A Random Walk Down Recsys - Part 3
Welcome back to the third installment of A Random Walk Down Recsys. This time, all five papers revolve around a single theme: Semantic IDs (SIDs) — how to generate them, how to improve their quality, and how to leverage them effectively in generative recommender (GR) models. The papers span a wide range of ideas: compressing long user sequences through SID hierarchies, injecting reasoning capabilities into SID-based re-ranking, producing better embeddings for SID quantization, handling the unique challenges of live-streaming content, and even bypassing the traditional two-stage SID pipeline entirely with end-to-end MLLM generation.
The five papers covered are: GLASS (Kuaishou), Generative Reasoning Re-ranker (Meta), QARM V2 (Kuaishou), OneLive (Kuaishou), and End-to-End Semantic ID Generation (Tencent).
GLASS: Long-Sequence Modeling via SID-Tier and Semantic Search
Paper: https://arxiv.org/pdf/2602.05663)
This Kuaishou paper centers on a key insight: the hierarchical structure of semantic IDs is an under-exploited resource, particularly the first-level SID token $\text{SID}_1$ and its corresponding codebook $\text{codebook}_1$. GLASS leverages this hierarchy in two ways — compressing long-term user sequences into a compact representation, and guiding the SID decoding process through semantic search.
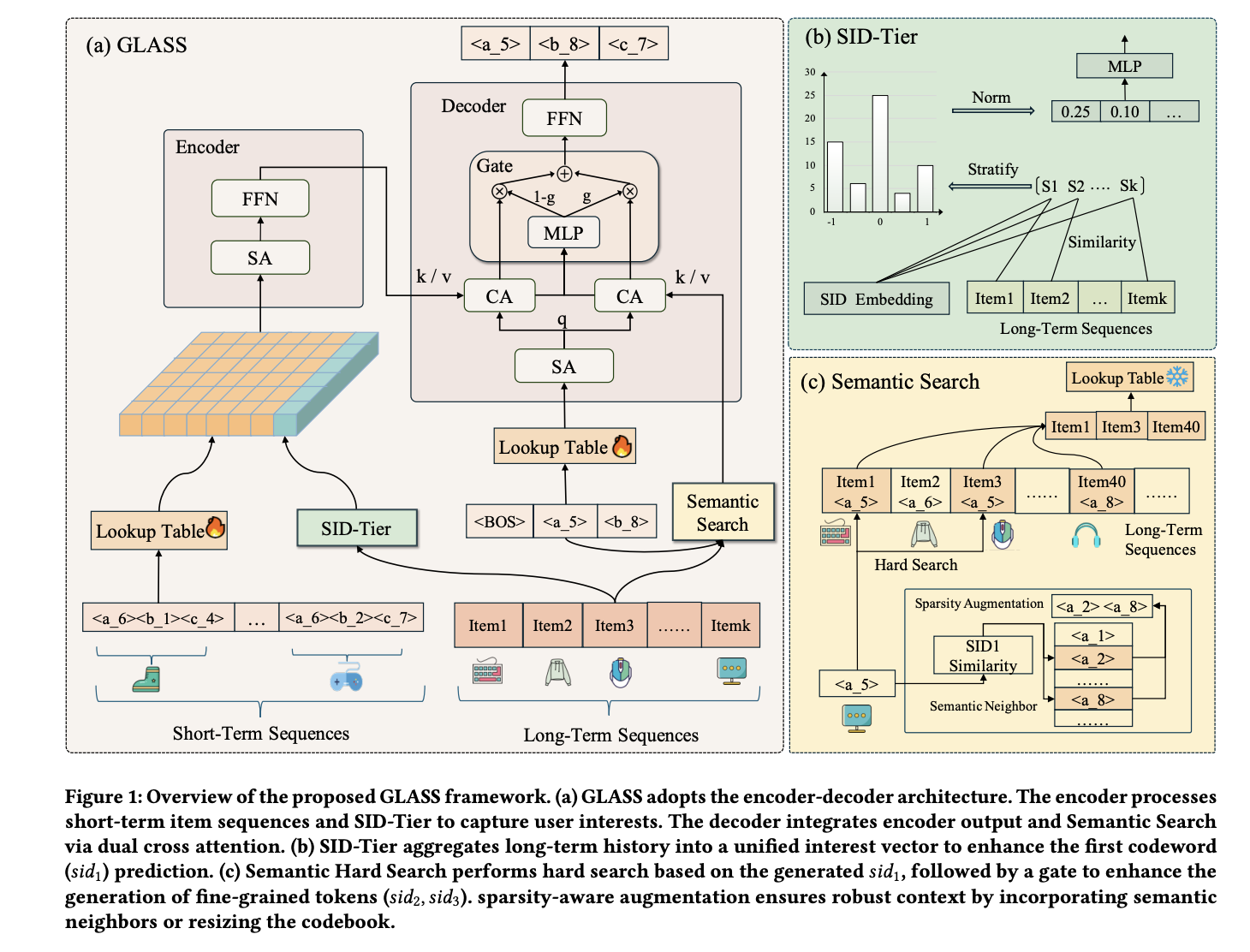
SID-Tier: Compressing Long Sequences via Codebook Heatmaps
Each SID token is mapped to an embedding through a standard embedding lookup. The core innovation is using $\text{codebook}_1$ to compress the information contained in long user behavior sequences. The mechanism works as follows:
- Compute the cosine similarity between every item in the long sequence and every vector in $\text{codebook}_1$.
