A Random Walk Down Recsys - Part 2
Welcome back to the second installment of A Random Walk Down Recsys. In this post, I continue surveying interesting papers from the Arxiv IR section, covering five recent works: HyFormer, Token-level Collaborative Alignment, OneMall, a Sparse Attention approach for long-term user behaviors, and Farewell to Item IDs.
HyFormer: Hybrid Cross-Attention for Sequential and Non-Sequential Features
This paper from TikTok focuses on a practical yet under-explored problem: how to effectively perform cross-learning between sequential features (e.g., user behavior histories) and non-sequential features (e.g., user profiles, context signals).
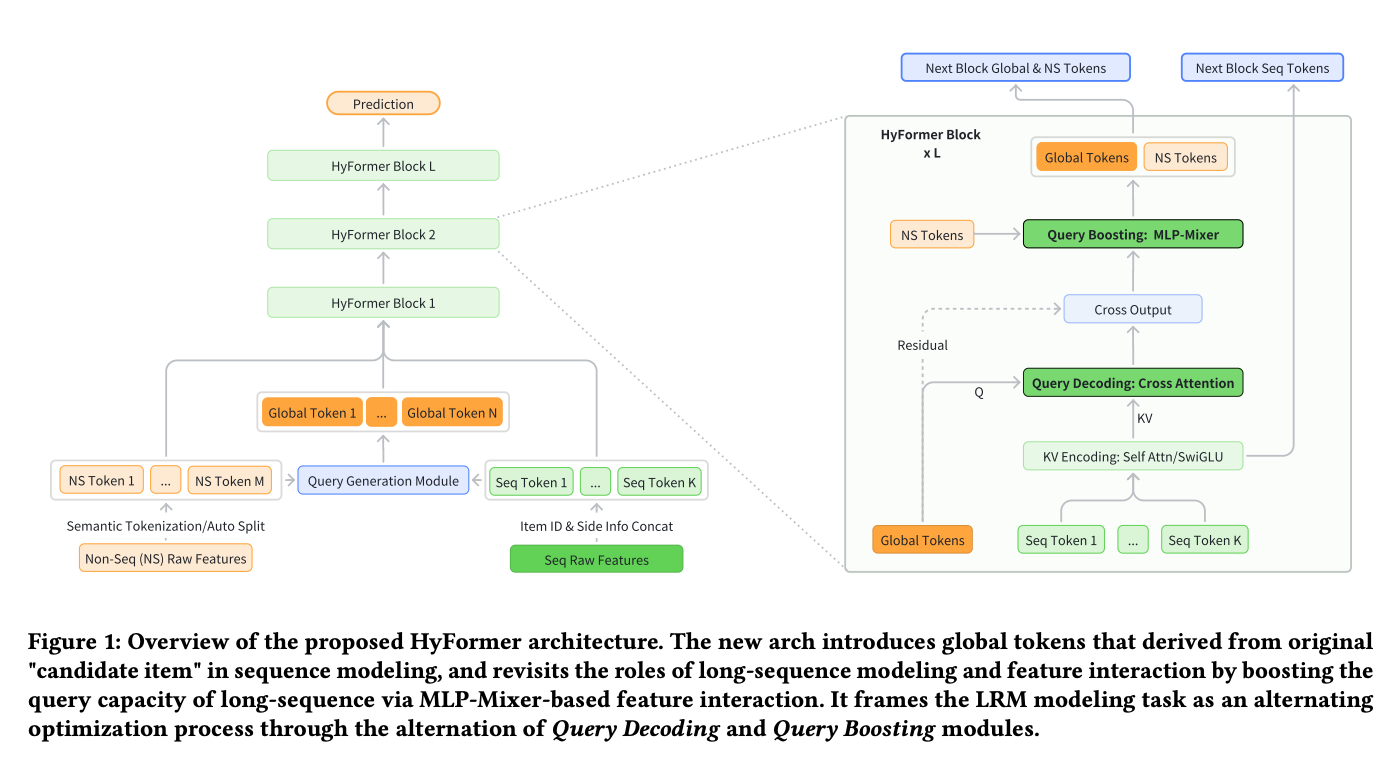
Global Query Token Generation
The approach begins by constructing global query tokens from both feature types:
- Non-sequential features are grouped semantically, and each group is concatenated and passed through a feed-forward network (FFN) for non-linear transformation.
