How Workflow Get Scheduled via Plugins in Flyte
Reading open source code has been a recommended approach for software engineers to learn. However, in my past 8 years career, I didn’t do a good job on that. After working in a startup for 1 year, I accidentally foster the habit to read open source code XD. In this post, I would like to share one open source project I have been learning recently, and hope you would enjoy this journey as well.
I have been working in ML pipelining for a long time in Meta Ads. However, I didn’t have a comprehensive understanding across the entire stack, especially on how the underlying infra schedule the model training job and execute it over a fleet of machines. Recently, I have been exposed to an open source project: Flyte, which is a orchestrator for ML pipeline built on top of Kubernetes. I think this might be a good opportunity for me to gain some deep understanding in this area.
I have always been a believer of “Learning by Doing”. My ultimate goal on learning this open source code is to implement a simplified version of ML pipeline orchestrator on my own. Next, let’s see what problem we are going to discuss in this post.
Problem
In Flyte, we could use something called Plugin for distributed training, e.g. PyTorch Plugin. In this post, we would discuss how these plugins are getting invoked, so that the distributed training job we defined could get executed. In this post, I would simplify the discussion and only laser eye on the main flow, for other important topics such as storage, pipeline definition and compilation, availability and scalability, I plan to defer it to later posts.
High level architecture
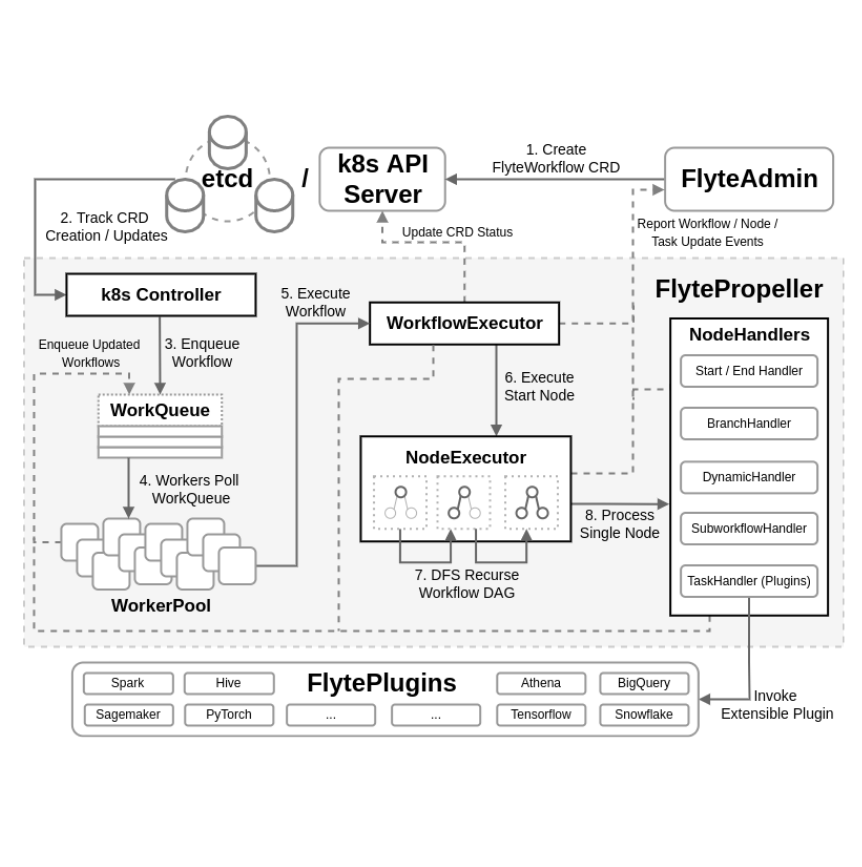
The key component that is responsible for scheduling and monitoring the workflow in Flyte is called FlytePropeller. It tries to push FlyteWorkflow, which is defined as a Custom Resource Definition in k8s, to the desired state leveraging k8s reconcile mechanism. The official document of Flyte has provided a pretty good high level architecture on FlytePropeller’s design, here is a list of the core components:
- Controller: overall brain of
FlytePropeller - WorkQueue/WorkerPoll: where worker lives and take jobs to do, a very classic design in job scheduling system
- WorkflowExecutor: responsible for high-level workflow operations, such as tracking the status of workflow
- NodeExecutor: responsible for process the node within the workflow and decide the action need to take
- NodeHandler: different type of handler to execute different type of node in the workflow, e.g. TaskHandler for execute
Pluginsand WorkflowHandler to execute embedded sub-workflows
Knowing what to do is one thing, and knowing how to do is another thing! Next, let’s jump into the code and see how these components are working internally and see how the logic defined within Plugin could be invoked.