- Bucket and count the similarity scores to form a heatmap of size $K_0 \times N$, where $K_0$ is the codebook size and $N$ is the number of buckets.
- Pass the heatmap through an MLP to compress it into a single token — the SID-Tier token.
This token is appended to the short-term user sequence before being fed into the encoder, effectively injecting a compact summary of long-term interests without the computational cost of attending to the full long sequence.
Semantic Search Decoding
During decoding, GLASS introduces a dual-source cross-attention mechanism:
- The short-term sequence serves as one set of keys and values.
- Based on the generated $\text{SID}_1$, the model searches the user’s long-term history for items whose first SID token matches $\text{SID}_1$, forming a second set of keys and values.
- The decoded SID token acts as the query, performing cross-attention against both sources.
- A gating function then computes a weighted combination of the short-term and long-term attention outputs.
The paper frames this retrieval mechanism as RAG-like, though it is more reminiscent of Search-based Interest Models (SIM) in spirit.
Handling Sparse Retrieval
When the long sequence is short or the codebook is large, the SID-based retrieval may return too few items. Two solutions are proposed:
- Approximate matching: Include items with similar (but not identical) first-level SIDs.
- Smaller $\text{codebook}_1$: Use a codebook with fewer entries to increase the number of items per bucket. Interestingly, this is the opposite direction from what PLUM advocates.
Ablation Insights
The ablation study reveals that GLASS achieves larger improvements on the Taobao dataset than on KuaiRec. The authors attribute this to the fact that Taobao embeddings were generated through supervised contrastive learning, which produces higher-quality representations — a reminder that SID quality is fundamentally bounded by the quality of the input embeddings.
Generative Reasoning Re-ranker
Paper: https://arxiv.org/pdf/2602.07774
This Meta paper explores using generative models with semantic IDs for re-ranking, incorporating chain-of-thought reasoning into the generation process. The work has been evaluated on Amazon datasets but does not report production deployment results.
Semantic ID Training
The paper does not specify the exact input embeddings, though they appear to be text-based item description embeddings. The focus is instead on improving codebook utilization through several techniques, ranked by contribution:
- EMA update (highest impact): Exponential moving average updates to the codebook vectors, which effectively prevents codebook collapse — a well-known failure mode where most entries go unused.
- Random last-M codebook (second highest): During inference, the last $M$ codebook layers use random assignment. This introduces diversity in the tail layers where exact assignment matters less.
- Dead code reset: If a codebook entry goes unused for several batches, it is reset to the input vector that is farthest from any existing entry.
- K-Means initialization: Standard practice for initializing codebook entries.
- Diversity loss: A regularization term encouraging uniform codebook usage, though its impact is marginal.
Additionally, a contrastive loss is introduced during SID training, which yields a substantial improvement in downstream re-ranking performance.
Pre-Training
The item alignment stage interleaves textual descriptions with SID tokens and trains via next-token prediction (NTP) — the same approach as Continual Pre-Training (CPT) in PLUM. This aligns the SID representations with the LLM’s latent space.
Post-Training: Reasoning Trace Generation
A major contribution is the construction of reasoning traces for training. A teacher model is prompted to generate structured reasoning data through two sampling strategies:
- Target sampling: The ground-truth item is provided, and the teacher generates a reasoning path toward it.