- Sequential features are compressed via pooling and similarly passed through an FFN.
This produces $(N)$ global query tokens that serve as the bridge between the two feature modalities.
Query Decoding: Extracting Information from Sequences
The first key component is Query Decoding, which performs cross-attention between the global query tokens and sequential information. The KV extraction from the sequence is designed to be configurable: it can use a standard Transformer, or a dual short-sequence/long-sequence cross-attention mechanism similar to LONGER. The intuition here is akin to deep cross networks: the global query tokens iteratively extract relevant information from the sequence to form enriched representations for downstream layers.
Query Boosting: Reintroducing Non-Sequential Interactions
The second component, Query Boosting, reintroduces interaction with non-sequential features. It adopts the RankMixer approach: global query tokens and non-sequential feature tokens are split along the feature dimension (similar to product quantization), then recombined. This effectively reshapes the representation from $(D \times T)$ to $(T \times D)$, enabling richer cross-feature interactions.
Multi-Sequence Handling
For users with multiple behavior sequences (e.g., clicks, purchases, searches), HyFormer does not fuse sequences early. Instead, each sequence follows its own independent path and is only merged during the Query Boosting stage—a design choice that preserves sequence-specific signals while still enabling cross-sequence interaction.
Infrastructure Optimizations
The paper also contributes on the systems side:
- GPU-side Feature Reconstruction: Features are stored in a compressed embedding table and reconstructed on GPU using a deduplication-like mechanism, reducing memory overhead.