Components Deep Dive
Controller
Let’s get our journey starts with the controller. Controller is the starter for FlytePropeller, it is responsible for initializing other components:
- In the
Newfunction ofcontroller, we would createworkqueuehere. - And then, we would create
workerpoolhere. Note thatworkerpoolrequires theworkqueuewe have created before as part of its initialization (because worker needs to consume the jobs from the queue), and onePropellerHandler- notably, the
PropellerHandleris initialized withWorkflowExecutorand theWorkflowExecutoris composed ofNodeExecutor NodeExecutorrequires anodeHandlerFactoryas part of the construction
- notably, the
As of now, all the key components we have mentioned in the high level architecture is ready. We would go deeper into them to understand how are they getting invoked.
Besides the New function, there is also a run function which plays a critical role on launching the controller. It launches things such as the workerpool, gc and metrics monitors. run function is called within another function Run, in Run, one interesting part is that it is going to leverage the leader election functionality provided by k8s and only let leader to trigger run function. We would discuss this topic more in details in a future post.
As the controller would launch workerpool, let’s then move our view to workerpool and workqueue to understand how these 2 components work.
WorkerPool/WorkQueue
The workerpool essentially is composed of workqueue and several workers, each are actually goroutines (this is also why Flyte could be pretty scalable on a single CPU, we would discuss this in the future). The Run function in workerpool is the most critical function, which is the one get invoked by controller. The main logic is the for loop here, where we launch multiple goroutines and each goroutine would make a call to runWorker function. The runWorker function is relatively simple, just an endless while loop to call processNextWorkItem function. processNextWorkItem function gets an item from the workqueue and then invokes the PropellerHandler we perviously passed in during initialization. As we could see, the key processing logic resides within PropellerHandler’s Handle function, which is defined as part of the interface here, then let’s move on and see how this Handle works.
PropellerHandler
The Handle function defined by the Propeller struct is the entry point of the reconcile process (Here Propeller has implemented the Handle interface, thus it could be considered as type Handler although there is no explicit inherit, this is how interface implementation works in Golang). The key logic is within this for loop, where we call streak function up to a max trial. The streak function would try to do a single mutation to workflow, and return the mutated workflow upon succeed, otherwise no update made if failed. The workflow here is the CRD FlyteWorkflow and the mutation operation is done via TryMutateWorkflow. TryMutateWorkflow makes calls to workflowExecutor’s HandleFlyteWorkflow function to see if we could reconcile the workflow towards it desired status. We left out other details, such as how to handle failure, how to handle aborted workflow etc. From the code in PropellerHandler, we could observer that the Handler is just doing some high-level logic and the actual workflow processing logic is delegated to workflowExecutor. Now, let’s move to workflowExecutor.
WorkflowExecutor
The HandleFlyteWorkflow function called within PropellerHandler is a router function. It invokes other actual logic function based on the status of the workflow. For example, if the workflow status is in WorkflowPhaseRunning, then it would invoke handleRunningWorkflow function. In these functions, a common pattern is that they would setup the context, invoke nodeExecutor’s RecursiveNodeHandler function to get the new status and then update the status. The new status is passed back and used to transit the workflow’s status (which is the reconcile process). Notice that the FlyteWorkflow is passed as parameters for executors.DAGStructure and executors.NodeLookup, as well as the startNode.
There is some different operation based on the new status RecursiveNodeHandler passed back. For example, if the new status is partial completed, then the workflow would be enqueue again and return running status.
The WorkflowExecutor handles the operation of workflow and decided what action to take. In ML pipeline, we know that workflow is usually composed by several nodes, and these nodes encapsulate the actual computation. Let’s take a look at nodeExecutor, which is responsible for handling this part.
NodeExecutor
The RecursiveNodeHandler function is one of the most important function in NodeExecutor. It is the entry point to execute a node within a workflow. It uses actor model and modified version of DFS to traverse the DAG and to execute non-blocked nodes. Based on different status queried based on the starter node passed from input, it applies different logic to proceed. For example, if the node status is already succeed, skipped or recovered, then it would invoke handleDownstream function; while if the node is in status that could be handled, then the key logic happens here: first, based on the node’s kind, a dedicated handler is retrieved from nodeHandlerFactory; then HandleNode function would be invoked to execute the node.