- Rejection sampling: No ground truth is given; the teacher performs multiple inference rounds until it produces a correct recommendation.
The reasoning traces follow a structured multi-step format:
- System role and task definition
- Collaborative context: The user’s purchase history
- Domain knowledge priming: E-commerce common sense
- Critical guidelines: Output constraints such as requiring SID citations
- Structured reasoning steps: Guided steps such as identifying product type, analyzing user preferences, etc.
Reinforcement Learning with DAPO
The RL stage uses DAPO (Dynamic Advantage Policy Optimization), which is similar to GRPO but addresses entropy collapse and rollout length bias by using separate upper and lower clip thresholds. The training combines two losses:
- A reasoning trace loss for the quality of the generated reasoning chain.
- A ranking loss for the correctness of the final recommendation.
The reward signal comes from the prompted distance in the re-ranker, supplemented by a format reward to ensure structural compliance of the output.
QARM V2: Multi-Modal Recommendation with Improved Embeddings and SID Quantization
Paper: https://arxiv.org/pdf/2602.08559
This Kuaishou paper tackles two interconnected problems in generative recommendation: (1) how to make LLMs better embedding generators for recommendation tasks, and (2) how to reduce SID collisions through improved quantization strategies.
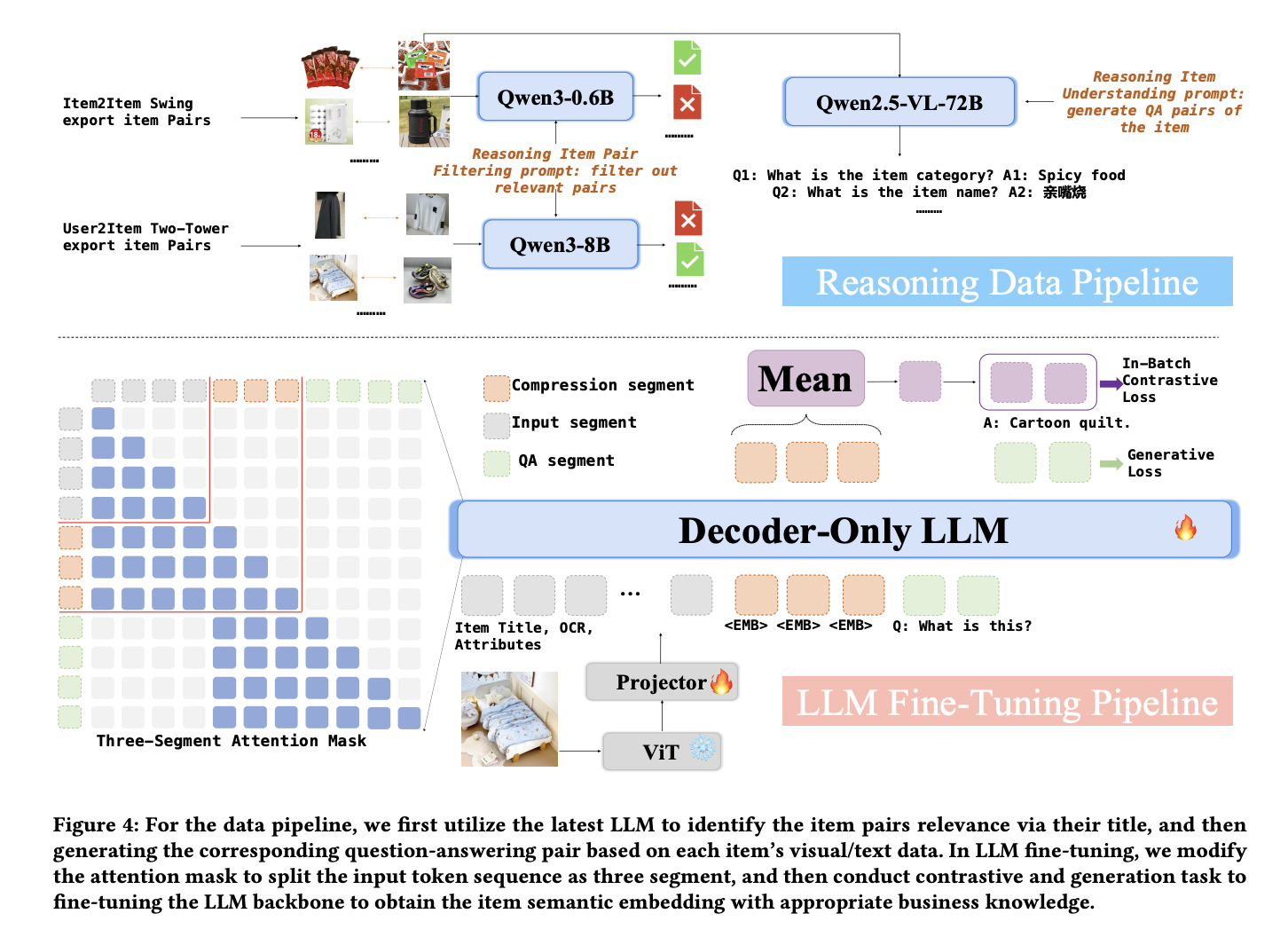
Making LLMs Better Embedding Generators
LLM embeddings are not inherently optimized for search, advertising, and recommendation tasks. QARM V2 proposes a pipeline to address this.