- Async All-Reduce: Gradient synchronization for step $(k)$ is overlapped with the forward/backward pass of step $(k+1)$, improving training throughput.
Token-level Collaborative Alignment for LLM-based Generative Recommendation
This paper introduces a novel approach to inject collaborative filtering signals into the training of generative recommenders (GR). The core idea is to derive a token-level probability distribution from collaborative signals and incorporate it as a soft label during next-token prediction (NTP) training.
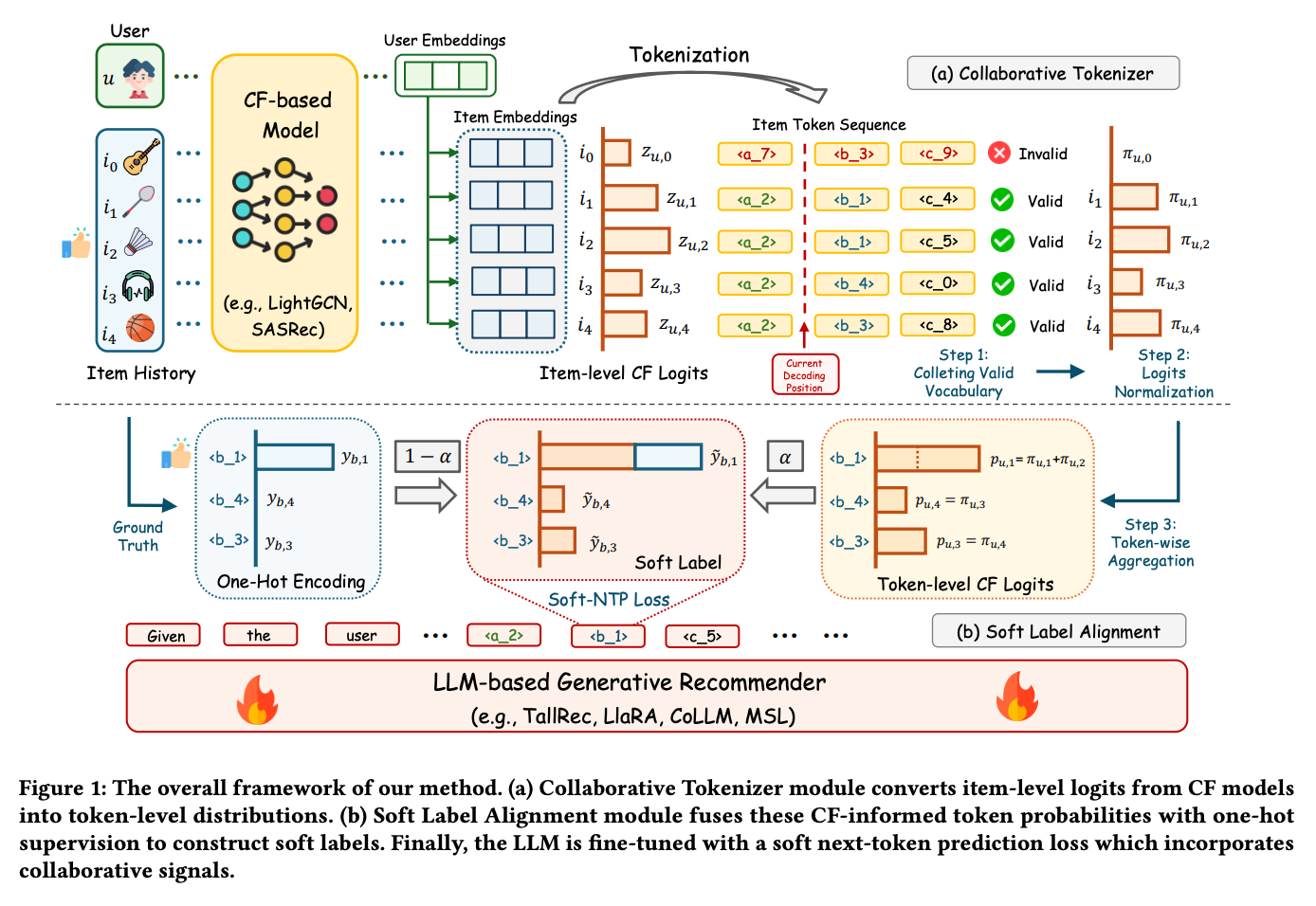
Collaborative Signal Computation
Collaborative information is computed via traditional ID-based models using user and item embeddings with a scoring function (e.g., dot product). Although the paper does not elaborate, this likely requires computing scores for all user-item pairs.
Token Distribution Construction
The process works as follows:
- Tokenization: Item textual information is converted into token sequences using the LLM tokenizer.
- Prefix-based Item Grouping: At each decoding position, items are grouped by their shared prefix in the token sequence.
- Logit Normalization: The collaborative scores within each group are normalized.
- Cumulative Token Probability: By examining the next token at each decoding position and accumulating probabilities, a token-level distribution is derived.
This distribution is then used as a soft label alongside the standard NTP loss during training, effectively distilling collaborative knowledge into the generative model’s token-level predictions.
OneMall: End-to-End Generative Recommendation with Semantic IDs
OneMall presents a comprehensive pipeline for generative recommendation, spanning semantic ID generation, pre-training, and post-training with reinforcement learning.
