那些年,我们追过的 Feature
在今天的 blog 里面,我将结合我前一阵子面试 machine learning engineering 的经验,跟大家唠唠在 ML design 里面的 feature engineering 相关的问题。 在 ML design 里面,我们可能会被问到可以使用什么样的 feature, 以及具体一些 feature 可以被怎么处理以及怎么使用在模型之中。由于我之前主要做的是推荐和广告相关的内容,所以我在这里将主要介绍一下在设计推荐系统的时候,围绕 feature 可以聊的一些点,来给大家提供一些思路,帮大家更好的准备面试
Feature 的种类
在推荐系统里面,我们经常要处理的场景是
给定一个用户和一个物品(以及一些可能的 context),预测用户会喜欢(或者其他的 action)这个物品的概率
基于上面这个简单化的概括(我们在之后会对这个问题进行适当的展开),我们其实可以比较容易的归纳出 feature 的种类
- User Side Feature
- Item Side Feature
- User-item Interaction Feature
- Context Feature
除此之外,还有一些相对比较特殊的 feature, 我们之后会单独介绍
User Side Feature
这种类型的 feature 有时候也会被称作 request level feature, 针对推荐系统来说,一个 request 基本上就代表了一次用户请求,所以这么叫没什么毛病。在 user side feature 里面,有下面几种比较常见的形式
- Demographic feature, 也就是常说的一些基本用户属性,比如用户的年龄,性别,职业,local 等等; 这些 feature 是最最常用的 feature 了,不过由于现在针对 Machine Learning fairness 查的严,很多这种 demographic feature 被禁止用于推荐了
- User behavior feature, 也就是用户的一些行为特征,比如用户过去一个月买过的物品 id,用户过去一周 follow 别人的 account 的个数,用户的历史 CTR 等等
- 这里其实列举了三种不同的“数据类型”,也是在推荐系统中 feature 的常见形式: id feature (比如用户 like 过的 post id, 用户之前 follow 过的用户的 id 等等), count feature (比如 follow 的个数,click 的个数等等), ratio feature (比如 CTR, CVR 等等)
- 一般针对 user behavior feature, 我们都会有一个窗口来进行 aggregation (比如过去一周的 sum 或者 average; 在工程实现的时候,经常是多个窗口一起实现了,比如 7D, 14D 等,因为可以通过一个 pipeline 就全部搞出来,比较方便高效); 随着模型技术的进步,现在有很多尝试开始用 user sequential behavior modeling 来取代这种 feature engineering 的方法了, 比如 DIN 直接拿用户的 behavior 数据和 candidate item 做 attention 处理
- User 的 behavior 多种多样,这部分需要针对具体的推荐系统所解决的 business problem 来进行处理,是最需要 domain knowledge 的部分; 比如在给用户推荐其他用户来 drive growth 的推荐系统中,你用用户过去点击过的 post id 可能效果就差一些,但是如果用点击过的 post 的 author id 可能就是一个不错的选择
- User embedding, 或者叫 user profiling, 也是现在非常主流的一种 user feature, 当在面试中提到这部分的时候,基本上一个 follow up 是如何计算出来 user embedding, 以及如何在 inference 的时候进行 serving, 一般的 user embedding 的计算方法有这么几种:
- 直接用 item 本身,或者通过一些 heuristic rule 来表示: 比如说,我们可以把所有的 post 分类成 1024 个 category, 那么根据用户曾经看过的 post, 我们就可以用一个 1024 维度的向量来表示用户, 如果用户看过 GUNDAM 类型的 post, 那么 GUNDAM 类别在 1024 向量中的值就设置成 1, 否则就是 0; 这种方法其实非常类似 NLP 里面以前经常使用的 bag of words 的方法来做 sentence embedding; 这种方法的好处就是实现起来比较简单,但是缺点就在于捕捉到的信息比较粗糙,只能根据我们定义的 heuristic rule 来决定,不能根据用户跟物品的交互学习出一些 semantic 的信息(比如喜欢 GUNDAM 的用户可能对于游戏也感兴趣)
- 一个这对上面的方法提高的方法,是基于 item 的 embedding 去学习一个 user embedding, 这个方法在 Pinterest 的这篇论文中得到利用,他们基于 PinSage 出来的 item embedding, 结合用户的 sequence engagement 数据,利用一个模型来学习 user embedding
