A Random Walk Down Recsys - Part 1
This is a new series of blog beyond my conference paper reading blog, in which I would summarize the paper that I found interesting form Arxiv IR section and share my learnings.
In this first blog, I would like to summarize key insights from four papers that represent the current state-of-the-art in generative recommendation: OpenOneRec, OxygenRec, Meta’s Efficient Sequential Recommendation, and Promise from Kuaishou. Each brings unique perspectives on how to effectively leverage large language models for recommendation tasks.
OpenOneRec: A Comprehensive Generative Recommendation Framework
OpenOneRec presents a systematic approach to building LLM-based recommendation systems through careful design of semantic IDs and multi-stage training.
Semantic ID Generation and Item Alignment
The semantic ID (SID) generation pipeline is thoughtfully designed with multi-modal inputs. The model combines a 4096-dimensional text embedding with a 5×1152-dimensional visual embedding, using the classic RQ-KMeans method for encoding. This multi-modal approach ensures rich item representations that capture both textual and visual semantics.
During pre-training, SIDs are added as new tokens to the vocabulary. The first stage focuses exclusively on item alignment, where only the SID embeddings are updated while all other parameters remain frozen. This design choice proves critical in their ablation studies—skipping this alignment stage significantly degrades performance.
An interesting implementation detail is the use of special tokens <|item_begin|> and <|item_end|> to isolate semantic IDs within the sequence. This boundary demarcation could be worth experimenting with in production systems.
The paper also addresses a practical challenge: SID shift in transfer learning. When adapting to new domains or datasets, the distribution of semantic IDs may change. Their solution combines SID with keywords (SID + keyword), which provides robustness and maintains semantic grounding during transfer.
Another interesting point is regarding their implementation of RQ-KMeans, which is essentially running FAISS on a large batch of data and directly update the codebook’s parameter with the centroids computed from FAISS. I asked the author in thisissue and get confirmed that they only trained on subset of all their inventory, which is different from what I have been doing in my experiment.
Pre-training Strategy
The pre-training follows a two-stage approach:
Stage 1 (Item Alignment): As mentioned above, this stage focuses on aligning semantic IDs with the LLM’s representation space.
Stage 2 (Sequence Modeling): The model is trained on the full corpus of user behavior sequences. Critically, they mix in general reasoning open source dataset to prevent catastrophic forgetting of the base LLM’s language capabilities. This ensures the model retains its linguistic understanding while learning recommendation-specific patterns.
Post-training: SFT, Knowledge Distillation, and RL
The post-training phase employs three complementary techniques:
1. Multi-task Supervised Fine-tuning (SFT) Complex instruction-response pairs are constructed to simulate real-world recommendation scenarios and user interaction trajectories. This helps the model understand diverse recommendation contexts.
2. On-policy Knowledge Distillation This is where things get interesting. Given a prompt, the student model generates a recommendation trajectory, and the teacher model (Qwen3 base) provides rewards using reverse KL divergence. Policy gradient methods are then used for optimization.
A technical challenge arises from vocabulary mismatch: the teacher model doesn’t have SID tokens in its vocabulary. The paper employs special techniques to bridge this gap, ensuring effective knowledge transfer despite the vocabulary discrepancy.
3. Reinforcement Learning with GRPO GRPO (Group Relative Policy Optimization) addresses two key issues in SFT:
- Exposure bias: The distribution mismatch between training (teacher forcing) and inference (autoregressive generation)
- Distinguishing near-miss vs. irrelevant recommendations: Not all incorrect recommendations are equally wrong; GRPO helps the model learn this nuance
Feature Engineering Details
An often-overlooked detail is how user profiles are represented. OpenOneRec directly incorporates numeric features into prompts, for example: “她关注的博主类型有:[其他] 占 47.58%,[颜值] 占 16.52%”. This is also commonly known as hard prompting which is widely used in llm4rec.
OxygenRec: JD’s Advanced Generative Recommendation System
OxygenRec from JD shares conceptual similarities with OpenOneRec but introduces several novel techniques, particularly in semantic ID generation and training infrastructure.