Semantic ID Generation
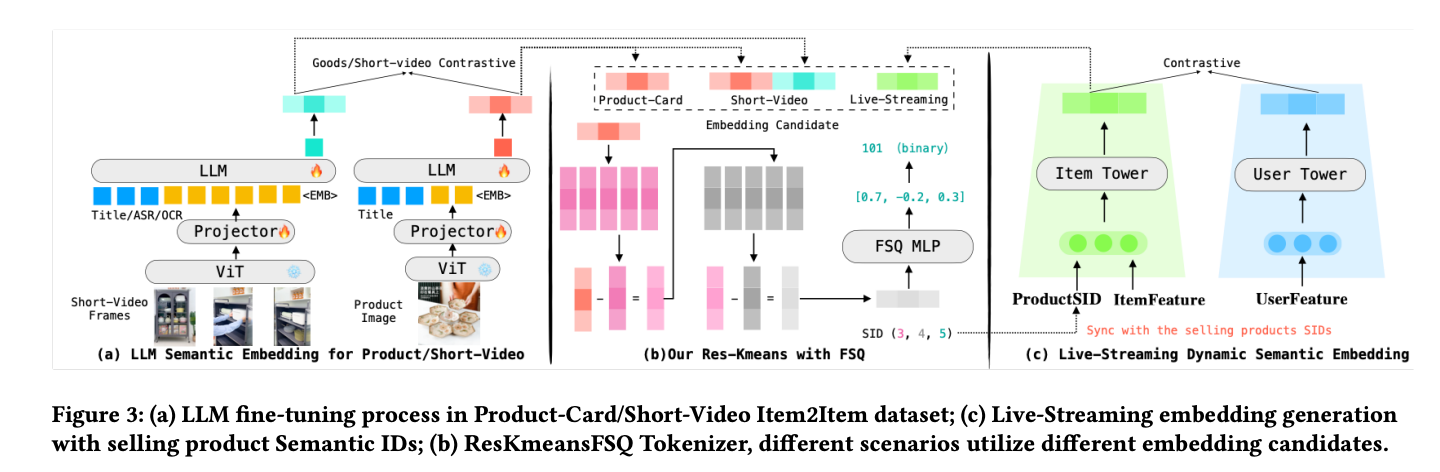
The semantic ID pipeline takes a distinctive approach:
- Embedding Generation: I2I (item-to-item) datasets are mined to train specialized embeddings. Swing Transformer and Qwen3 are used for processing, followed by fine-tuning an LLM with InfoNCE loss to produce the final embeddings.
- Quantization with FSQ: Rather than standard RQ-KMeans, OneMall adopts Finite Scalar Quantization (FSQ) for the residual component, which significantly reduces ID conflicts—from ~36% with RQ-KMeans down to ~11% with FSQ.
However, an interesting observation from their experiments is that this dramatic reduction in conflict rate does not translate into a proportionally significant improvement in Hit Rate. This suggests that pursuing extremely low conflict rates may yield diminishing returns.
Pre-training Architecture
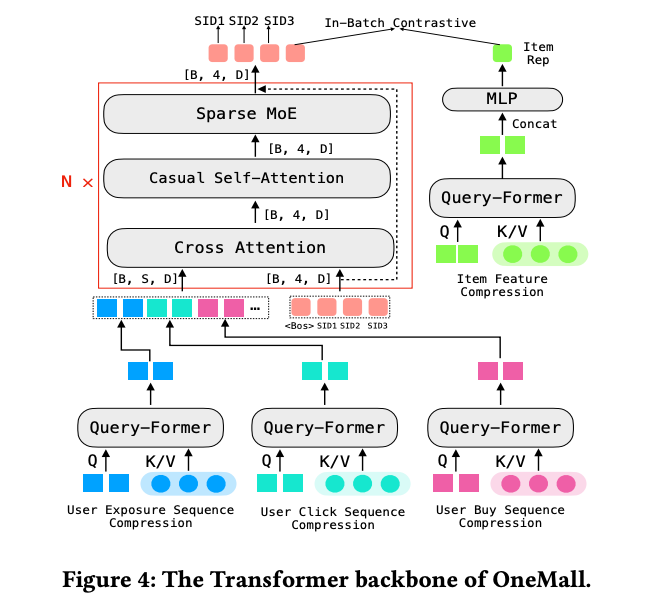
The backbone employs several noteworthy design choices:
- Query-Former for Long Sequence Compression: Long user behavior sequences are compressed using a Query-Former mechanism, reducing computational cost while preserving essential information.
- Cross-Attention for SID Generation: Semantic IDs are generated through cross-attention, allowing the model to attend to compressed sequence representations.
- Sparse MoE: A Sparse Mixture-of-Experts layer is introduced to increase the model’s learnable parameter capacity without proportionally increasing compute.
An interesting detail: the hidden state of the last SID token is extracted and used to compute a contrastive loss against item representations. Here, item features are also compressed through a Query-Former into a single item representation, creating an additional alignment signal between generated SIDs and item semantics.
Post-training with Reinforcement Learning
The post-training stage uses RL with the following setup:
- An online ranking model serves as the reward model.
- A reference model performs rollouts to generate multiple candidate samples.