The handleDownstream is where the aforementioned modified DFS implemented. The logic is relatively straightforward: starting from the input node, we retrieve all downstream nodes; then we iterate each node and invoke the RecursiveNodeHandler function on each of them, with self as the new input start node; keep the status to check if all downstream nodes have been processed, and return the status accordingly.
The HandleNode function of nodeExecutor is also a router function, where different processing function is invoked based on the status of the current node. The most important functions are handleQueuedOrRunningNode and handleNotYetStartedNode:
- In the
handleNotYetStartedNode, the most critic logic is the call topreExecute, where we check if the node could be queued to be further processed. The checking logic is relative simple, where we check the upstream nodes are all in succeed status or not - In the
handleQueuedOrRunningNode, we would first try to check if there are cached result given the current handler, and trigger theexecutefunction if there is no cache hit. The core part of theexecutefunction is to trigger theHandlefunction of the inputNodeHandler, which is obtained fromRecursiveNodeHandlerand passed along the stack here, what a long journey!
Now, we have hit the most underground part of FlytePropeller’s architecture. Next, we need to dive into NodeHandler to understand how the Handle function is implemented (here we would focus on how the handler used to fulfill the operations we need in distributed training).
NodeHandler
From the section above, we know that we retrieve node handler from nodeHandlerFactory in RecursiveNodeHandler, through the GetHandler function. Here is a step by step explanation on how we trigger the logic defined within plugins:
- The
GetHandlerfunction returns node handler based on the type of the node. Most of training job is defined via@task, which is ofTasktype in Flyte - Here is the setup of the node handler for
Tasktype. In Flyte, allTaskis treated as adynamicnode and handle throughdynamicnode handler. However, we would still pass atasknode handler intodynamicnode handler - In
dynamicnode handler’sHandlefunction, by default, we would make a call tohandleParentNode, and in this function, we would make a call toTaskNodeHandlerinterface’sHandlefunction - The logic of
tasknode handler’sHandlefunction is pretty complex. First, it tries to find thePluginbased ontasktype; then if there is no cache hit on result, it would invoke plugin- Within
invokePluginfunction, the core part is to invoke theHandlefunction ResolvePluginsearch plugins throughpluginsForType, where we initialized within theSetupfunction; the initialization is essentially sweeping theenabledPlugins, and we get it fromWranglePluginsAndGenerateFinalList
- Within
- In
WranglePluginsAndGenerateFinalListfunction, we get all plugins related to k8s throughPluginRegistryIfaceinterface; intasknode handler, there is a data memberpluginRegistryof this type, and the construction is here, where we call thePluginRegistryfunction frompluginMachinerymodule - For each k8s plugin, they would be wrapped within a
PluginEntry, which is further wrapped in an object calledNewPluginManagerWithBackOff - All k8s plugin would use the
RegisterK8sPluginfunction within the modulepluginmachinery.registerto register them into the system. For example, the Pytorch Plugin is registered here. However, all of these plugins actual do not provide aHandlefunction, which should be called by the node handler. What happened? - Actually, the
Handlefunction is implemented withinPluginManager. SincePluginManagerimplement all interface defined inpluginCore.plugin, we could treatPluginManageras a plugin to invoke (this is a class Strategy design pattern, wherePluginManagerdefines the main logic and expressed via several step functions. And we could use composition to fulfill these step functions with different implementation) - Within the
Handlefunction inPluginManager, we would check the current status, if the status is not started, then we would calllaunchResource, otherwise we would callgetResourceandcheckResourcePhaseto obtain new transition information- In
launchResourcefunction, we would callBuildResourcefunction which is defined in the plugin. This function is used to construct a kubeflow job. Then it make acreaterequest viakubeClientto create this resource - In
checkResourcePhase, we would callGetTaskPhaseto get the current status of the job - Here is the point where Flyte is leveraging kubeflow and k8s to request resource and start the training job; both kubeflow and k8s would be huge topics, and I plan to discuss more in details in separate blog
- In
Here, we reach the end of our journey and the remaining job is delegated to k8s. What a complex flow!
Summary
In this post, we focus our discussion on how Flyte would invoke the distributed training job which is defined through plugin, we could see some common practice that is adopted in the design, such as utilization of queue and multithreading for scalability; separation of workflow executor and node executor for single responsibility principle; factory design for extensibility, etc.
In next topic, we would focus on the storage used in Flyte, which is also another critical component, as we need to store the status of the workflow, node and even intermediate result; as well as leveraging caching to speed up the execution by avoiding duplicated computation. Once we have a better understanding on the storage part, we could start to evaluate the availability, scalability and persistence of Flyte.
Comments powered by Disqus.