Data Denoising via LLM Reasoning
Item pairs derived from I2I (Swing) and U2I (Two-Tower) models are inherently noisy. The paper uses LLM reasoning to filter these pairs:
- I2I pairs: ~10% are filtered out as noise.
- U2I pairs: ~70% are filtered out — a striking difference that highlights how much noisier user-item collaborative signals can be.
The surviving pairs are then used to generate QA pairs through reasoning, which serve as auxiliary training data.
Hybrid Training with Item-Embed-QA Format
The embedding generation adopts a structured input format: <item segment><embed token><qa segment>. The attention flow is designed so that:
- The
<embed token>attends to the<item segment>to absorb item information. - The
<qa segment>attends to the<embed token>to leverage the condensed representation.
The <embed token> outputs are pooled and trained with in-batch contrastive loss, while the QA segment is trained with standard NTP loss. This hybrid approach preserves both contrastive training and language modeling objectives, outperforming pure contrastive learning alone.
SID Quantization: RQ-KMeans + FSQ
A key observation is that the first two layers of RQ-KMeans already capture categorical information well. The last layer, therefore, should focus on maximizing item-level diversity to minimize SID collisions. QARM V2 adopts a hybrid quantization strategy:
- 2 layers of RQ-KMeans for the coarse hierarchical structure.
- Finite Scalar Quantization (FSQ) for the final layer to maximize diversity.
Training is performed on 10M samples in a single batch rather than online mini-batch updates, which helps produce more stable codebooks and reduces collisions.
Usage in the Recommendation Pipeline
The embeddings and SIDs serve different roles in a cascaded retrieval architecture:
- Embeddings power the GSU (General Search Unit / coarse retrieval) stage.
- SIDs are used as individual tokens in the ESU (Exact Search Unit / fine-grained ranking) stage.
Practical Observations
Even with RQ-KMeans + FSQ, the collision rate remains at 32% — a sobering number that reinforces the difficulty of achieving low collisions in large-scale item catalogs. On the serving side, QARM V2 uses a graph engine for online SID serving, which could be a useful reference for production deployments.
OneLive: Generative Framework for Live-Streaming Recommendation
Paper: https://arxiv.org/pdf/2602.08612
This Kuaishou paper extends the generative recommendation paradigm to live-streaming scenarios. Live streaming poses unique challenges: content within a single stream changes rapidly, user behavior shifts accordingly, and the strong timeliness of live content demands real-time semantic understanding.