- The reward model scores these samples.
- The policy model is then updated based on these scores.
- The reference model is periodically synchronized with the policy model.
This iterative RL loop progressively refines the model’s generation quality beyond what supervised training alone can achieve.
Sparse Attention for Long-Term User Behavior Modeling
This paper from Meituan addresses long-sequence modeling for CTR prediction. Its central argument is that user behavior sequences fundamentally differ from natural language text—they exhibit strong personalization and temporal patterns that require specialized attention mechanisms.
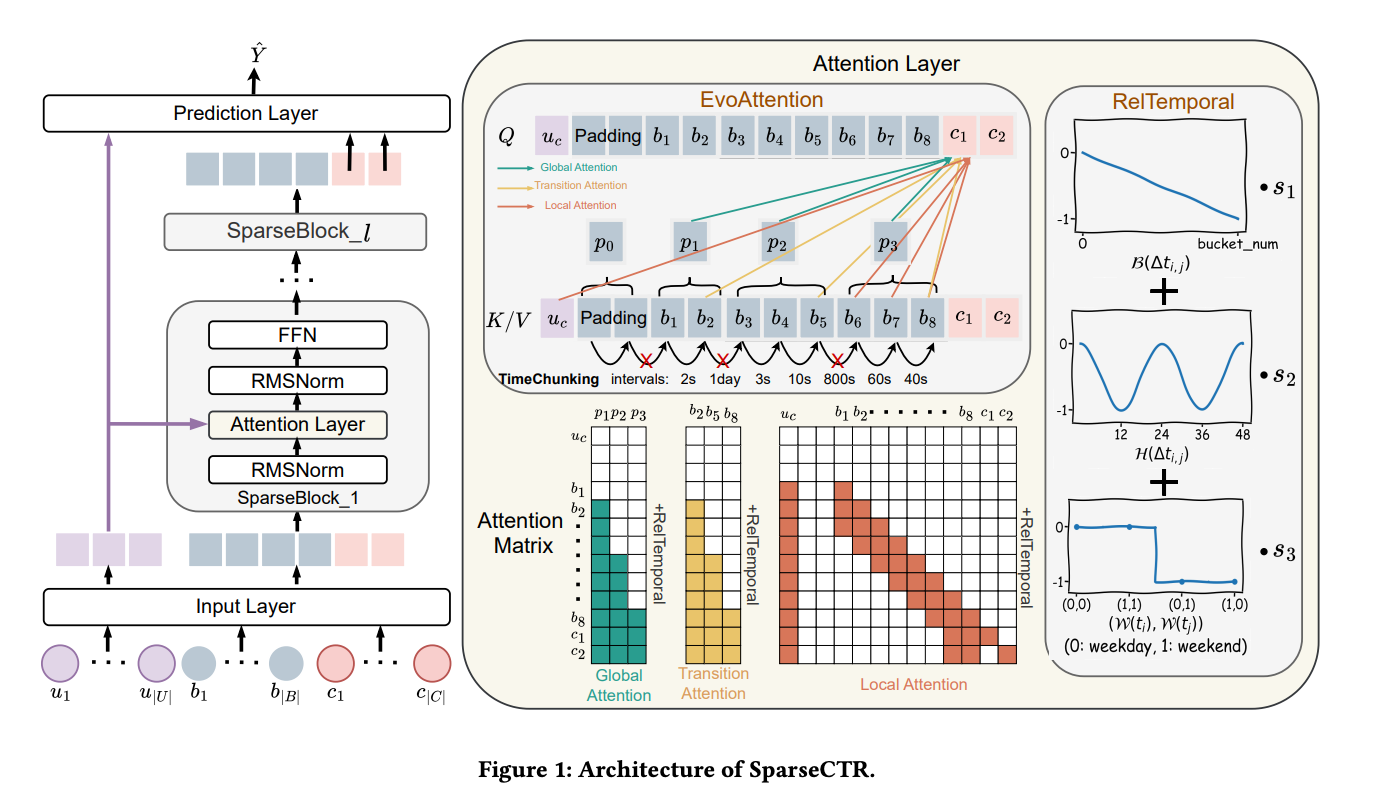
Evolutionary Sparse Self-Attention for Personalization
The proposed personalization mechanism consists of three attention types:
Temporal Chunking: The user’s long behavior sequence is chunked based on the time gap between adjacent actions, using top-k selection to determine chunk boundaries (with padding for uniformity). While the authors frame this as capturing personalized patterns, the chunking is purely temporal.