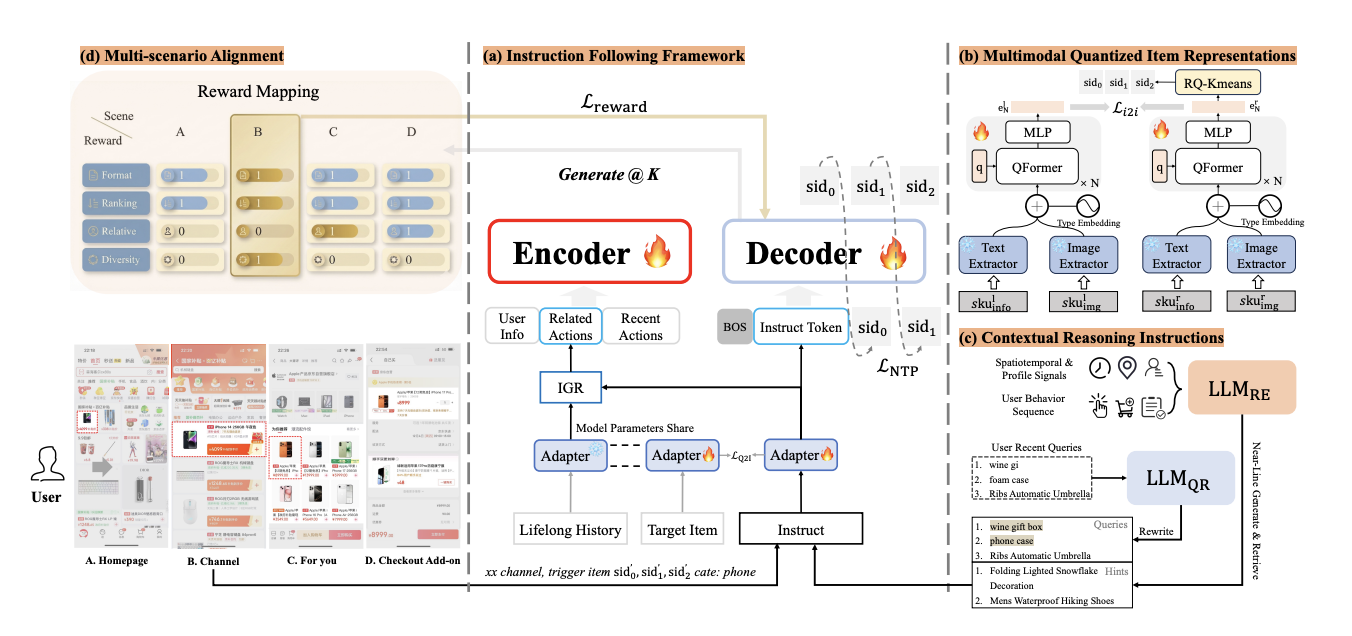
Enhanced Semantic ID Generation
The key innovation here is the use of a Q-Former architecture for multi-modal fusion. Rather than simply concatenating text and image embeddings, OxygenRec applies contrastive learning to align these modalities before RQ-KMeans encoding.
Their ablation study reveals important findings:
- Text embeddings alone perform poorly
- Multi-modal embeddings are essential
- Complex fusion with contrastive learning produces the best results after collaborative filtering
This suggests that simple concatenation of modalities is insufficient—proper alignment through contrastive learning is crucial for high-quality semantic IDs.
Pre-training Innovations
OxygenRec introduces two notable techniques during pre-training which mimic the Thinking, Fast and Slow pattern described by Daniel Kahneman.
1. Contextual Reasoning Instructions (CRI) Inspired by Google’s work on LLM-generated user profiles, OxygenRec generates contextual reasoning instructions based on:
- User profile signals
- Behavior sequences
- Recent search history
These natural language instructions are encoded through an adapter into the same embedding space as items, providing rich contextual signals.
2. Item-Guided Retrieval (IGR) IGR adapts the GRU architecture from SIM (Search-based Interest Model), but replaces the target item with the contextual reasoning instruction. An adapter performs co-training to align item representations and CRI text representations in the same space.
The Q2I (Query-to-Item) alignment uses a contrastive learning approach similar to batch InfoNCE. During training, target item representations are paired with their corresponding CRI for contrastive learning, ensuring semantic consistency.
