotspot by some approach such suffix with numbers.
Other optimization
There are couple of other optimizations we could add to our system to make it more robust
- we could have load balances in front of webhook controller to route based on machine utilization; also we could integrate the rate limit here to prevent abuse of the system (such as bot triggered events)
- we could add a layer of cache to reduce the amount of read to metadata
- we could add a rate limiter to help control the http request we send to customers; for some customers that have high security requirement, they might only trust http request sent from specific IPs, we could have dedicated VPC to support that needs
- for observability, we could add some pre-compute mechanism to reduce the volume of data that the query need to scan; for example T-1 snapshot + on demand query on T
Here is our final design 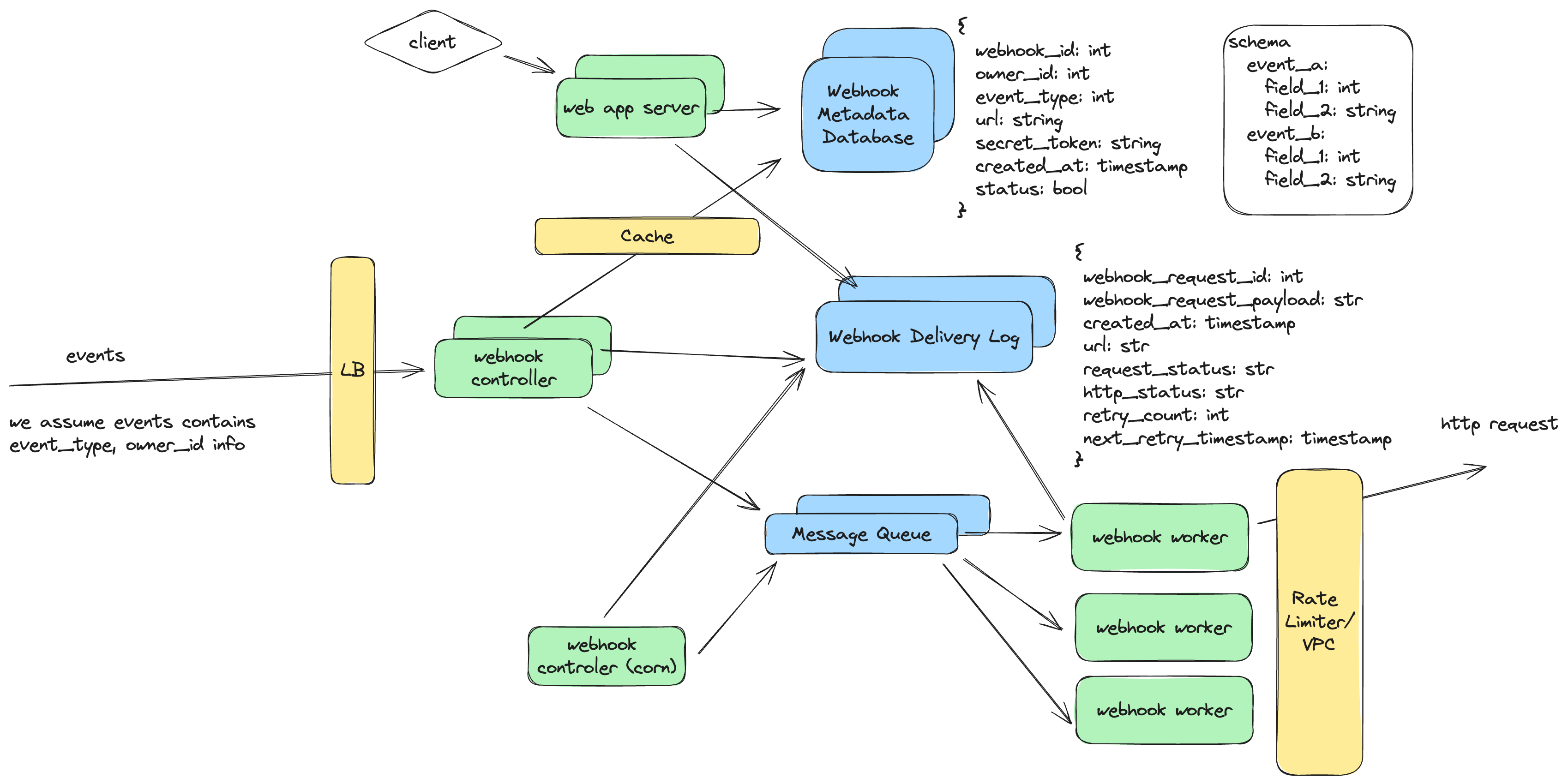
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.