- Three-Level Attention:
- Global Attention: Keys and values within each chunk are aggregated to form chunk-level representations, enabling attention across all chunks.
- Transitional Attention: The last few actions from each chunk are selected to capture cross-chunk transition patterns.
- Local Attention: A sliding window mechanism over the full sequence, with the user embedding prepended as the first token.
- Gated Fusion: The outputs from all three attention types are combined via a learned gating mechanism.
Temporal Encoding
The temporal encoding is particularly well-designed with three components:
- Time Delta Encoding: Time differences between actions are bucketized, and each attention head has a learnable parameter controlling its temporal sensitivity.
- Hour-of-Day Encoding: A sinusoidal encoding captures periodic daily patterns.
- Weekend Encoding: A binary signal (0 if both actions $(i)$ and $(j)$ fall on weekends, -1 otherwise) captures weekly periodicity.
All temporal biases are summed and added to the scaled dot-product attention scores before softmax computation.
Prediction and Results
For CTR prediction, the model extracts the last-layer representation corresponding to the candidate item’s position in the sequence, concatenates it with the user embedding, and feeds it through an MLP.
In their experiments, the proposed sparse attention mechanism outperforms alternatives such as NSAttention and DilatedAttention. They also compare different chunking strategies (e.g., similarity-based chunking) and find that their time-gap-based approach performs best.
Farewell to Item IDs: Bridging Generalization and Memorization
This ByteDance paper tackles a fundamental tension in using semantic IDs for ranking models: semantic IDs excel at generalization but sacrifice memorization, leading to degraded performance when naively replacing traditional item IDs.
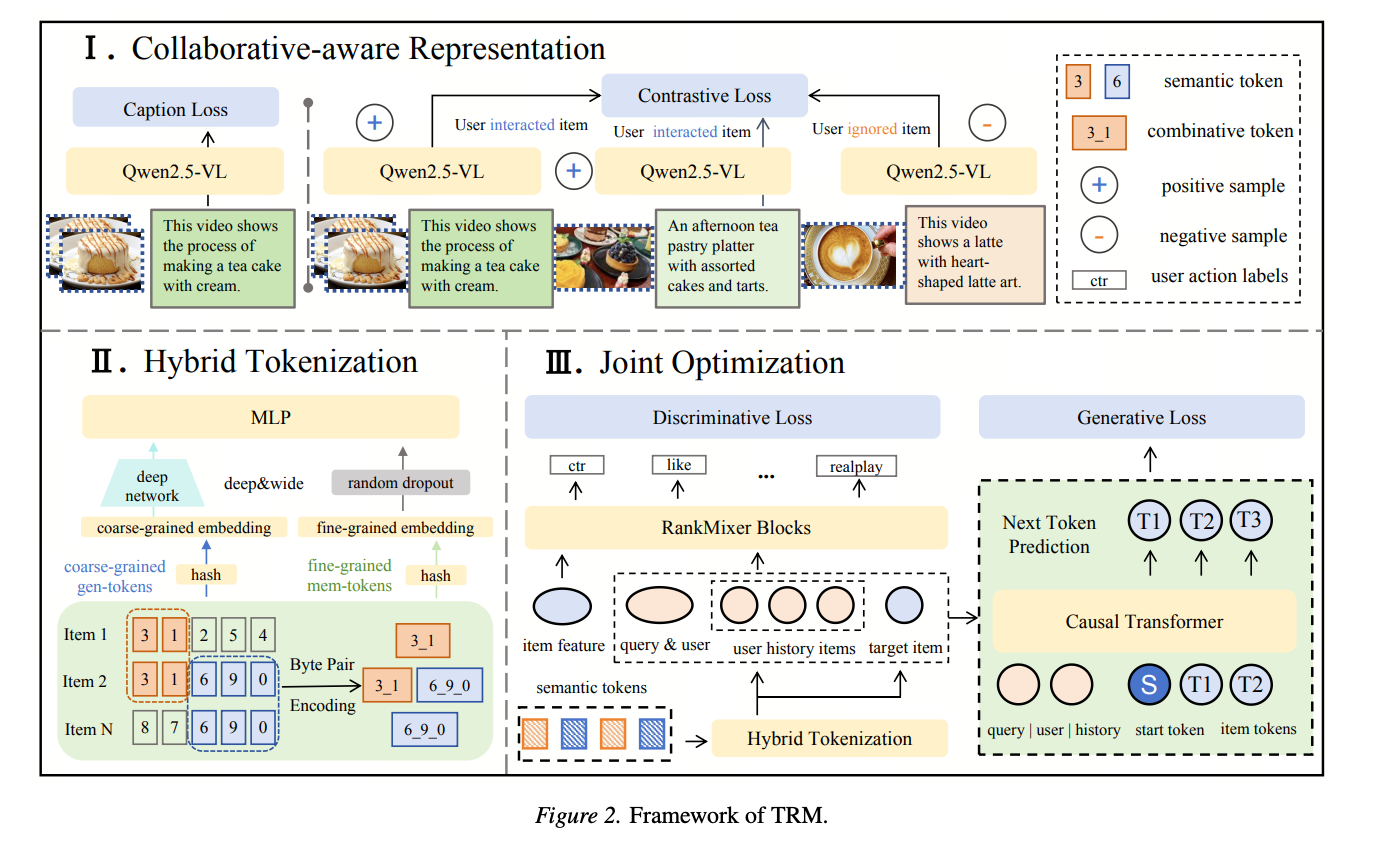
Collaborative-Semantic Embedding Alignment
The embedding generation pipeline first aligns collaborative and semantic signals through contrastive learning, fusing both types of information into a unified representation. RQ-KMeans is then applied to generate the final semantic IDs.
The Generalization–Memorization Trade-off