- 通过其他的一些方法来训练出 user embedding, 比如利用全体用户的 interest follow graph 作为数据,利用 collaborative filtering, dedicated model (比如 graph neural network) 来计算出 user embedding, 然后这个 embedding 可以被用作输入送进其他的模型; 比如 Facebook 就采取了用一个专门的模型来对大量的 user feature 进行学习,然后用这个 dedicated model 去生成 user embedding 然后给下游的模型使用,详情可以参考这篇论文; 这种方法的好处在于能够学习更具有表征能力的 user embedding, 但是缺点在于 user embedding 需要进行单独的额外维护,以及不能很好的基于 downstream 的 task 来进行微调;
- 将用户 id 作为一个 sparse feature 输入到模型里面,然后通过一个 embedding lookup table 来 convert 成一个 dense vector, 然后再和其他的 feature 输入 concat 在一起; 这个就是一个经典的如何在 Neural Network 里面使用 sparse feature 的方法,比如 LinkedIn 的这篇 blog; 这种方法的一个好处是在于 user embedding 和模型是一起训练的,所以 embedding 可以理解为针对某个问题的专门优化,那么代价也显而易见,一反面是模型训练的参数量上升,另一方面对于 user embedding 的 reuse 也不是那么的方便了
Item Side Feature
Item side feature 其实和 user side feature 本质上是类似的,比如我们也可以有一些 item 的属性信息,比如物品, 产地,物品价格等等,或者 item 的一些历史交互数据,比如过去一周的 impression 数量,过于一周的 CTR 等等;同时我们也可以使用和 user embedding 类似的方法来生成 item embedding 然后用作模型输入; Item side feature 的一个特点是 feature value 变化不是很频繁,因此这部分的 feature 一般都会采用一些类似 pre-compute 的方法来提高性能
- 一种常见的方法是使用双塔模型来对 user 和 item embedding 进行训练,然后 user tower 可以在线的去 server request 来实时的计算 user embedding, 但是 item tower 可以离线的把所有的 candidate 的 embedding 计算好然后缓存起来,等需要的时候直接读 pre-compute 好的而不用再实时的计算了
- 相比较 user feature, item 可能也会有一些其他形式的数据可以利用,比如物品的图片,广告语等等,这些数据都可以经过专门的处理然后用作模型输入,比如利用 pre-train model 来把 image 转换成 embedding; 或者利用 object detection 模型来 predict 图片中包含物品的种类信息; 利用 BERT 来做 sentence embedding 等等
Item side feature 比较特殊的一种 feature,是可以利用一些 Owner 的信息,而不单单是物品本身的信息: 比如说我们要推荐广告,那么我们可以拿 campaign level 或者 advertiser level 的信息(这些信息相比较 ads id 本身可能会更加的 stable, 这个是 ads 里面的一个问题,因为 ads 本身的 TTL 都相对比较短); 如果我们推荐 post, 那么我们可以拿 post owner 的一些信息,比如 post owner 过去一周看过的 post id 等,作为 additional signal 来做推荐
User-item Interaction Feature
User-item interaction feature 就是具体到 user-item pair 的 signal。 在我们上面所描述的 feature 中,都是根据 user 或者 item 进行了 aggregation; user-item pair 可以理解为是 aggregation 之前的信息,能够给我们提供最 fine-granularity 的 signal, 比如,我们可以看 user_a 跟 item_a 过去 24 小时的 view count, time spent 等等; 或者 user_a 跟广告商 advertiser_a 过去 24 个小时的 impression 的数量, CTR 等等
这一类的 feature 的 serving 是最困难的,原因就在于其 cardinality 非常的大(约等于 O(num of user) x O(num of item) 的数量级),因此我们很少在 early stage (这里其实涉及到了推荐系统里面的多层架构设计,可以理解为我们在层层做 filtering 从而来减少需要考虑的 candidate 的数量) 大量的使用这种类型的 feature
Context Feature
这种类型的 feature 相对于前三种讨论到的而言不是那么的常见,context feature 有两种不同的理解形式
- 一种是在 server 端我们能够拿到的一些 context feature,比如现在很多的推荐系统开始 adopt list ranking, 也就是考虑所推荐的物品彼此之间的影响,把彼此当做 context 来进行优化(彼此都是彼此的缺口 XD)
- 另外一种是在 server 端无法获取,只有在 device 上才能拿到的一些信息,比如用户当前的网络环境, 用户当前手机的电量等等,这些 context feature 也会对用户的行为产生影响,比如如果我的手机没什么电了,我可能会先收藏几个视频等之后再看