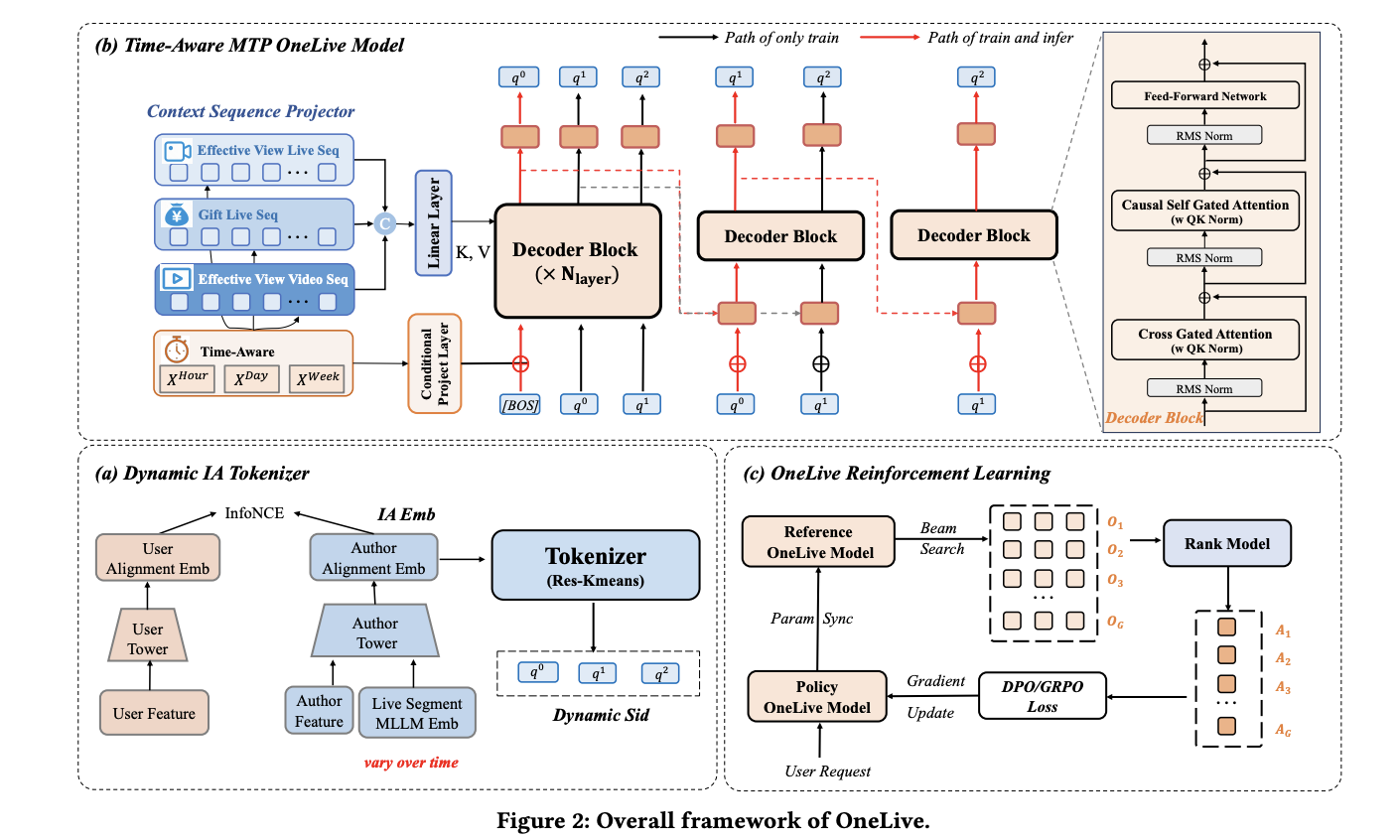
Dynamic Embedding Generation
Traditional static embeddings fail for live-streaming content because the semantic meaning of a stream evolves continuously. OneLive addresses this with a sliding-window MLLM approach:
- A lightweight MLLM (distilled from a larger teacher LLM) processes live-stream content every 30 seconds through a sliding window.
- The generated embeddings are fed into a dual-tower model (User Tower and Author Tower).
- The towers are fine-tuned with contrastive learning to align user and author representations in a shared space.
SID generation itself uses standard RQ-KMeans — the innovation here is entirely in the dynamic embedding pipeline that feeds into it.
Pre-Training Architecture
The backbone follows OneRec V2’s context processor design: a decoder-only architecture where the user sequence is processed through a context processor to generate keys and values.
Temporal Injection: Time information is injected into every token in the sequence. During decoding, the BOS token also carries temporal information, grounding the generation process in the current time context.
Multi-Token Prediction: Inspired by DeepSeek V3, OneLive introduces multi-token prediction — something I had been considering as well, and it is encouraging to see it applied in practice. The approach works as follows:
- Two lightweight auxiliary decoders (single-layer each) are added alongside the main decoder.
- During training, all three decoders predict their respective SID tokens ($q_0$, $q_1$, $q_2$) in parallel.