The paper explicitly acknowledges what many practitioners have observed: directly replacing item IDs with semantic IDs in ranking models hurts performance. The reason is that semantic IDs capture high-level semantic similarities but lose the fine-grained, instance-level memorization that traditional IDs provide.
Their solution is a dual-encoding approach:
- Semantic IDs handle the generalization component (broad semantic understanding).
- Encoded IDs handle the memorization component (instance-level discrimination).
These two representations are fed into separate branches of a Deep & Wide architecture, combining the strengths of both.
BPE-based ID Encoding for Memorization
The encoding for memorization is particularly creative: they train a Byte Pair Encoding (BPE) model on the semantic ID sequences to discover frequently co-occurring ID patterns. This is analogous to how BPE learns subword units in NLP: here it learns “sub-item” patterns that capture & memorize collaborative structure.
Training Objective
The final model is trained with both discriminative and next-token prediction (NTP) losses, consistent with the emerging standard in generative recommendation systems.
Key Takeaways
These five papers highlight several trends in the generative recommendation space:
Feature interaction design matters: HyFormer demonstrates that carefully orchestrated cross-attention between sequential and non-sequential features yields significant improvements over naive approaches.
Collaborative signals remain essential: Both Token-level Collaborative Alignment and Farewell to Item IDs show that collaborative filtering signals are complementary to semantic understanding—generative recommenders benefit from explicitly incorporating them.
Semantic ID quality has diminishing returns: OneMall’s experiments suggest that while reducing ID conflicts is important, the marginal benefit decreases rapidly. The generalization–memorization balance (as explored in Farewell to Item IDs) may be a more impactful direction.
Temporal-aware attention for user sequences: Meituan’s work reinforces that user behavior sequences require specialized treatment, particularly for temporal dynamics—that generic Transformer architectures do not natively provide.
RL-based post-training is becoming standard: Both OneMall and the broader trend in the field confirm that RL-based refinement after supervised pre-training is increasingly the norm for generative recommenders.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.