- 针对上面说的这两种情况,在快手的这篇论文里面都有提及,详情可以参考阅读一下原文
其他 Feature 的碎碎念
除了上面提到的 feature, 还有一些比较特殊的 feature 承担着一些特殊的使命
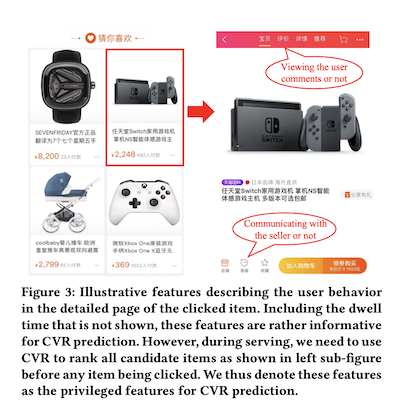
- Privileged feature, 这种类型的 feature 是属于在 training 的时候 available 但是在 serving 的时候不 available 的,一个例子是在做 CVR 的预测的时候,用户在一个物品上面的逗留时间会是非常 powerful 的一个 signal, 但是我们在给用户展示物品的时候,是需要先预测 CVR 出来对物品排序,然后再给用户展示,所以在 serving 的时候这个逗留时间是不知道的,但是在 training 的时候我们可以根据 client 端的 logging 知道这个信息。在淘宝的这篇论文中,他们采用了 teacher-student knowledge distillation 的方法来学习这类 feature
- Position feature, 这个是在推荐系统中非常常考的一个 follow up. 在推荐系统中,存在这一种系统性的 bias, 也就是 position bias: 用户点击了某个物品,可能并不是因为我们的推荐做的有多么好,而是单纯的因为这个物品被排在了前面,导致有更多的 impression 引来更多的用户 action. 传统的解决办法是把物品的 position 当做一个 feature 放在模型中跟其他的 feature 一起训练学习,从而能够让模型学习出 position bias, 从而起到一定的 calibration 的作用; 在 Youtube 的 recommend next video to watch 的论文中,position feature 被单独的加到模型的一个 tower 里面来进行专门的学习,从而提高模型针对 position bias 的解决能力
常见的 Feature 处理办法
上面的章节我们主要说了一些不同类型的 feature, 在介绍的时候我们也稍微提及了一下 feature 的不同的数据类型,这里我们再稍微复盘一下
- numeric feature, 我们也俗称 dense feature; 这里面也细分成两类,一类就是最普通的 float number, 比如 ratio/count 等等;另一类是 categorical feature, 比如性别,国别等等。这两类 feature 最主要的一个区别在于他们的 scale 是否具有意义
- id feature, 我们也俗称 spares feature; 主要就是一些
entity id, 比如post id,ads id等等;具体的表示情况也有两种,一种就是单独的一个 id list, 另外一种则是给不同的id一个 weight, 比如说我们可以根据用户跟这个 entity 交互的时间来做一个 weight decay, 从而实现一种简单的 recency 性质的 sparse feature, 让更近的 id 有更高的 weight, 一般我们管这个叫做 id score list; 所有的这种 id feature 都需要通过一个 lookup table 来转化成 dense vector - embedding feature, 一般就是其他模型输出的一些 dense vector; 一般整体直接使用,很少有只使用其中的某一些维度的情况
在这几种类型的 feature 当中, id feature 和 embedding feature 的处理办法一般都比较的统一,比如使用 lookup table 来转化 spares feature 到 dense format, 或者使用一些 clipping 来防止 embedding 里面的某些值过大; 针对 numeric feature 的处理比较常见,我们下面就主要聊一聊这些
Normalization
这个是针对 numeric feature 来说最常见的一种处理方式了,主要的目的就是让所有的 numeric feature value 的 scale 尽可能是统一的, 比如 ratio feature 的 scale 一般都是 0 ~ 1, 但是房价这个 feature 的 value 就可能 scale 在 0 ~ 10M, 这样会让 ratio feature 的 weight 跟房价 feature 的 weight 不在同一个数量级上,从而导致了 “vanish” 情况的发生。针对这种情况,一般我们可以采用 min-max scale 的方式来 normlize
另外的一种情况,是 feature 本身的 distribution 是 highly skew 的,在 ML 里面,我们都是尽可能希望 feature 的分布尽可能的接近正态分布(为什么呢)。针对这种 data skewness 的情况,我们可以采用一些 transformation 比如 log-transform 或者 cox-box transform 来进行处理,从而让 value 尽可能符合正态分布
One-hot/multi-hot Encoding
这种处理办法是 categorical feature 的一种常见处理办法。在这种方法中,针对 categorical feature,我们会把它展开成一个 sparse vector,里面只有一个或者几个 element 是 1, 其他的位置上全都是 0。One-hot 和 multi-hot 的主要区别在于在这个 sparse vector 里面能有几个位置上有 1,one-hot 只有 1 个,而 multi-hot 可以有多个