Post-training with Soft Adaptive Policy Optimization
For reinforcement learning, OxygenRec proposes Soft Adaptive Group Clip Policy Optimization (SAG-CPO). The key insight is using a soft adaptive function to compute importance weights for positive and negative samples, which modulates the advantage estimation. This allows for more nuanced credit assignment compared to standard PPO or GRPO.
Infrastructure Optimizations
OxygenRec makes significant contributions on the systems side, which is often overlooked in research papers:
Training Infrastructure:
- Custom framework built on PyTorch with pipeline parallelism (PP) and tensor parallelism (TP)
- Optimizations for distributed sparse operations
- Claims 1.1-2.4× speedup over OSS embedding solutions (likely compared to TorchRec)
- Techniques include HBM-Cache, multi-stage pipeline, and dual buffering
Attention Kernels:
- Implementation using CUTLASS and TileLang for flexible mask configurations
- 1.7× faster than FlexAttention
- 3× faster than torch.compile
Inference Optimizations:
- Custom GR (Generative Recommendation) server based on xLLM
- Beam Sample Kernel: Efficiently combines top-k selection with nucleus/multinomial sampling
- Prefix-constrained decoding: Ensures generated sequences respect structural constraints
These inference techniques are particularly relevant for production deployment and could be valuable references for other generative recommendation systems.
Efficient Sequential Recommendation for Long-Term User Interest
This Meta paper tackles a fundamental challenge in sequential recommendation: efficiently modeling long user histories without exploding computational costs.
Core Idea: Learnable Compression Tokens
The key insight is elegant: use learnable tokens to compress information from each segment of the user’s history. These tokens act as “memory anchors” that summarize segments, enabling efficient reuse through KV caching during inference.
Architecture Design
Sequence Segmentation: User sequences are divided into segments, with a learnable token appended to the end of each segment (likely placed at the end rather than the beginning to leverage attention sink phenomena).
Attention Masking: The masking strategy is carefully designed:
- Each token attends only to preceding tokens within its own segment
- Each token also attends to learnable tokens from all previous segments
This creates a hierarchical attention pattern where learnable tokens act as bottlenecks for cross-segment information flow.
Efficiency Gains: During training, the overhead is minimal. During inference, the learnable tokens (and their KV cache) can be reused directly, avoiding redundant computation over long histories.
Experimental Observations
The paper uses the MerRec dataset, which could be valuable for benchmarking. However, one finding somewhat undermines the core motivation: using a single segment performs better than multiple segments. This suggests that the compression mechanism may introduce information loss that outweighs the efficiency benefits, at least in their experimental setup.
This raises interesting questions about when and where such compression techniques are truly beneficial—perhaps only when sequences are extremely long or computational budgets are severely constrained.
Promise: Process Reward Models for Generative Recommendation
Kuaishou’s Promise paper introduces test-time optimization for generative recommenders, addressing a critical challenge in hierarchical semantic ID generation.
The Semantic Drift Problem
Promise identifies a key difference between LLM text generation and generative recommendation:
In standard LLM generation: Tokens are relatively independent; an error in one token has limited downstream impact.
In hierarchical SID generation: Semantic IDs have hierarchical structure. If the model predicts the wrong prefix (e.g., wrong category), all subsequent tokens will be catastrophically wrong.
Models like OneRec train with teacher forcing (using ground-truth previous tokens), but at inference time they must use their own predictions. This train-test mismatch is a classic off-policy problem: the model never receives feedback on sequences it generates itself during training. With the hierarchical information baked in SID, this creates severe semantic drift problem during inference.