- Each auxiliary decoder takes the previous decoder’s hidden state and the current preceding SID embedding as input.
- During inference, the main decoder generates $q_0$, then the auxiliary decoders generate $q_1$ and $q_2$ sequentially.
While the inference is still sequential in nature, the auxiliary decoders are far simpler than the main decoder, yielding meaningful latency improvements.
Post-Training with RL
A ranking model serves as the reward model for RL training. The paper compares DPO and GRPO, finding that GRPO consistently outperforms DPO.
An interesting engineering note: RL is integrated into the offline stream training pipeline. This raises practical questions about implementation — for instance, how to combine VERL with FSDP-based model backends for efficient distributed RL training.
End-to-End Semantic ID Generation for Generative Advertisement Recommendation
Paper: https://www.arxiv.org/pdf/2602.10445
This Tencent paper challenges the conventional two-stage SID pipeline (first generate embeddings, then quantize via RQ-VAE). Instead, it proposes fine-tuning an MLLM to directly generate SID tokens from multi-modal inputs in a single end-to-end framework.
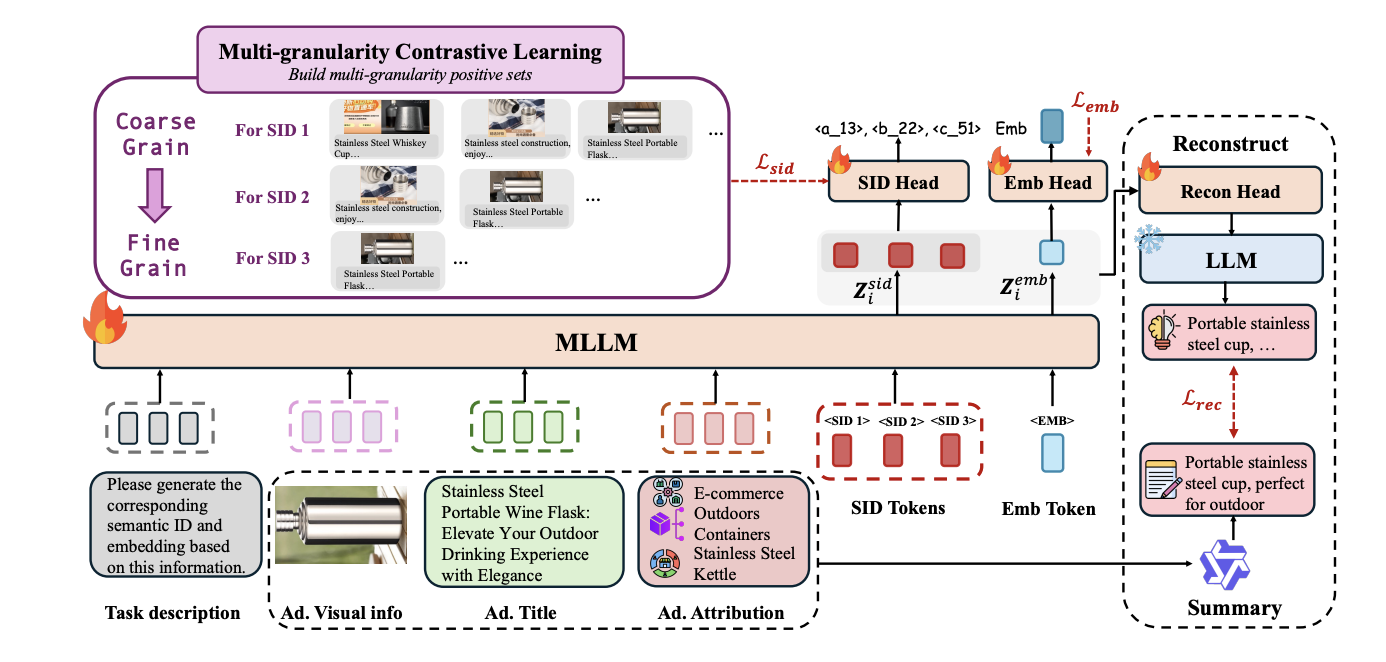
Training Framework
The input to the MLLM is organized as follows:
- Multi-modal tokens: Ad image, ad title, and product attributes (e.g., product category) are tokenized and concatenated.
- Task description prompt: A prefix prompt describing the SID generation task.