Feature transformation
除了上面的处理办法,针对 feature 还有一些额外的变换,从而增加模型能够学习的 signal 的数量
- 在 Youtube 的这篇论文中,他们把一些 feature 用上了
sqrt,pow等变换,作为新的 feature 和原本的 feature 一起送入模型进行学习 - 我们还可以把不同的 feature 彼此之间做 bi-gram,从而显形的增加 feature interaction (2nd order interaction, 这个也是之前很多研究的一个重点,因此退出了诸如 DCN 等模型架构,不过在这些模型里面, feature interaction 是通过模型表征,而不是在输入上面做文章)
- 另外一种比较常见的做 feature transformation 的办法是给原本的 feature 添加 breakdown, 比如说我们算一类 item 的 CTR 数据,那么可以根据用户的性别添加一个 breakdown (说个题外话,这种 breakdown 现在也被用于处理用户数据上,从而实现 privacy preserve);
- 更加放飞自我的一种办法,我们可以先 train 一个 gbdt, 然后把 gbdt 的 leave node 作为一个 feature 输入模型(可以考虑作为一个 binary sparse vector,或者带着 leave node 上的 weight); 在 Facebook 的早期 ads 模型里面,大量的使用了这种方法,详情参考这篇论文
We found that boosted decision trees are a powerful and very convenient way to implement non-linear and tuple transformations of the kind we just described.
- 针对这一点,我在和 reddit 的 ads ranking 面试的时候,跟 hiring manager 有一个比较激烈的讨论(可能也是因为这样她把我拒了把吧); HM 一开始没有很理解使用 gbdt 来做 feature transformation 的思路,认为这不可行;在被我 convenience 这样做可行之后,又抛出来认为这样做没必要,因为可以调整模型架构来直接学习 tree 本身所 capture 到的一些复杂的 feature interaction; 针对这一点我是同意的,而且我也有幸参加到了 ads ranking 的 gbdt deprecation 的工作之中; 不够我们当时之所以 deprecate gbdt 更多的是从 maintenance cost 和 simplify tech stack 的角度,gbdt 本身仍然能够带来很不错的 model gain, 这也是为什么 deprecation 整了很长时间也没有完全取得胜利
Missing/Sentinel Value
如何处理 feature 的 missing value 或者 sentinel value 也是作为 machine learning engineer 我们经常要实际面对的问题。针对 missing value,大部分的时候我们会直接用 0 来取代,但是如果 0 也是一个合法值的话,会给模型造成困扰; 这个使用可以考虑使用 sentinel value 来表示 value 是否 missing, 把这个 sentinel value 做成一个新的 categorial feature 用在模型里面; 这样一来,原本的 feature 和这个新的 categorical feature 结合着使用,模型就能区分开来 feature value 是真的等于 0 还是单纯的 missing
Feature Optimization
这一部分一般属于 bouns point, 在实际的面试中,很少有机会会真的讨论到这里,我之前在 Facebook 的时候带领很多这方面的项目,因此也借着这个机会给大家简单的介绍一下
Feature Importance
当我们有大量的 feature 之后,一个头痛的问题就是我们要选用哪些 feature 进入到模型里面; 由于 infra 的一些 limitation, 把所有的 feature 都放入到模型中开销过于巨大,无法支持,因此一般我们会选择一个 subset feature 来放到 production 模型中,而选取 feature 的一个重要指标,就是 feature importance
这里插入一些题外话,除了由于 infra limitation 导致我们不能使用所有的 feature 以外,另外一个考虑的因素是 feature coorelation,我们通过 empirical 的研究发现,把 correlated feature 放入到模型里面不会给模型带来任何效果上的提升,而且反而可能会降低模型的效果;不过 correlated feature 倒是有助于提高模型的 robustness,所以这也是一个实际中我们需要 make 的 trade off; 在 Facebook ads 我们是尽可能 minimize feature correlation,从而把尽可能多的有 additional gain 的 signal 放入到模型中