Solution: Process Reward Model (PRM)
Promise introduces a process reward model to evaluate partial sequences during generation:
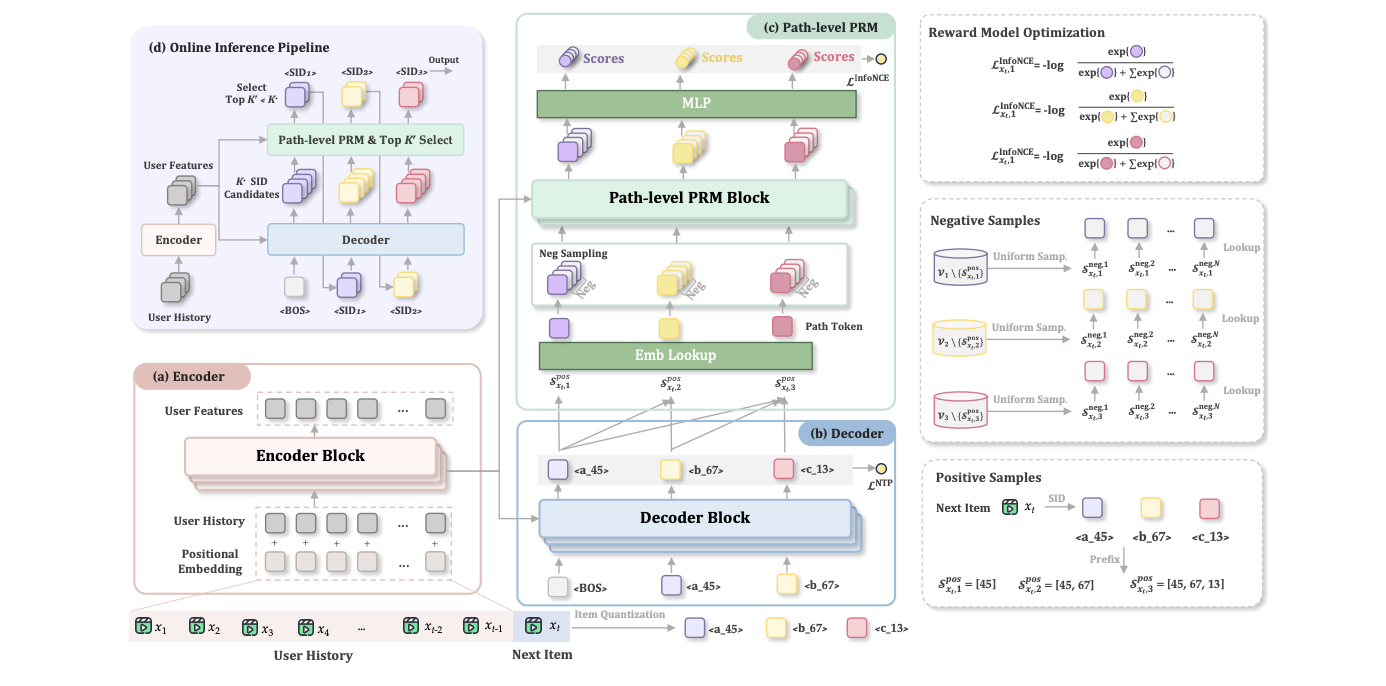
Training the PRM:
- Positive samples: Ground-truth SID token sequences
- Negative samples: Sampled from all valid SIDs
- Objective: InfoNCE contrastive loss
Architecture: The PRM design is clever and efficient:
- A separate embedding lookup table converts SIDs to embeddings (used as queries)
- Reuse the GR model’s encoder output as keys/values
- Cross-attention between SID embeddings and encoder outputs
- Final MLP layer produces sequence scores
This architecture is reminiscent of path retrieval mechanisms and enables efficient scoring without full model forward passes.
Inference Algorithm:

While the pseudocode appears complex, the core idea is straightforward:
- Perform beam search to generate candidate sequences
- Invoke the reward model to score partial paths
- Prune low-scoring paths
- Continue generation with remaining high-quality candidates
This is essentially test-time scaling for recommendation—using compute during inference to improve generation quality.
New Evaluation Metric: Hierarchical Recall
Promise proposes Hierarchical Recall, which measures the recall at each level of the prefix during beam search. This provides fine-grained insight into where the model succeeds or fails in the hierarchical generation process. This metric could be valuable for debugging and analyzing other hierarchical generation systems.
Key Takeaways and Future Directions
These four papers collectively illustrate the rapid maturation of LLM-based recommendation systems:
Semantic IDs are crucial: Multi-modal fusion with proper contrastive learning (as in OxygenRec) produces superior semantic representations compared to simple concatenation or single-modality approaches.
Multi-stage training is standard: The pattern of item alignment → sequence pre-training → SFT → RL has emerged as a robust framework.
Infrastructure matters: OxygenRec’s emphasis on systems optimization (training and inference) reminds us that research innovations must be complemented by engineering excellence for production deployment.
If you find this post helpful, feel free to scan the QR code below to support me and treat me to a cup of coffee

Comments powered by Disqus.