- Learnable SID tokens: Placeholder tokens that the model learns to fill with appropriate SID values.
<EMB>token: A special token whose hidden state is used for embedding extraction.
Multi-Task Training Objectives
The model is trained with several complementary losses:
- SID projection + contrastive loss: The MLLM’s output at SID token positions is passed through a SID head that projects onto the SID vocabulary (with appropriate partitioning across layers). A contrastive loss aligns SID embeddings of items within the same ad category (positive set).
- Embedding contrastive loss: The
<EMB>token’s representation is trained via standard contrastive learning. - Ad summary reconstruction: A frozen large model generates ground-truth summaries from ad attributes. A reconstruction head takes the hidden states of both SID and
<EMB>tokens as input and uses them as conditioning for an LLM to reconstruct the summary via NTP. This auxiliary task is conceptually similar to the QA reasoning component in QARM V2 — both use generative reconstruction to ensure that the learned representations retain rich semantic information.
Why End-to-End Matters
By unifying embedding generation and SID quantization into a single MLLM forward pass, this approach avoids the information loss inherent in the two-stage pipeline, where the quantization step is disconnected from the upstream embedding objective. The MLLM can jointly optimize for both representation quality and quantization fidelity.
Comparison of Semantic ID Approaches
All five papers tackle different facets of the semantic ID problem. The table below summarizes their approaches across key dimensions:
| Dimension | GLASS | Reasoning Re-ranker | QARM V2 | OneLive | E2E SID (Tencent) |
|---|---|---|---|---|---|
| SID Generation | Standard (not the focus) | RQ-KMeans with codebook utilization tricks | 2-layer RQ-KMeans + FSQ | RQ-KMeans on dynamic embeddings | End-to-end MLLM generation |
| Input Embedding | External (quality-dependent) | Text-based | LLM with hybrid CL + NTP training | Sliding-window MLLM + dual-tower CL | Multi-modal MLLM (image + text + attributes) |
| Codebook Utilization | Smaller codebook as fallback | EMA, dead code reset, random last-M, K-Means init | FSQ for last layer, 10M-sample batch training | Not discussed | Learned end-to-end (no explicit codebook tricks) |
| Collision Handling | Approximate SID matching, smaller codebook | Random last-M codebook | FSQ final layer (still 32% collision) | Not discussed | Implicit via joint optimization |
| How SID Is Used | SID hierarchy for long-sequence compression + decoding search | Token-level NTP with reasoning traces | Individual tokens in ESU stage | Tokens with multi-token prediction | Tokens generated directly by MLLM |
| Contrastive Loss | Not discussed | Yes (large impact on re-ranking) | In-batch CL for embeddings | Dual-tower CL for embeddings | SID-level CL (same-category positives) + embedding CL |
| RL Method | N/A | DAPO | N/A | GRPO > DPO | N/A |
| Unique Contribution | Exploiting SID hierarchy for long-sequence modeling | Structured reasoning traces for re-ranking | Hybrid CL+NTP embedding training, LLM-based data denoising | Dynamic embeddings for live content, multi-token prediction | Eliminating the two-stage pipeline entirely |
Key Observations
The two-stage pipeline is not sacred. Tencent’s end-to-end approach demonstrates that the conventional embedding-then-quantize pipeline can be replaced with a single MLLM forward pass. Whether this scales to the billion-item catalogs of the other papers remains to be seen.
Codebook utilization remains a practical challenge. Meta’s systematic study shows that EMA updates and random last-M assignment are the most effective techniques. QARM V2’s 32% collision rate even with FSQ underscores that this problem is far from solved at scale.
Embedding quality is the foundation. GLASS’s ablation (supervised contrastive learning embeddings vs. standard ones) and QARM V2’s hybrid training both confirm that better input embeddings translate directly to better SIDs and better downstream performance.
SID hierarchies are under-exploited. GLASS uniquely leverages the hierarchical structure of SIDs for both sequence compression and retrieval-guided decoding. Most other works treat SID tokens as flat sequences — there may be significant untapped potential in hierarchy-aware approaches.
Contrastive loss is consistently valuable. Every paper that introduces contrastive learning (Meta for SID training, QARM V2 for embeddings, OneLive for dual-tower alignment, Tencent for SID + embedding) reports meaningful improvements. This suggests that contrastive objectives are complementary to the standard NTP training regime.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.