Feature importance 可以从算法层面和工程层面两个角度讨论,工程层面的话主要就是涉及到各种 feature metadata 的管理,如何保证 feature candidate pool 是正确的(在复杂的系统中,feature serving 也是一个被高度优化的部分,导致有些 feature 只有在特定的环境下才可用),如何保证 feature 有足够的 coverage 等等;从算法层面,可以用来计算 feature importance 的方法有: shuffling algorithm, SHAP, integrated gradient 以及 binary stochastic neuron 等,这里就不再展开讨论了
当通过上面提到的方法得到 feature importance score 之后,我们就可以使用 top k 的方法来选取 feature,除了这种简单的 selection strategy 之外,我们还可以引入其他的一些 metrics,比如 feature serving cost, feature storage cost 等等来进行 joint optimization
Hash Size Tuning
我们在前讨论 id feature 的时候,大量的提到了 embedding lookup table 这样一个重要的 component. 它有两个很重要的 hyper parameter,embedding dim 和 cardinality, 可以理解为 embedding lookup table 的的行数和列数. 由于 id space 巨大,如果给每一个 id 都提供一个单独的 embedding 的话,模型的 paraemter 会过于巨大,因此我们通常采用 hash trick, 也就是通过一个 hash function 把原本的 id 映射到另外一个空间上面,然后这个空间的 cardiality 就是我们 embedding lookup table 的列数,一般我们也把这个 cardinality 称作 hash size. 如果 hash size 设置的太大,那么会浪费空间,如果太小,又会导致太多的 collision 从而影响性能(尤其是对 tail id 来说),因此如何找到一个比较好的 hash size 也是一个玄学
这里再插入一个题外话,目前主流的一些 hash function 基本上是 semantic-less 的,也就是说很有可能一些非常 popular 的 id, 比如大V们的 post 和一些 tail id 比如我的 post 是被 hash 到同一个 bucket 里面去了,这会导致这个 embedding 会被这些大V们的 post overwhlem,而不会有太多的我的 post 的 representation. 这其实是一个 known issue, 业界也有一些尝试用更复杂的 hash function, 比如基于 culster 的 hash 来处理
有两种 hash size 的方法可以使用,一种是在 traning dataset 上 sample 一部分数据之后做分析,看不同的 hash size 情况下 collision 的情况,然后动态的调整(比如使用二分搜索)使得 hash size 能够满足一定的 collision rate 的阈值需要;另外一种方法是先给一个很大的 hash size,然后我们在模型训练的时候同时保存一个 counter 来记录各个 column 的 hit rate, 然后再模型训练完毕之后根据这个 hit rate 来做一个 post-processing
针对 embedding dimension, 目前主流的做法就是用一个 single dimension, 但是有一些研究尝试用 variable dimension, Google 曾经有一篇 paper 但是我现在找不到了,之后找到了再 update 过来
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Acknowledgemment
感谢 Yuan 大佬,Bing 姐和 Yuzhong 大佬提供的修改和补充意见,让这篇 blog 更加的完善
Reference
- Deep Interest Network for Click-Through Rate Prediction
- Scaling User Modeling: Large-scale Online User Representations for Ads Personalization in Meta
- Enhancing homepage feed relevance by harnessing the power of large corpus sparse ID embeddings
- User Action Sequence Modeling for Pinterest Ads Engagement Modeling
- Evolution of Ads Conversion Optimization Models at Pinterest
- Real-time Short Video Recommendation on Mobile Devices
- Privileged Features Distillation at Taobao Recommendations
- Practical Lessons from Predicting Clicks on Ads at Facebook
- How we use AutoML, Multi-task learning and Multi-tower models for Pinterest Ads
- PinnerFormer: Sequence Modeling for User Representation at Pinterest
Comments powered by Disqus.